Python爬取网页requests乱码
问题描述
**之前有在裁判文书上爬取数据,这段时间重新运行爬虫后发现无法获取网页数据,找了一下发现requests网页源码返回的是乱码**
(如下截取一部分返回的数据:<meta http-equiv='Content-Type' content='text/html; charset=utf-8'><meta ) 不知道是不是网站对网页内容进行了加密,请问如何解决这个问题?谢谢!
不知道是不是网站对网页内容进行了加密,请问如何解决这个问题?谢谢!
截取部分程序源码:
headers = {’User-Agent’: ’Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36’,’Accept’: ’text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’,’Accept-Language’: ’zh-TW,zh;q=0.8,en-US;q=0.6,en;q=0.4’,’Accept-Encoding’: ’gzip, deflate’,’Connection’: ’keep-alive’,’Content-Type’: ’text/html; charset=utf-8’}html = requests.post(’http://wenshu.court.gov.cn/List/ListContent’, data=data, headers=headers)print(html.text)
但是在审查元素里返回应该返回的数据,请问这哪里出现了问题?
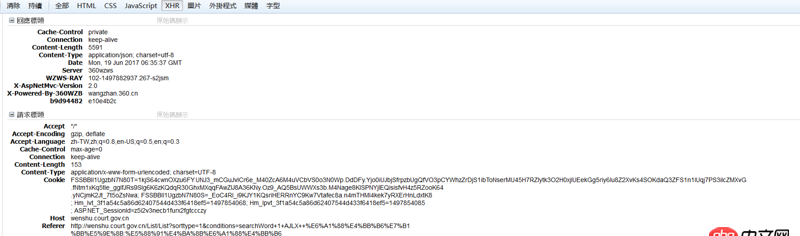
之前程序正常运行时返回的数据是这样的:
问题解答
回答1:ajax 加载的结果页面,如果在 network 里获取不到类似 json 的反馈结果。就使用PHANTOMJS来模拟加载。然后匹配爬取。
回答2:你的 html 对象使用的编码不对,加入一行 html.encoding = html.apparent_encoding根据实际获取的 text 推测编码,重新解码。
回答3:如果你愿意去钻,给你个参考地址:http://www.qingpingshan.com/j...
回答4:print html.content
相关文章:
1. docker绑定了nginx端口 外部访问不到2. docker-compose 为何找不到配置文件?3. boot2docker无法启动4. dockerfile - [docker build image失败- npm install]5. docker网络端口映射,没有方便点的操作方法么?6. Docker for Mac 创建的dnsmasq容器连不上/不工作的问题7. mysql优化 - mysql 多表联合查询,求一个效率最高的查询8. angular.js使用$resource服务把数据存入mongodb的问题。9. 我何时应该在Java中使用JFrame.add(component)和JFrame.getContentPane()。add(component)10. html5 - 如何让H5页面在手机浏览器里和微信全屏显示

 网公网安备
网公网安备