网页爬虫 - Python爬虫运行内存占用过高导致电脑停止响应
问题描述
各位好,我写了1个非常简单的爬虫去爬取51job里的招聘信息。从下面的链接里提取出每个招聘岗位的链接(一共50个链接)http://search.51job.com/jobse...再根据每个招聘岗位的url为每个岗位生成一个id,并且爬取每个岗位链接中的标题。最后把生成的信息打印到屏幕上。每次运行时内存占用率都会持续上升,最后导致电脑停止响应。代码非常简单,但是找不到哪里有问题。。我的环境是Ubuntu16.04,Python3.5,Pycharm.
尝试了下不用Pycharm直接运行还是不行,只输出了十几条信息后就停了。运行的时候一开始cpu很高,内存持续增长到2g多,电脑基本停止响应,用手机拍了一个图。过了几分钟后,cpu使用率掉下来了,但是内存占用还是80%左右。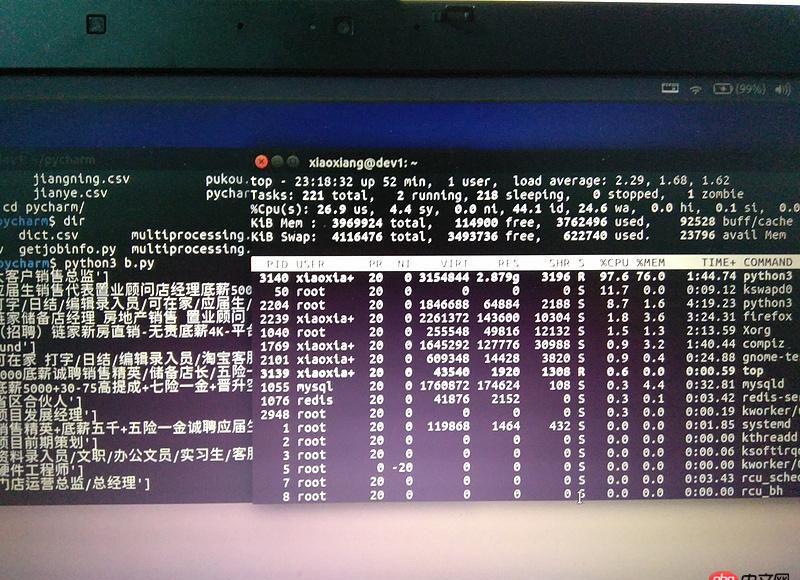
import requestsfrom lxml import etreeimport reheaders = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'en-US,en;q=0.5', 'Connection': 'keep-alive', 'Host': 'jobs.51job.com', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}def generate_info(url): html = requests.get(url, headers=headers) html.encoding = ’GBK’ select = etree.HTML(html.text.encode(’utf-8’)) job_id = re.sub(’[^0-9]’, ’’, url) job_title=select.xpath(’/html/body//h1/text()’) print(job_id,job_title)sum_page=’http://search.51job.com/jobsearch/search_result.php?fromJs=1&jobarea=070200%2C00&district=000000&funtype=0000&industrytype=00&issuedate=9&providesalary=06%2C07%2C08%2C09%2C10&keywordtype=2&curr_page=1&lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&list_type=0&dibiaoid=0&confirmdate=9’sum_html=requests.get(sum_page)sum_select=etree.HTML(sum_html.text.encode(’utf-8’))urls= sum_select.xpath(’//*[@id='resultList']/p/p/span/a/@href’)for url in urls: generate_info(url)
问题解答
回答1:这是idle的bug
把结果保存到文件里就行了~
回答2:我尝试跑了一下你的code,发现并没有出现内存占用过大的情况,最大的时候也不过30M。我建议你做以下尝试
不使用Pycharm直接在命令行下python xxx.py运行查看是否是Pycharm的原因
确认在运行时的内存占用还有CPU占用
正如你所说的一样,这个代码很简单,任务量也不大,应该不会出现这种问题的
回答3:pycharm偶尔就是有这种难解,建议直接python环境下运行。
相关文章:
1. javascript - SuperSlide.js火狐不兼容怎么回事呢2. 一个走错路的23岁傻小子的提问3. java - 创建maven项目失败了 求解决方法4. 运行python程序时出现“应用程序发生异常”的内存错误?5. html5 - iOS的webview加载出来的H5网页,怎么修改html标签select的样式字体?6. java-se - 正在学习Java SE,为什么感觉学习Java就是在学习一些API。7. python - 如何使用pykafka consumer进行数据处理并保存?8. javascript - git clone 下来的项目 想在本地运行 npm run install 报错9. 主从备份 - 跪求mysql 高可用主从方案10. python - django 里自定义的 login 方法,如何使用 login_required()
 网公网安备
网公网安备