文章详情页
网页爬虫 - Python:爬虫的中文编码问题?
浏览:263日期:2022-08-26 10:56:16
问题描述
爬取中文网页后正则匹配出中文,得打UTF-8的编码字符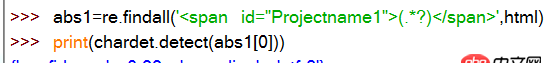
将其输出为.csv文件
在.CSV中显示为乱码
用记事本打开.csv又可以正常显示为中文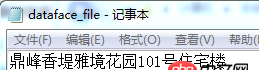
有没有大神指点是怎么一回事?怎样才能在Excel里直接看到中文?
问题解答
回答1:简单地方法是用pandas的to_excel方法转化成.xlsx文件,因为.xlsx默认编码是默认支持Excel的,区别当然是无法用记事本打开。
import pandas as pda = pd.read_csv(’./test.csv’)a.to_excel(’./test_output.xlsx’, index=False)a.to_excel(’./test_output.csv’, index=False)
我这里没有windows可以测试,可以尝试写入编码为gb2312或者gbk试试。
表格文件类I/O的话其实pandas更方便一点。
回答2:abs1=abs1.decode().encode(’gbk’)
回答3:excel默认使用的是GBK编码。
回答4:新建一个excel文件,然后点 数据 自文本,导入csv文件
相关文章:
1. debian - docker依赖的aufs-tools源码哪里可以找到啊?2. angular.js - angular内容过长展开收起效果3. 为什么我ping不通我的docker容器呢???4. 对html实现监测 发现不对5. docker - 各位电脑上有多少个容器啊?容器一多,自己都搞混了,咋办呢?6. docker内创建jenkins访问另一个容器下的服务器问题7. dockerfile - 为什么docker容器启动不了?8. angular.js使用$resource服务把数据存入mongodb的问题。9. 在mac下出现了两个docker环境10. javascript - js中向下取整
排行榜
 网公网安备
网公网安备