python - 如何用正则匹配出每一条记录后面的字符串?
问题描述
实际的案例请看下面我想在通过正则语句匹配出每一条信息的最后部分
目地车站: [ 0112 ]获取票价结果: iRet = 0TPU获取单价结果, [ 0 ]TPU获取单价为 [ 2.00 元] 票价最终单价为 [ 2.00 元] 票价
最后一段字符串前面都是[XXX]或[XXXX]这样的字符串,当然 这个X是0-9的数字,每一行结束都有一个换行符,请各位帮帮我看看这个正则要怎么写呢?
$DEBUG 2014-06-24 17:17:34.555@00000000@0000@[InitUITicketSinglePriceInfo][562]目地车站: [ 0112 ]$DEBUG 2014-06-24 17:17:34.565@00000000@0000@CTpuApp.GetTpuTicketPrice()-[1379]获取票价结果: iRet = 0$DEBUG 2014-06-24 17:17:34.565@00000000@0000@[GetTicketSinglePrice][609]TPU获取单价结果, [ 0 ]$DEBUG 2014-06-24 17:17:34.565@00000000@0000@[GetTicketSinglePrice][610]TPU获取单价为 [ 2.00 元] 票价$DEBUG 2014-06-24 17:17:34.565@00000000@0000@[InitUITicketSinglePriceInfo][568]最终单价为 [ 2.00 元] 票价
问题解答
回答1:[d+](.+)
用.net测了一下,OK的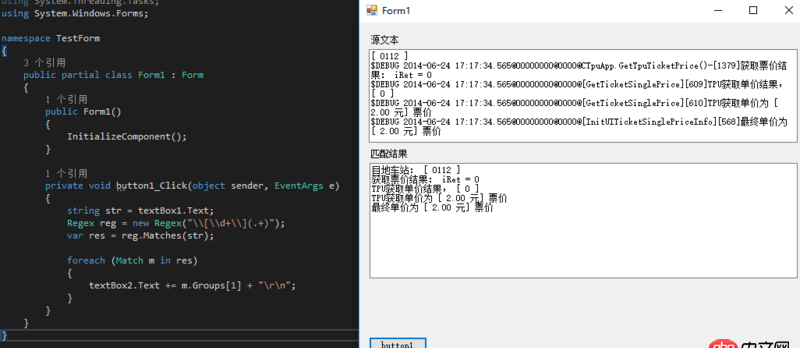
for match in re.finditer(r'[[0-9]+](.+)', '字符串'): # match start: match.start() # match end (exclusive): match.end() # matched text: match.group()
相关文章:
 网公网安备
网公网安备