文章详情页
python3.6通过urlopen打开一个以html结尾的网址,再转换成BeautifulSoup打印这个对象为空为什么?
浏览:204日期:2022-09-10 16:49:57
问题描述
htmlobj = urlopen(’http://www.58pic.com/haibao/0/dnum-1.html’)soup = BeautifulSoup(htmlobj, 'lxml')print(soup)
问题解答
回答1:请对比代码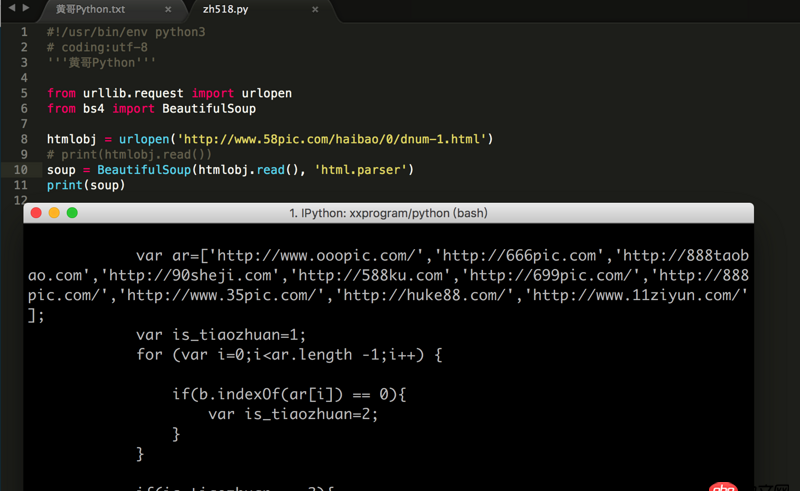
你应该这样
htmlobj = urlopen(’http://www.58pic.com/haibao/0/dnum-1.html’)soup = BeautifulSoup(htmlobj.read(), 'lxml')print(soup)回答3:
ubuntu 16.04,python3.5原代码可以输出,并不为空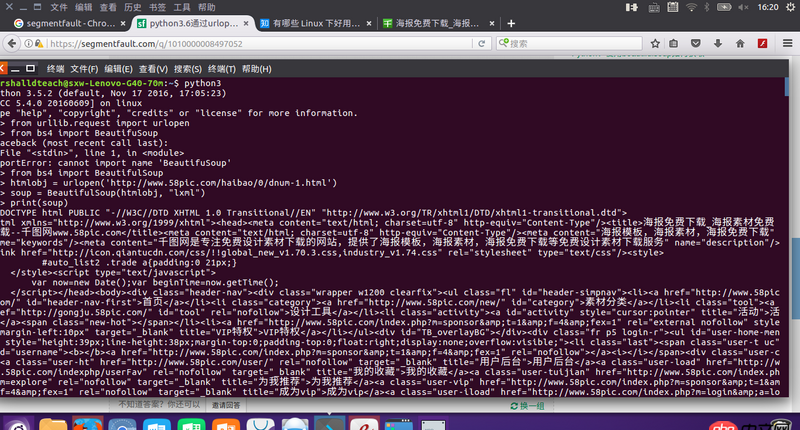
如果urlopen的确返回空值null,通常错误是服务器不存在。
排行榜
 网公网安备
网公网安备