文章详情页
python - 使用scrapy框架爬百度图片被墙
浏览:78日期:2022-06-30 14:19:37
问题描述
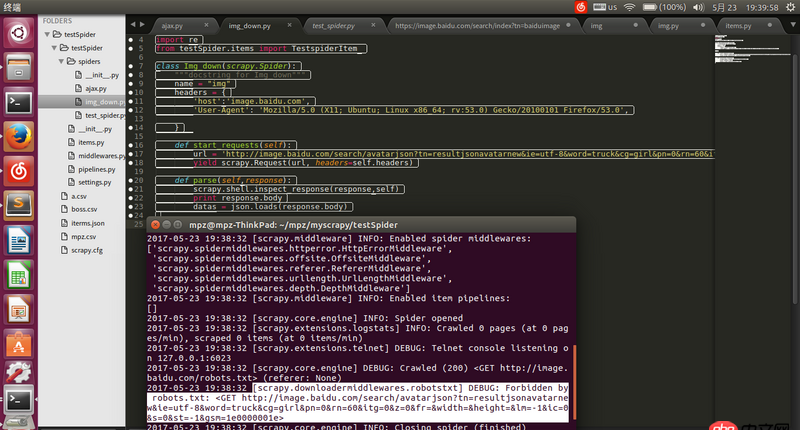
请求地址url是通过firefox查看得到的json的地址,用浏览器可以打开,但是用scrapy爬的时候就被ban了求解决办法。
https://image.baidu.com/searc...
问题解答
回答1:在 settings.py 将 ROBOTSTXT_OBEY = False 试试。
回答2:不要加hearders试试
回答3:赞成楼上,如果还会被墙。可采用scrapy+selenium+phantomjs的方式。
相关文章:
1. python - (初学者)代码运行不起来,求指导,谢谢!2. 为什么python中实例检查推荐使用isinstance而不是type?3. mysql里的大表用mycat做水平拆分,是不是要先手动分好,再配置mycat4. window下mysql中文乱码怎么解决??5. sass - gem install compass 使用淘宝 Ruby 安装失败,出现 4046. html5 - H5 SSE的本质是什么?7. javascript - h5上的手机号默认没有识别8. python - 获取到的数据生成新的mysql表9. python的文件读写问题?10. javascript - js 对中文进行MD5加密和python结果不一样。
排行榜
 网公网安备
网公网安备