文章详情页
Python列表或者字典里面的中文如何处理?
浏览:294日期:2022-08-28 17:07:03
问题描述
已经是utf8编码了,但是在print mylist的时候打印出来的是它的utf8编码而不是我想要的汉字,网上有人说可以json.dumps的,但是这样的话就变成了string了不是列表或字典了。有什么办法可以在保证类型不改变的情况下可以通过mylist[0]这种下标访问方式访问到正确的中文,因为我想拿出来和另外的一个中文单词比较是否相等。谢谢。
问题解答
回答1:>>> list[u’u4e2du6587’, u’u6211u662fu4e2du6587’, u’u6211u8fd8u662fu4e2du6587’]>>> list[0]u’u4e2du6587’>>> list[0].encode(’utf8’)’xe4xb8xadxe6x96x87’>>> str = list[0].encode(’utf8’)>>> print str中文回答2:
如果你只是要格式好看的话。。。
import jsonzhlist = [u’中文’, u’英文’]print json.dumps(zhlist, ensure_ascii=False, indent=2)
打印出来看着一样,比较起来不一样,多半一个是unicode对象,一个是string对象,用type(obj)方法看看你要比较的两个值具体是什么类型的。如果你想完全搞懂编码问题,可以参考这个问题下面的头两个回答。
回答3:循环输出,即可。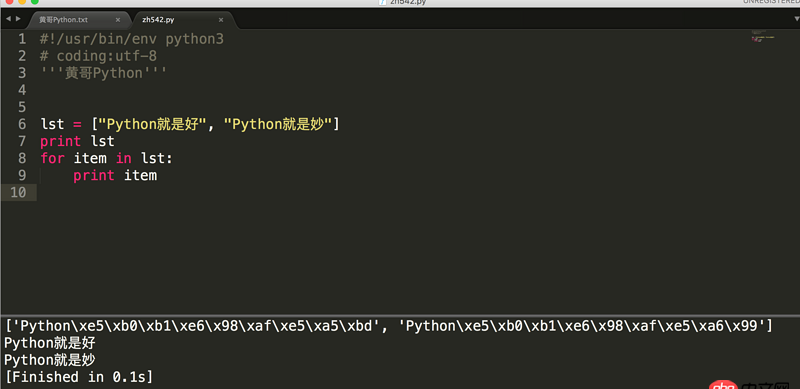
相关文章:
1. nignx - docker内nginx 80端口被占用2. docker-machine添加一个已有的docker主机问题3. javascript - 移动端 点击弹出遮罩层 加断点调试就行 不加断点就不行4. angular.js使用$resource服务把数据存入mongodb的问题。5. debian - docker依赖的aufs-tools源码哪里可以找到啊?6. 关于docker下的nginx压力测试7. dockerfile - 为什么docker容器启动不了?8. docker安装后出现Cannot connect to the Docker daemon.9. javascript - 正则匹配字符串特定语句后的数字10. docker容器呢SSH为什么连不通呢?
排行榜
 网公网安备
网公网安备