文章详情页
网页爬虫 - Python爬虫返回状态码与实际情况不符?
浏览:299日期:2022-09-03 18:57:11
问题描述
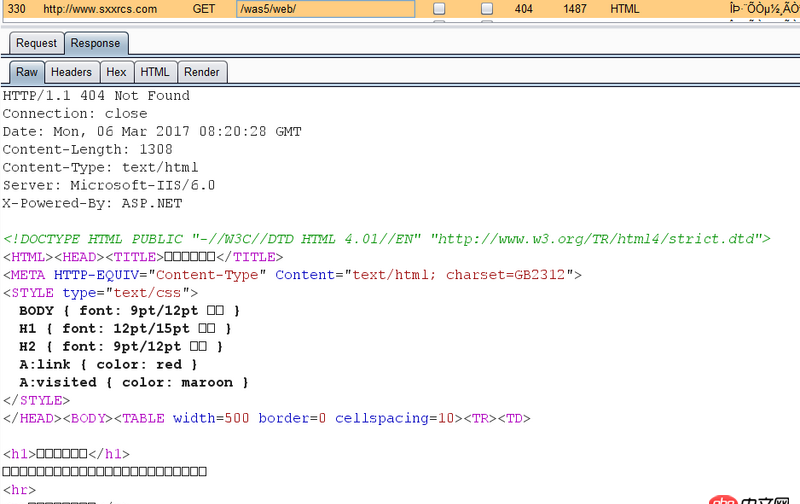
import urllib2opener = urllib2.build_opener()html = Noneresponse = Noneresponse = opener.open(’http://www.sxxrcs.com/was5/web/’)html = response.codeprint html
比如这个爬虫,输出状态码是200。

可是直接访问http://www.sxxrcs.com/was5/web/是404,抓包响应的也是404,请问这是为什么?
问题解答
回答1:用requests吧
import requestsr = requests.get(’http://www.sxxrcs.com/was5/web/’)print r.status_codeprint r.text回答2:
200正常啊,requests方便快捷。
相关文章:
1. 为什么我ping不通我的docker容器呢???2. golang - 用IDE看docker源码时的小问题3. angular.js - angular内容过长展开收起效果4. docker - 如何修改运行中容器的配置5. docker镜像push报错6. javascript - 关于数组的循环遍历问题7. css3 - IE浏览器下,一个元素设置overflow:auto后,出现下拉滚动条,拖动滚动条图片会移动,但文字不移动8. 关于phpstudy设置主从数据库9. docker-compose 为何找不到配置文件?10. javascript - 正则匹配字符串特定语句后的数字
排行榜
 网公网安备
网公网安备