文章详情页
python - scrapy运行爬虫一打开就关闭了没有爬取到数据是什么原因
浏览:51日期:2022-08-05 15:09:38
问题描述
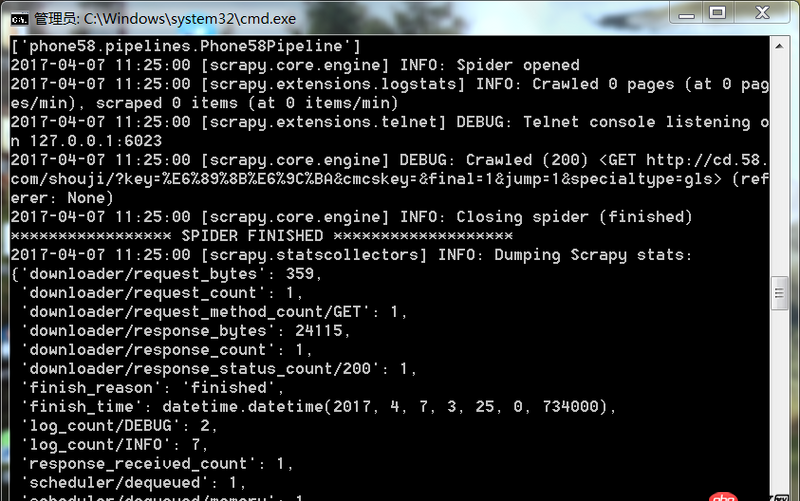
爬虫运行遇到如此问题要怎么解决
问题解答
回答1:很可能是你的爬取规则出错,也就是说你的spider代码里面的xpath(或者其他解析工具)的规则错误。导致没爬取到。你可以把网址print出来,看看是不是[]
相关文章:
1. python如何不改动文件的情况下修改文件的 修改日期2. angular.js - 不适用其他构建工具,怎么搭建angular1项目3. angular.js - Angular路由和express路由的组合使用问题4. python - django 里自定义的 login 方法,如何使用 login_required()5. java8中,逻辑与 & 符号用在接口类上代表什么意思6. mysql优化 - mysql count(id)查询速度如何优化?7. mysql主从 - 请教下mysql 主动-被动模式的双主配置 和 主从配置在应用上有什么区别?8. 主从备份 - 跪求mysql 高可用主从方案9. node.js - node_moduls太多了10. python - 关于ACK标志位的TCP端口扫描的疑惑?
排行榜

 网公网安备
网公网安备