文章详情页
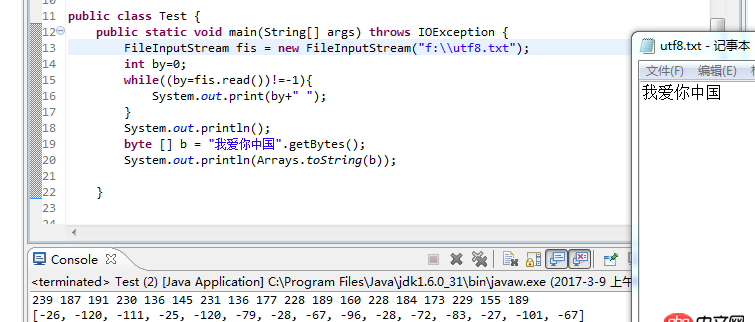
如图,java中同样是utf-8存储的字符串,为什么这两种方式输出的字节会不同?
浏览:116日期:2024-02-04 17:10:08
问题描述
问题解答
回答1:首先确保编码统一,文件编码UTF-8,以UTF-8去读文件,getBytes也传入UTF-8另,不要用记事本!不要用记事本!不要用记事本!重要的事情说三遍!!!
回答2:在 Java8 的文档中说 String.getBytes() 是按平台默认的字符集来编码。如果是 Windows,默认字符集不是 utf-8,而是 gbk。Linux 要看配置(具体如何我不是很清楚)。
Encodes this String into a sequence of bytes using the platform’s default charset, storing the result into a new byte array.
The behavior of this method when this string cannot be encoded in the default charset is unspecified. The CharsetEncoder class should be used when more control over the encoding process is required.
传送门:String.getBytes()
标签:
java
相关文章:
1. 如图,这两个java面试题的答案都是错误的吧?正确的应该怎么写呢?2. angular.js - 怎么用Angularjs 来实现如图3. node.js - yo webapp构建项目时报错了,如图4. java - 如图,同样一个表单,为什么用myeclipse内置的浏览器提交就会自动编码,用chrome浏览器就不会自动编码?5. css3 - 如图的flex骰子布局是怎么实现的?6. javascript - 一个抽奖的效果(如图)?7. javascript - 项目的公共文件如图片JS等文件放在 云上,webroot只放jsp文件,怎么将静态文件通过配置文件引入,sp求大神指导8. css3 怎么实现锯齿状的剪纸效果(如图)9. javascript - 百度搜索网站,如何让搜索结果显示一张图片加上一段描述,如图;求教10. 怎么php怎么通过数组显示sql查询结果呢,查询结果有多条,如图。我要forsearch里面echo
排行榜
 网公网安备
网公网安备