python - 图片爬虫时候遇到问题 urllib.request.urlretrieve 下载到指定文件夹不成功?
问题描述
如果下载到D盘也是没有问题的,下载到我建立的目录下就有问题(主要是我想在D盘建立以URL这个问号前面的数字为名字的目录如(http://v.yupoo.com/photos/196...’)中的46975340就是不行,因为有很多链接,每个链接的这个数字不同,我想用这个数字作为文件夹的名字,存放这个链接下载下来的图片)源码如下: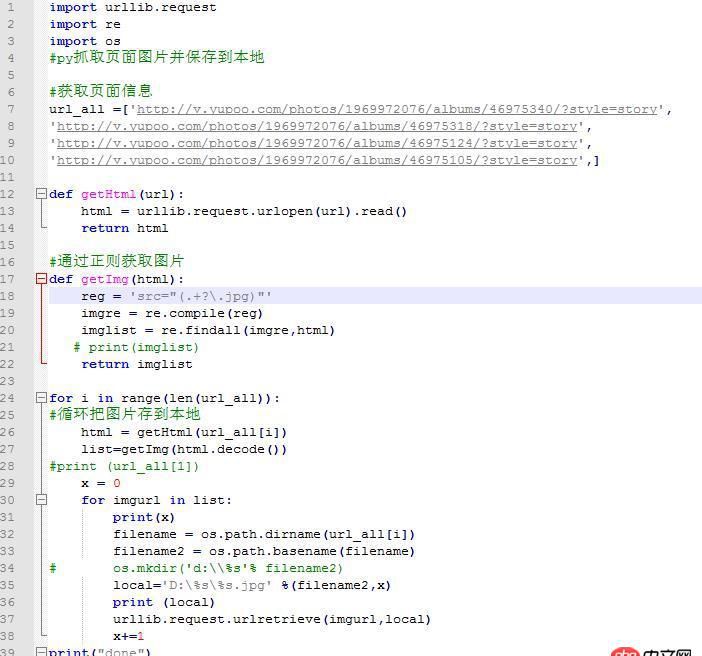 import urllib.requestimport reimport os
import urllib.requestimport reimport os
url_all =[’http://v.yupoo.com/photos/196...’,’http://v.yupoo.com/photos/196...’,’http://v.yupoo.com/photos/196...’,’http://v.yupoo.com/photos/196...’,]
def getHtml(url):
html = urllib.request.urlopen(url).read()return html通过正则获取图片
def getImg(html):
reg = ’src='https://www.haobala.com/wenda/(.+?.jpg)'’imgre = re.compile(reg)imglist = re.findall(imgre,html)
# print(imglist)
return imglist
for i in range(len(url_all)):
循环把图片存到本地html = getHtml(url_all[i])list=getImg(html.decode())print (url_all[1])
x = 0for imgurl in list: print(x) filename = os.path.dirname(url_all[i])filename2 = os.path.basename(filename)os.mkdir(’d:%s’% filename2)
local=’D:%s%s.jpg’ %(filename2,x) print (local) urllib.request.urlretrieve(imgurl,local) x+=1print('done')
执行报错:(win10的64位系统,python3.6)
File 'C:Python36liburllibrequest.py', line 258, in urlretrieve
tfp = open(filename, ’wb’)
FileNotFoundError: [Errno 2] No such file or directory: ’d:469753400.jpg’经测试最后一句这么写是可以输出的: urllib.request.urlretrieve(imgurl,’d:%s.jpg’% str(i*10+x))
经测试 前面两句都没有问题,加第三句: local=’d:%s%s.jpg’ %(filename2,x)
print (local)
urllib.request.urlretrieve(imgurl,local)
报错信息如下: (和上面一样)
File 'C:Python36liburllibrequest.py', line 258, in urlretrieve
tfp = open(filename, ’wb’)
FileNotFoundError: [Errno 2] No such file or directory: ’d:469753400.jpg’
请教给位大大,这个路径到底有什么问题没有?应该怎么写。
问题解答
回答1:在保存之前,先检查一下目录是否存在,不存在则建立
if not os.path.exists(file_path): os.mkdir(file_path)
相关文章:
1. docker api 开发的端口怎么获取?2. debian - docker依赖的aufs-tools源码哪里可以找到啊?3. 关docker hub上有些镜像的tag被标记““This image has vulnerabilities””4. 我何时应该在Java中使用JFrame.add(component)和JFrame.getContentPane()。add(component)5. golang - 用IDE看docker源码时的小问题6. 关于docker下的nginx压力测试7. nignx - docker内nginx 80端口被占用8. 对html实现监测 发现不对9. python - 使用pandas的resample报错10. mac连接阿里云docker集群,已经卡了2天了,求问?
 网公网安备
网公网安备