python - 用urllib抓取网页上的下载链接,目标文件是xls形式,但发现抓下来的xls是空表,里面只有一句报错信息,求帮助。
问题描述
想用urllib抓取上交所股票列表的xls下载链接,如下图红色小框:
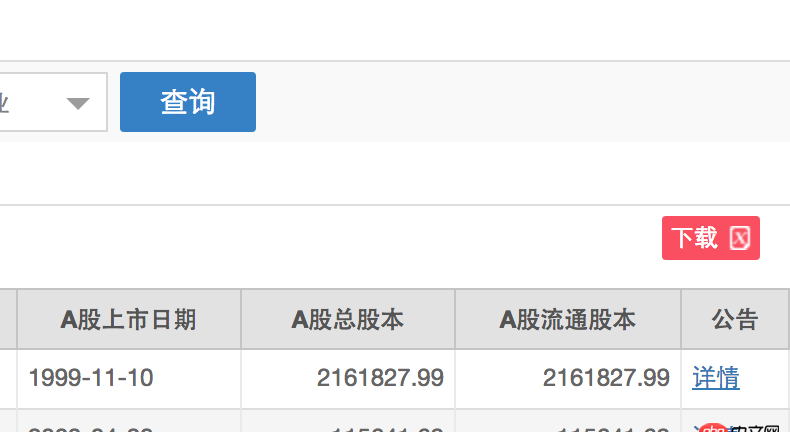
发现抓下来的xls只有报错信息:
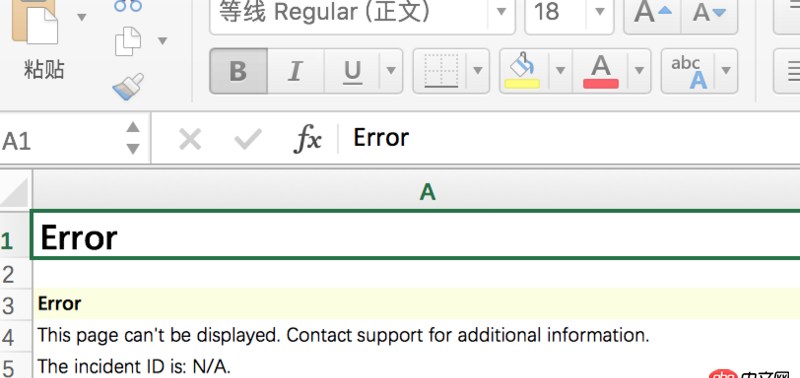
请问要怎样才能把有内容的xls抓下来?
代码如下
from urllib import requestfrom datetime import datetime# -*- coding:utf-8 -*-url = ’http://query.sse.com.cn/security/stock/downloadStockListFile.do?’ ’csrcCode=&stockCode=&areaName=&stockType=1’myheaders = [(’User - Agent’, ’Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13’ ’ (KHTML, like Gecko) Version/3.1 Safari/525.13’),]opener = request.build_opener()opener.addheaders = myheadersrequest.install_opener(opener)local = '/Users/Mty/Downloads/data/' + str(datetime.now().date()) + ' .xls'request.urlretrieve(url, local)
问题解答
回答1:可以在标红线的url上看到返回的公司信息,剩下的就是模拟浏览器请求这个url了,request header中的refer一定不能省略,不然会报403
记住要模拟 refer 这一项的值。
http://blog.csdn.net/ssshen14...这个是已有的解决方案
回答2:查看cookie,referer
![css3 - [CSS] 动画效果 3D翻转bug](http://www.haobala.com/attached/image/news/202304/110831f073.png)
 网公网安备
网公网安备