编码 - Python 3.6中 ’utf-8’ codec can’t decode byte invalid start byte?
问题描述
Python 3.6中,网页信息解析失败,试了很多种编码,查看网页的编码方式也是utf-8。错误信息:’utf-8’ codec can’t decode byte 0x8b in position 1: invalid start byte?还有就是第一个print终端里打印出来的unicode内容是[b’x1fx8bx08x00x...]这种格式的,之前也有过这种情况,一个print打2个变量,就是b’x, 如果分来2行打又变回了汉字。是因为什么原因呢?
# -*- coding: utf-8 -*-import json , sqlite3import urllib.requesturl = (’http://wthrcdn.etouch.cn/weather_mini?city=%E4%B8%8A%E6%B5%B7’)resp = urllib.request.urlopen(url)content = resp.read()print(content)print(type(content))print(content.decode(’utf-8’))
问题解答
回答1: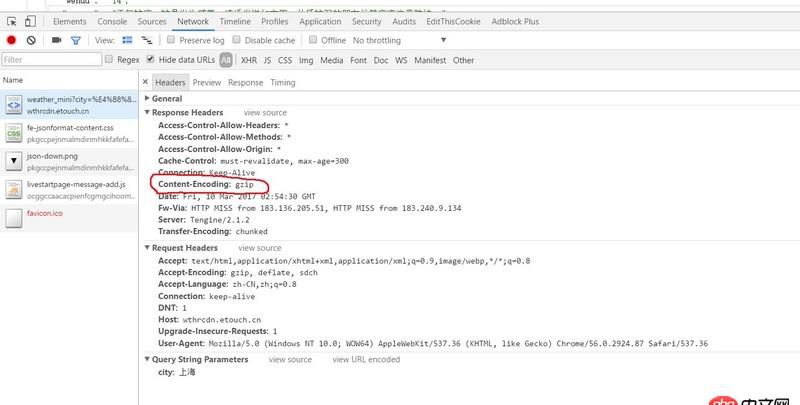
看了一下网站返回的是gzip压缩过的数据,所以要进行解码
# coding=utf-8from io import BytesIOimport gzipimport urllib.requesturl = (’http://wthrcdn.etouch.cn/weather_mini?city=%E4%B8%8A%E6%B5%B7’)resp = urllib.request.urlopen(url)content = resp.read() # content是压缩过的数据buff = BytesIO(content) # 把content转为文件对象f = gzip.GzipFile(fileobj=buff)res = f.read().decode(’utf-8’)print(res)
requests不好用吗?
回答3:
建议用requeset,代码如下:
import requestsr = requests.get(’http://wthrcdn.etouch.cn/weather_mini?city=%E4%B8%8A%E6%B5%B7’)print(r.text)回答4:
不是字符编码问题, 你看看你请求的 Respont headers
Status Code: 200 OK Access-Control-Allow-Headers: * Access-Control-Allow-Methods: * Access-Control-Allow-Origin: * Cache-Control: must-revalidate, max-age=300 Connection: Keep-Alive Content-Encoding: gzip Content-Length: 443 Date: Fri, 10 Mar 2017 03:20:46 GMT Fw-Cache-Status: hit Fw-Via: HTTP MISS from 58.59.19.99, DISK HIT from 183.131.161.27 Server: Tengine/2.1.2
是gzip, 如果用标准库的东西, 还需要把gzip 给解开
相关文章:
1. docker-compose 为何找不到配置文件?2. docker网络端口映射,没有方便点的操作方法么?3. 为什么我ping不通我的docker容器呢???4. mac连接阿里云docker集群,已经卡了2天了,求问?5. debian - docker依赖的aufs-tools源码哪里可以找到啊?6. vim - docker中新的ubuntu12.04镜像,运行vi提示,找不到命名.7. golang - 用IDE看docker源码时的小问题8. spring-mvc - spring-session-redis HttpSessionListener失效9. docker images显示的镜像过多,狗眼被亮瞎了,怎么办?10. html5和Flash对抗是什么情况?
 网公网安备
网公网安备