python利用K-Means算法实现对数据的聚类案例详解
目的是为了检测出采集数据中的异常值。所以很明确,这种情况下的簇为2:正常数据和异常数据两大类
1、安装相应的库import matplotlib.pyplot as plt # 用于可视化from sklearn.cluster import KMeans # 用于聚类import pandas as pd # 用于读取文件2、实现聚类2.1 读取数据并可视化
# 读取本地数据文件df = pd.read_excel('../data/output3.xls', header=0)
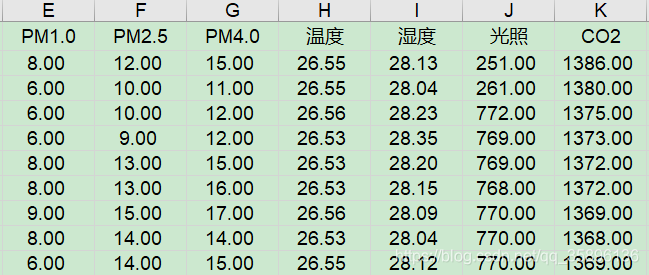
本次实验选择温度和CO2作为二维数据,其中温度含有异常数据。
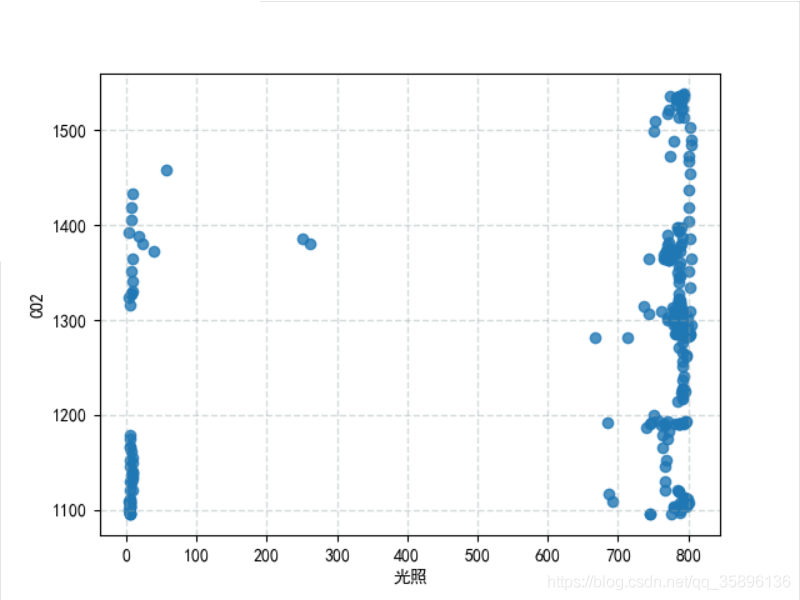
plt.scatter(df['光照'], df['CO2'], linewidths=1, alpha=0.8)plt.rcParams[’font.sans-serif’] = [’SimHei’] # 用来正常显示中文标签vplt.xlabel('光照')plt.ylabel('CO2')plt.grid(color='#95a5a6', linestyle='--', linewidth=1, alpha=0.4)plt.show()
设置规定要聚的类别个数为2
data = df[['光照','CO2']] # 从原始数据中选择该两项estimator = KMeans(n_clusters=2) # 构造聚类器estimator.fit(data) # 将数据带入聚类模型
获取聚类中心的值和聚类标签
label_pred = estimator.labels_ # 获取聚类标签centers_ = estimator.cluster_centers_ # 获取聚类中心
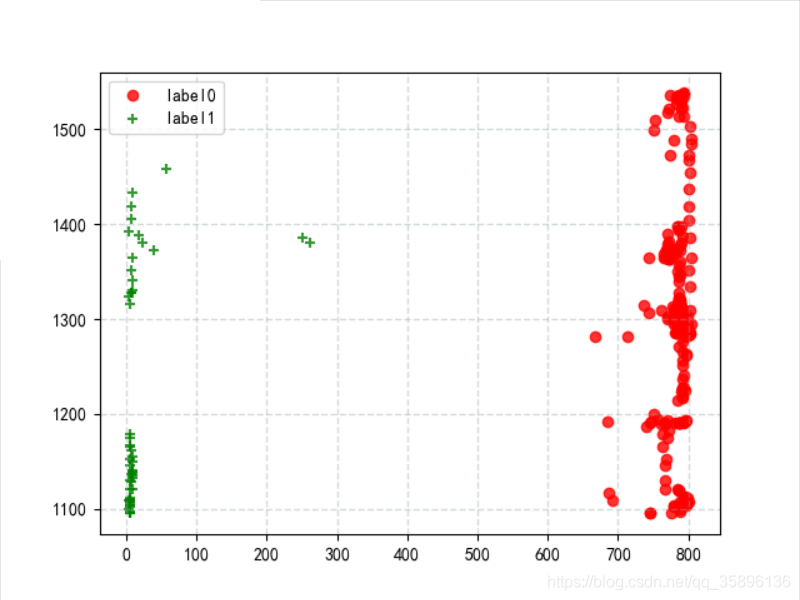
将聚类后的 label0 和 label1 的数据进行输出
x0 = data[label_pred == 0]x1 = data[label_pred == 1]plt.scatter(x0['光照'], x0['CO2'],c='red', linewidths=1, alpha=0.8,marker=’o’, label=’label0’)plt.scatter(x1['光照'], x1['CO2'],c='green', linewidths=1, alpha=0.8,marker=’+’, label=’label1’)plt.grid(c='#95a5a6', linestyle='--', linewidth=1, alpha=0.4)plt.legend()plt.show()
附上全部代码
import matplotlib.pyplot as pltfrom sklearn.cluster import KMeansimport pandas as pddf = pd.read_excel('../data/output3.xls', header=0)plt.scatter(df['光照'], df['CO2'], linewidths=1, alpha=0.8)plt.rcParams[’font.sans-serif’] = [’SimHei’] # 用来正常显示中文标签vplt.xlabel('光照')plt.ylabel('CO2')plt.grid(color='#95a5a6', linestyle='--', linewidth=1, alpha=0.4)plt.show()data = df[['光照','CO2']]estimator = KMeans(n_clusters=2) # 构造聚类器estimator.fit(data) # 聚类label_pred = estimator.labels_ # 获取聚类标签centers_ = estimator.cluster_centers_ # 获取聚类结果# print('聚类标签',label_pred)# print('聚类结果',centers_)# predict = estimator.predict([[787.75862069, 1505]]) # 测试新数据聚类结果# print(predict)x0 = data[label_pred == 0]x1 = data[label_pred == 1]plt.scatter(x0['光照'], x0['CO2'],c='red', linewidths=1, alpha=0.8,marker=’o’, label=’label0’)plt.scatter(x1['光照'], x1['CO2'],c='green', linewidths=1, alpha=0.8,marker=’+’, label=’label1’)plt.grid(c='#95a5a6', linestyle='--', linewidth=1, alpha=0.4)plt.legend()plt.show()
到此这篇关于python利用K-Means算法实现对数据的聚类的文章就介绍到这了,更多相关python K-Means算法数据的聚类内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
 网公网安备
网公网安备