文章详情页
python - 用sklearn求大文本的tfidf特征?
浏览:96日期:2022-06-27 15:50:07
问题描述
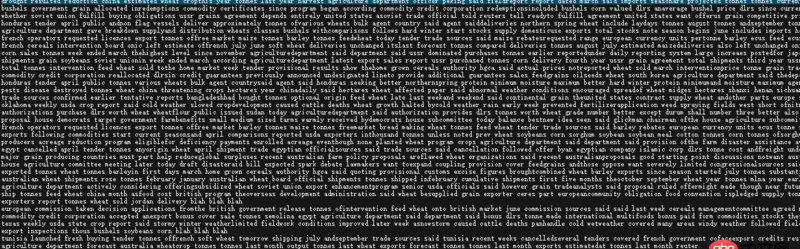 上面的数据是从reuters数据集中取得7303个训练集,用sklearn对其取tfidf特征,得到的结果都是0,这是怎么回事?
上面的数据是从reuters数据集中取得7303个训练集,用sklearn对其取tfidf特征,得到的结果都是0,这是怎么回事?
当我从这些数据中取一部分时,对于这些少部分数据能够得到正确的tfidf结果。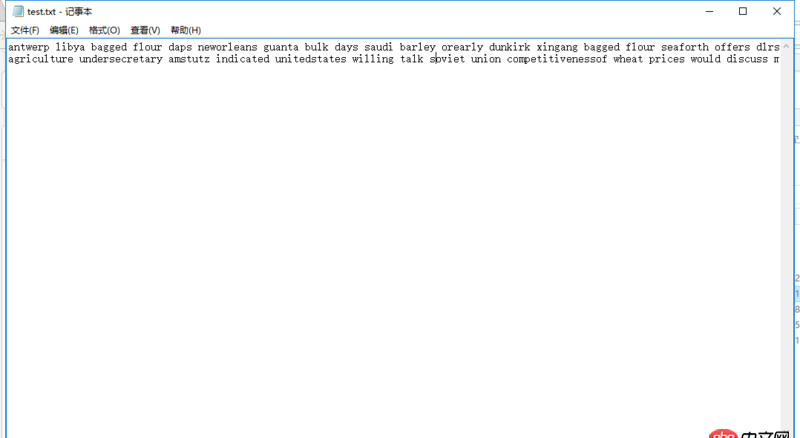

问题解答
回答1:上代码,可能是你精度太低或者min_count导致的
比如词频是1,总词数1e9,对应的tf就是1e-9,被忽略了。
相关文章:
1. html5 - 使用angular中,图片上传功能中选择多张图片是怎么实现的?有什么好的思路吗?2. javascript - jquery选择的dom元素如何更新?3. .......4. python - Django问题 ’WSGIRequest’ object has no attribute ’user’5. 数据库 - mysql boolean型无法插入true6. centos - apache配置django报错:cannot be loaded as Python modules7. python - flask jinjia2 中怎么定义嵌套变量8. javascript - URL中有#号如何来获取参数啊? nodejs9. MYSQL 的 SELECT 语句中如何做到判断字段为空10. javascript - H5页面无缝轮播
排行榜
 网公网安备
网公网安备