网页爬虫 - python 爬虫怎么处理json内容
问题描述
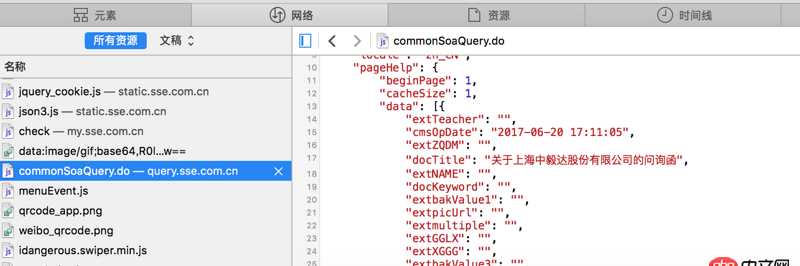
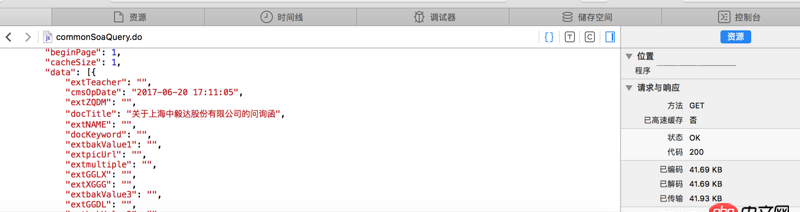
看不清的话 网站地址是http://www.sse.com.cn/disclos...红字是我需要的内容 但是我提取不出来求教怎么操作
问题解答
回答1:import requestsurl = ’http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5’headers = { ’Referer’:’http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/’, ’User-Agent’:’Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36’}r = requests.get(url, headers=headers)print r.json()[’result’]回答2:
import requestsurl = ’http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5&_=1498029409382’session = requests.session()session.headers.update({ ’Referer’: ’http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/’, ’User-Agent’: ’Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36’})result = session.get(url).json()print result
相关文章:
1. angular.js - 不适用其他构建工具,怎么搭建angular1项目2. python如何不改动文件的情况下修改文件的 修改日期3. mysql - 一个表和多个表是多对多的关系,该怎么设计4. javascript - git clone 下来的项目 想在本地运行 npm run install 报错5. mysql主从 - 请教下mysql 主动-被动模式的双主配置 和 主从配置在应用上有什么区别?6. android-studio - Android 动态壁纸LayoutParams问题7. 主从备份 - 跪求mysql 高可用主从方案8. angular.js - 三大框架react、vue、angular的分析9. python 如何实现PHP替换图片 链接10. python - django 里自定义的 login 方法,如何使用 login_required()
 网公网安备
网公网安备