python - mongodb 去重
问题描述
爬取了一个用户的论坛数据,但是这个数据库中有重复的数据,于是我想把重复的数据项给去掉。数据库的结构如下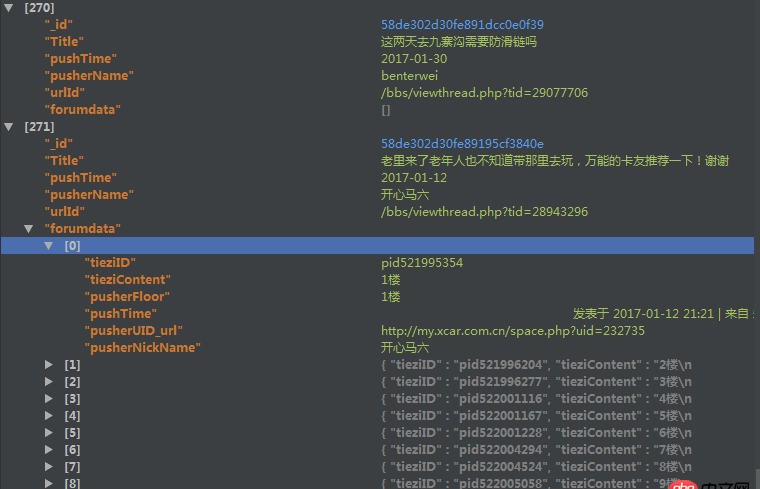
里边的forundata是这个帖子的每个楼层的发言情况。但是因为帖子爬取的时候有可能重复爬取了,我现在想根据里边的urlId来去掉重复的帖子,但是在去除的时候我想保留帖子的forumdata(是list类型)字段中列表长度最长的那个。用mongodb的distinct方法只能返回重复了的帖子urlId,都不返回重复帖子的其他信息,我没法定位。。。假如重复50000个,那么我还要根据这些返回的urlId去数据库中find之后再在mongodb外边代码修改吗?可是即使这样,我发现运行的时候速度特别慢。之后我用了group函数,但是在reduce函数中,因为我要比较forumdata函数的大小,然后决定保留哪一个forumdata,所以我要传入forumdata,但是有些forumdata大小超过了16M,导致报错,然后这样有什么解决办法吗?或者用第三种方法,用Map_reduce,但是我在map-reduce中的reduce传入的forumdata大小限制竟然是8M,还是报错。。。
代码如下group的代码:
reducefunc=Code( ’function(doc,prev){’ ’if (prev==null){’ ’prev=doc’ ’}’ ’if(prev!=null){’ ’if (doc.forumdata.lenth>prev.forumdata.lenth){’ ’prev=doc’ ’}’ ’}’ ’}’)
map_reduce的代码:
reducefunc=Code( ’function(urlId,forumdata){’ ’if(forumdata.lenth=1){’ ’return forumdata[0];’ ’}’ ’else if(forumdata[0].lenth>forumdata[1].lenth){’ ’return forumdata[0];’ ’}’ ’else{’ ’return forumdata[1]}’ ’}’)mapfunc=Code( ’function(){’ ’emit(this.urlId,this.forumdata)’ ’}’)
望各位高手帮我看看这个问题该怎么解决,三个方案中随便各一个就好,或者重新帮我分析一个思路,感激不尽。鄙人新人,问题有描述不到位的地方请提出来,我会立即补充完善。
问题解答
回答1:如果这个问题还没有解决,不妨参考下面的想法:
1、MongoDB中推荐使用aggregation,而不推荐使用map-reduce;
2、您的需求中,很重要的一点是获取Forumdata的长度:数组的长度,从而找到数组长度最长的document。您原文说Forumdata是列表(在MongoDB中应该是数组);MongoDB提供了$size运算符号取得数组的大小。
请参考下面的栗子:
> db.data.aggregate([ {$project : { '_id' : 1, 'name' : 1, 'num' : 1, 'length' : { $size : '$num'}}}]){ '_id' : ObjectId('58e631a5f21e5d618900ec20'), 'name' : 'a', 'num' : [ 12, 123, 22, 34, 1 ], 'length' : 5 }{ '_id' : ObjectId('58e631a5f21e5d618900ec21'), 'name' : 'b', 'num' : [ 42, 22 ], 'length' : 2 }{ '_id' : ObjectId('58e631a7f21e5d618900ec22'), 'name' : 'c', 'num' : [ 49 ], 'length' : 1 }
3、有了上面的数据后,然后可以利用aggregation中的$sort,$group等找到满足您的需求的Document的objectId,具体做法可以参考下面的帖子:
https://segmentfault.com/q/10...
4、最后批量删除相关的ObjectId
类似于:var dupls = [] 保存要删除的objectIddb.collectionName.remove({_id:{$in:dupls}})
供参考。
Love MongoDB! Have Fun!
戳我<--请戳左边,就在四月!MongoDB中文社区深圳用户大会开始报名啦!大神云集!
回答2:数据量的规模不是很大的话可以考虑重新爬取一次,每次存的时候查询一下,只存数据最多的一组数据。优秀的爬虫策略>>优秀的数据清洗策略
回答3:感谢各位网友,在qq群中,有人给出了思路,是在map的是先以urlId对forumdata进行处理,返回urlId和forumdatad.length,之后再在reduce中处理,保留forumdata.length最大的那个和对应的urlId,最后保存成一个数据库,之后通过这个数据库中的urlId来从原数据库中将所有数据读取出来。我试过了,虽然效率不是我期望的那种,不过速度还是比以前用python处理快了不少。附上map和reduce的代码:’’’javaScriptmapfunc=Code(
’function(){’’data=new Array();’’data={lenth:this.forumdata.length,’’id:this._id};’# ’data=this._id;’’emit({'id':this.urlId},data);’’}’)
reducefunc=Code(
’function(tieziID,dataset){’’reduceid=null;’’reducelenth=0;’’’’’’redecenum1=0;’’redecenum2=0;’’’’dataset.forEach(function(val){’’if(reducelenth<=val['lenth']){’’reducelenth=val['lenth'];’’reduceid=val['id'];’’redecenum1+=1;’’}’’redecenum2+=1;’’});’’return {'lenth':reducelenth,'id':reduceid};’’}’ )
上边是先导出一个新的数据库的代码,下边是处理这个数据库的代码:
mapfunc=Code(
’function(){’# ’data=new Array();’’lenth=this.forumdata.length;’’’’emit(this.urlId,lenth);’’}’
)
reducefunc=Code(
’function(key,value){’’return value;’’}’
)
之后添加到相应的map_reduce中就行了。感觉Bgou回答的不错,所以就选他的答案了,还没有去实践。上边是我的做法,就当以后给遇到同样问题的人有一个参考。
相关文章:
1. debian - docker依赖的aufs-tools源码哪里可以找到啊?2. 关docker hub上有些镜像的tag被标记““This image has vulnerabilities””3. 我何时应该在Java中使用JFrame.add(component)和JFrame.getContentPane()。add(component)4. docker api 开发的端口怎么获取?5. golang - 用IDE看docker源码时的小问题6. nignx - docker内nginx 80端口被占用7. 关于docker下的nginx压力测试8. 我在目录下运行命令结果出错,这是安装成功了还是失败?9. docker网络端口映射,没有方便点的操作方法么?10. mac连接阿里云docker集群,已经卡了2天了,求问?
 网公网安备
网公网安备