网页爬虫 - python 爬取网站 并解析非json内容
问题描述
小弟刚学会获得json的内容,但今天爬的网站返回的并不是json内容 并且会有一个随机数的生成在每次请求链接的后面
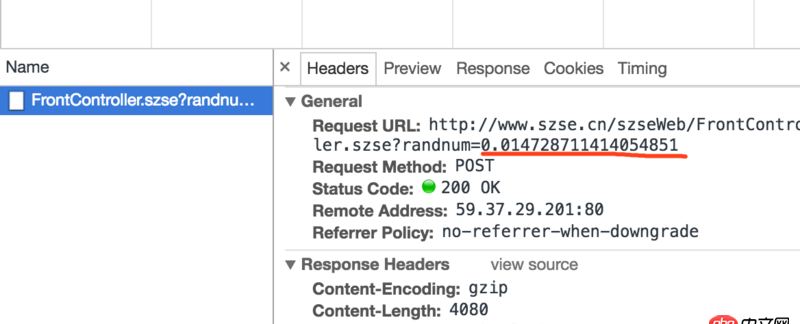
不知道会不会影响我要爬的内容
需要获得内容是下图中间的内容
 网站链接 http://www.szse.cn/main/discl...
网站链接 http://www.szse.cn/main/discl...
我自己尝试的代码:
import requestsdir = ’/Users/S1Lence/Desktop/new_html/szse/许可类重组问询函’headers = {’Host’: ’www.szse.cn’, ’Referer’: ’http://www.szse.cn/main/disclosure/jgxxgk/wxhj/’, ’User-Agent’: ’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.109 Safari/537.36’ }payload= {’ACTIONID’: ’7’, ’AJAX’: ’AJAX-TRUE’, ’CATALOGID’: ’main_wxhj’, ’TABKEY’: ’tab1’, ’selecthjlb’: ’许可类重组问询函’, ’tab1PAGENO’: ’1’, ’tab1PAGECOUNT’: ’7’, ’tab1RECORDCOUNT’: ’63’, ’REPORT_ACTION’: ’navigate’}res = requests.post(’http://www.szse.cn/szseWeb/FrontControllere’, data=payload)print(res.text)
输出的内容并不是我想要的 求解应该怎么爬
问题解答
回答1:把他的header信息拷过来用。。
回答2:你post的url地址写错了,应该是
http://www.szse.cn/szseWeb/FrontController.szse
相关文章:
1. linux - 【已解决】fabric部署的Python项目Apache启动之后提示403Forbidden该如何解决?2. python - (初学者)代码运行不起来,求指导,谢谢!3. mysql里的大表用mycat做水平拆分,是不是要先手动分好,再配置mycat4. window下mysql中文乱码怎么解决??5. python - flask sqlalchemy signals 无法触发6. nginx - pip install python库报错7. python - 获取到的数据生成新的mysql表8. python的文件读写问题?9. javascript - js 对中文进行MD5加密和python结果不一样。10. 为什么python中实例检查推荐使用isinstance而不是type?

 网公网安备
网公网安备