文章详情页
python - pyspider 定时爬取问题
浏览:93日期:2022-07-14 10:37:31
问题描述

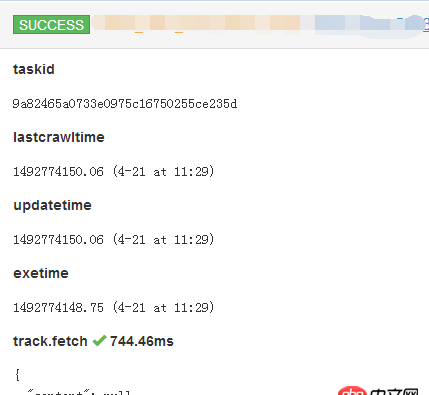

在写爬虫的时候,发现 在代码中设置了 every 之后,21号爬取了一次之后,今天看 result 没有更新,那个 lastcrawltime 依旧是 21号的。请问是不是我的参数设置的不正确?

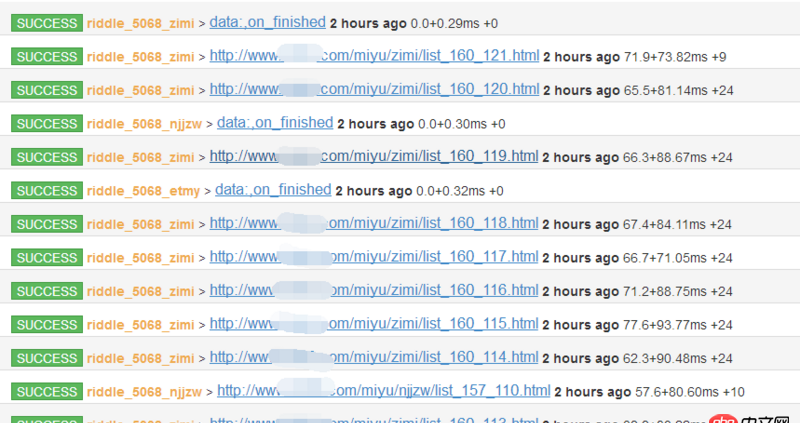
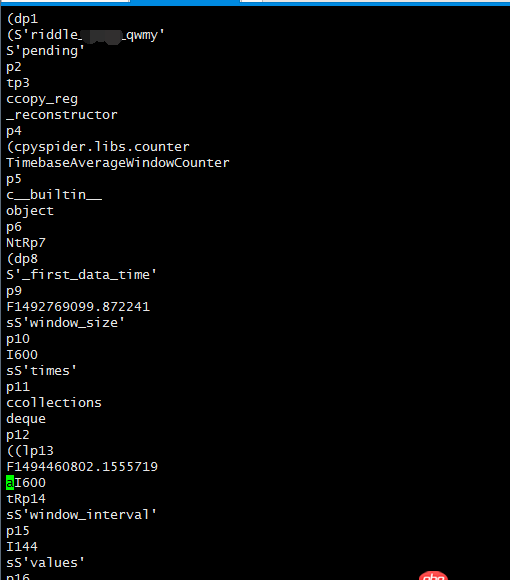
问题解答
回答1:你贴的这个 task 的图,是什么任务的?
贴的是 detail_page 的任务的
题主给 index_page 设置了小于 cronjob 间隔的时间。然而没有给 detail_page 设置。这样 detail_page 是不会被重新调度的
project 队列状态,最近活动任务是怎样的?
回答2:有可能是 every 和 age 不匹配。如果 age 没问题的话,说实话这属于疑难杂症了,我也经常遇到,我都是去 taskdb 把相应的表清空,然后重启 pyspider 重新运行项目
相关文章:
1. mysql优化 - mysql count(id)查询速度如何优化?2. javascript - 微信网页开发从菜单进入页面后,按返回键没有关闭浏览器而是刷新当前页面,求解决?3. mysql - 如何在数据库里优化 汉明距离 查询?4. mysql每隔10来秒就有一次7、8MB的写入5. windows docker-machine port6. mysql 查询所有评论以及回复7. linux - 为什么我在mysql的my.cnf下找不到bind-address?8. python - flask jinjia2 中怎么定义嵌套变量9. python - 如何使用websocket在网页上动态示实时数据的折线图?10. linux - python -m参数
排行榜

 网公网安备
网公网安备