文章详情页
python爬取页面时,一个URL无法访问导致报错,然后跳过这个报错继续抓取?
浏览:42日期:2022-09-13 09:16:56
问题描述
1.抓取到一个错误的URl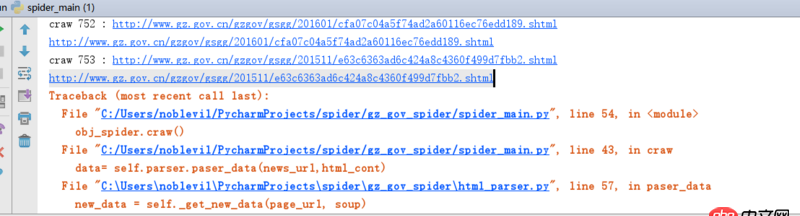

2.我的比蠢笨的办法:

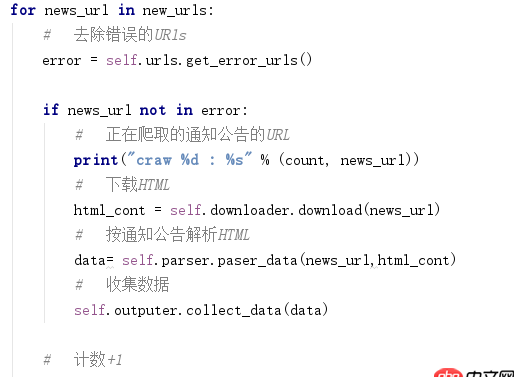
问题解答
回答1:curl里面有个可以设置返回header的,如果取到的数据非200状态,直接跳过处理就好了。
排行榜
问题描述
1.抓取到一个错误的URl
2.我的比蠢笨的办法:
问题解答
回答1:curl里面有个可以设置返回header的,如果取到的数据非200状态,直接跳过处理就好了。
 网公网安备 34170202000408号-皖ICP备2020019022号-1 sitemap
网公网安备 34170202000408号-皖ICP备2020019022号-1 sitemap
Copyright ¢ 2020-2025 Powered by http://www.haobala.com V1.8 All Rights Reserved 技术支持:好吧啦网