python小白,问一个关于可变类型和不可变类型底层的问题
问题描述
第一段代码:
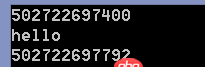
a = 'hello' #定义一个字符串的变量print(id(a)) #第一次的地址print(a) #a = helloa = a.upper() # 单纯的a.upper() 执行过后,无法存储到a本身,必须得重新赋值给a 换句话说,a在被upper之后,重新指向了一个新的地址print(id(a)) #第二次的地址print(a)
第一段代码执行结果:
第二段代码:
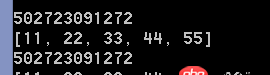
b = [11,22,33,44,55] #定义一个列表的变量print(id(b)) #第一次的地址print(b) #b = [11,22,33,44,55]b.append(99) #单纯的b.append()执行过后,不需要存储到b,因为b已经被更改print(id(b)) #检查第一次的地址print(b) #发现在第一次地址当中,b已经改变#b = b.append(99) #如果将修改b这个行为赋值到b#print(id(b)) #检查地址,发现已经变更#print(b) #检查b的值,发现已经变更。b的值为none 因为b.append(99)本身的返回值为none#[***列表为可修改变量,因此修改完之后,地址跟原来的一样。反而是如果像修改字符串那样重新赋值,变得不可行。原因在于append语句本身并不返回值。***]#字符串赋值之后放在内存一个地址,这个地址上面的字符串是无法更改的,只能重新做一个新的字符串,然后改变变量的指向位置。#而列表赋值之后存在一个内存的地址,这个列表里面的值是可以直接修改的。不需要重新做一个新的列表,然后改变变量的指向位置。
第二段代码执行结果:
在学python的过程当中被告知,字符串是属于不可变类型,列表属于可变类型。也就是说,如果我要改字符串,我其实是重新做了一个新的字符串,放在内存的新的地址中,原来的地方那个字符串还是原来的老样子。如第一段代码所示。而列表不一样,列表可以在原来的内存地址上直接修改。如第二段代码所示。我的问题:可变类型和不可变类型的根本区别在哪里?为什么会出现这种区别?为什么第一段代码里,a要想改变,必须改变地址,第二段代码里b可以不变地址的情况下直接修改列表的值。这里面的底层逻辑是什么?我猜想,是不是意味着列表这个东西本身,也其实是某一个一堆值得集合体,它仅仅只是反映了一个集合体本身,把一堆值指向了这一个地方而已,所以才是可以修改的?不知道我表达有没有清楚。我只是对这个东西很好奇,也就是说,追根究底列表到底是个什么东西,为什么他是可以直接改的?而字符串没法改。往再底层深入之后,他们俩到底是啥?
问题解答
回答1:其实对象可变不可变, 对py, 都是内部实现的问题, 如果我修改相应的方法, 将其写回到本身, 这样也能模仿出可变的现象, 就小小类似tuple和list的关系,既然想了解底层, 那就直接看源码吧:这是字符串的upper()
static PyObject *string_upper(PyStringObject *self){ char *s; Py_ssize_t i, n = PyString_GET_SIZE(self); # 取出字符串对象中字符串的长度 PyObject *newobj; newobj = PyString_FromStringAndSize(NULL, n); # 可以理解成申请内存空间 if (!newobj)return NULL; s = PyString_AS_STRING(newobj); # 从newobj对象取出具体字符串指针 Py_MEMCPY(s, PyString_AS_STRING(self), n); # 拷贝旧的字符串 for (i = 0; i < n; i++) {int c = Py_CHARMASK(s[i]);if (islower(c)) s[i] = _toupper(c); # 修改对应指针位置上的内容 } return newobj; # 返回新字符串对象 (区分字符串对象和里面字符串的指针)}
这是列表的append
intPyList_Append(PyObject *op, PyObject *newitem){ if (PyList_Check(op) && (newitem != NULL))return app1((PyListObject *)op, newitem); PyErr_BadInternalCall(); return -1;}static intapp1(PyListObject *self, PyObject *v){ Py_ssize_t n = PyList_GET_SIZE(self); assert (v != NULL); if (n == PY_SSIZE_T_MAX) {PyErr_SetString(PyExc_OverflowError, 'cannot add more objects to list');return -1; } if (list_resize(self, n+1) == -1)return -1; Py_INCREF(v); PyList_SET_ITEM(self, n, v); # 因为列表是头和和成员分开的, 所以直接将新成员追加在原来的成员数组后面, 长度变化通过resize实现 return 0;}回答2:
python字符串有cache的,如果两个相同的字符串在不同的变量a,b,他们的id(a), id(b)是一样的.但如果当a, b的引用为0是,就会自动销毁对象.
楼主的例子:
a = a.upper()
a的变量内容已经变化,不一样了,旧的内容没有了引用,垃圾回收销毁对象.b是列表,是可变的,可以再申请内存.同时,b有内容引用,不会被销毁.
回答3:往再底层深入,就去看python的C源码呗~
可不可变,是python语言规定的。
不可变类型 没有提供修改对象自身的方法,而 可变类型 提供了这些方法。就这些差别,没啥神秘的。
回答4:从硬件角度说,提供给用户的接口是按照规定设定好的,操作内存就是固定的方式,不存在可变和不可变。往上,就是操作系统层,对硬件api进行了大量的封装,使用户操作变得丰富,对于python解释器是使用c语言编写的,使用python时只是使用了python的语用,编写代码,然后交给解释器去执行.在上面的前提下,来解释当前问题,python的可变和不可变是python创建者规定的,实现这些规定的方式可能就是调用了不同的底层api,或者是不同底层api相互组合来实现的。将这些规定以python语用的形式提供给用户使用,最后还是编译成0,1去让计算机执行。对于用户来说,可变和不可变对象是语言提供的一个特性,可以完成一些功能,但是对于计算机其实是没区别的。
相关文章:
 网公网安备
网公网安备