文章详情页
网页爬虫 - 关于python beautifullsoup解析网页内容丢失的问题?
浏览:88日期:2022-09-23 08:23:07
问题描述

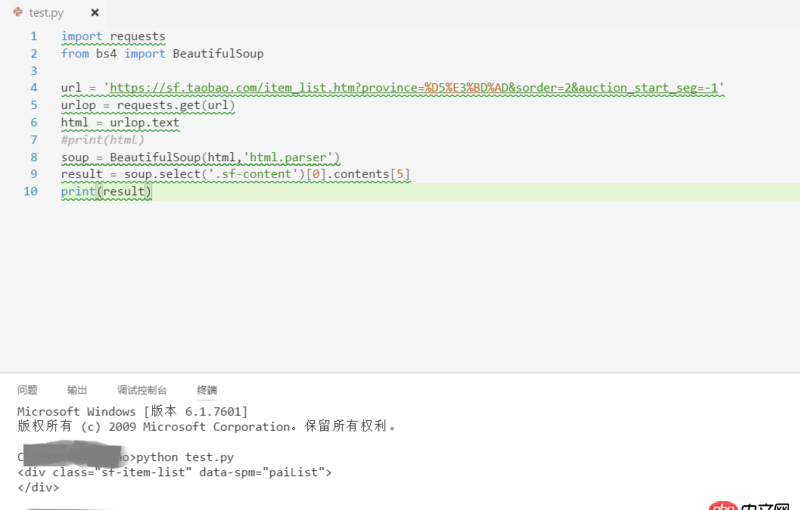
待解析页面的部分代码如第一幅图所示,我自己写的代码及运行结果如第二幅图所示。看到已经有答主提问解析页面丢失是因为用的是lxml的解析方式,我想说我一直用的是html.parser的方式。希望各位大神不吝赐教~
问题解答
回答1:你们从来都不考虑javascript动态加载的吗?
回答2:题主,如果你用Chrome F12看的话,里面是会有动态加载的内容的,而这些内容你直接请求页面的url是拿不到的。建议你点右键查看网页源代码,对照着F12里面的内容来看,源代码里没有的内容,就去查看Network里的其他请求,看有没有你需要的数据。
相关文章:
1. java - 创建maven项目失败了 求解决方法2. node.js - 函数getByName()中如何使得co执行完后才return3. 一个走错路的23岁傻小子的提问4. python - 如何使用pykafka consumer进行数据处理并保存?5. javascript - SuperSlide.js火狐不兼容怎么回事呢6. 运行python程序时出现“应用程序发生异常”的内存错误?7. 主从备份 - 跪求mysql 高可用主从方案8. javascript - git clone 下来的项目 想在本地运行 npm run install 报错9. mysql主从 - 请教下mysql 主动-被动模式的双主配置 和 主从配置在应用上有什么区别?10. python - django 里自定义的 login 方法,如何使用 login_required()
排行榜

 网公网安备
网公网安备