Python实现一个论文下载器的过程
在科研学习的过程中,我们难免需要查询相关的文献资料,而想必很多小伙伴都知道SCI-HUB,此乃一大神器,它可以帮助我们搜索相关论文并下载其原文。可以说,SCI-HUB造福了众多科研人员,用起来也是“美滋滋”。

然而,当师姐告诉我:“xx,可以帮我下载几篇文献嘛?”。乐心助人的我自当是满口答应了,心想:“这种小事就交给我叭~”
于是乎,我收到了一个excel文档,66篇论文的列表安静地趟在里面(此刻心中碎碎念:“这尼玛,是几篇嘛...”)。我粗略算了一下,复制、粘贴、下载,一套流程走下来,每篇论文少说也得30秒,66篇的话....啊,这不能忍!
很显然,一篇一篇的下载,不是我的风格所以,我决定写一个论文下载器助我前行。
代码分析的详细思路跟以往依旧如此雷同,逃不过的还是:抓包分析->模拟请求->代码整合。由于一会儿kimol君还得去搬砖,今天就不详细展开了。
1. 搜索论文通过论文的URL、PMID、DOI号或者论文标题等搜索到对应的论文,并通过bs4库找出PDF原文的链接地址,代码如下:
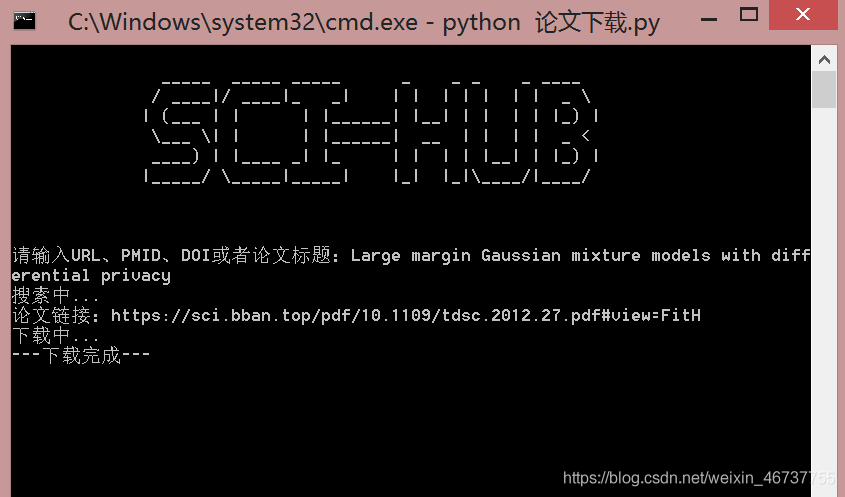
def search_article(artName): ’’’ 搜索论文 --------------- 输入:论文名 --------------- 输出:搜索结果(如果没有返回'',否则返回PDF链接) ’’’ url = ’https://www.sci-hub.ren/’ headers = {’User-Agent’:’Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0’, ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8’, ’Accept-Language’:’zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2’, ’Accept-Encoding’:’gzip, deflate, br’, ’Content-Type’:’application/x-www-form-urlencoded’, ’Content-Length’:’123’, ’Origin’:’https://www.sci-hub.ren’, ’Connection’:’keep-alive’, ’Upgrade-Insecure-Requests’:’1’} data = {’sci-hub-plugin-check’:’’, ’request’:artName} res = requests.post(url, headers=headers, data=data) html = res.text soup = BeautifulSoup(html, ’html.parser’) iframe = soup.find(id=’pdf’) if iframe == None: # 未找到相应文章 return ’’ else: downUrl = iframe[’src’] if ’http’ not in downUrl: downUrl = ’https:’+downUrl return downUrl2. 下载论文
得到了论文的链接地址之后,只需要通过requests发送一个请求,即可将其下载:
def download_article(downUrl): ’’’ 根据论文链接下载文章 ---------------------- 输入:论文链接 ---------------------- 输出:PDF文件二进制 ’’’ headers = {’User-Agent’:’Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0’, ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8’, ’Accept-Language’:’zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2’, ’Accept-Encoding’:’gzip, deflate, br’, ’Connection’:’keep-alive’, ’Upgrade-Insecure-Requests’:’1’} res = requests.get(downUrl, headers=headers) return res.content二、完整代码
将上述两个函数整合之后,我的完整代码如下:
# -*- coding: utf-8 -*-'''Created on Tue Jan 5 16:32:22 2021@author: kimol_love'''import osimport timeimport requestsfrom bs4 import BeautifulSoup def search_article(artName): ’’’ 搜索论文 --------------- 输入:论文名 --------------- 输出:搜索结果(如果没有返回'',否则返回PDF链接) ’’’ url = ’https://www.sci-hub.ren/’ headers = {’User-Agent’:’Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0’, ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8’, ’Accept-Language’:’zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2’, ’Accept-Encoding’:’gzip, deflate, br’, ’Content-Type’:’application/x-www-form-urlencoded’, ’Content-Length’:’123’, ’Origin’:’https://www.sci-hub.ren’, ’Connection’:’keep-alive’, ’Upgrade-Insecure-Requests’:’1’} data = {’sci-hub-plugin-check’:’’, ’request’:artName} res = requests.post(url, headers=headers, data=data) html = res.text soup = BeautifulSoup(html, ’html.parser’) iframe = soup.find(id=’pdf’) if iframe == None: # 未找到相应文章 return ’’ else: downUrl = iframe[’src’] if ’http’ not in downUrl: downUrl = ’https:’+downUrl return downUrl def download_article(downUrl): ’’’ 根据论文链接下载文章 ---------------------- 输入:论文链接 ---------------------- 输出:PDF文件二进制 ’’’ headers = {’User-Agent’:’Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0’, ’Accept’:’text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8’, ’Accept-Language’:’zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2’, ’Accept-Encoding’:’gzip, deflate, br’, ’Connection’:’keep-alive’, ’Upgrade-Insecure-Requests’:’1’} res = requests.get(downUrl, headers=headers) return res.content def welcome(): ’’’ 欢迎界面 ’’’ os.system(’cls’) title = ’’’ _____ _____ _____ _ _ _ _ ____ / ____|/ ____|_ _| | | | | | | | _ | (___ | | | |______| |__| | | | | |_) | ___ | | | |______| __ | | | | _ < ____) | |____ _| |_ | | | | |__| | |_) | |_____/ _____|_____| |_| |_|____/|____/ ’’’ print(title) if __name__ == ’__main__’: while True: welcome() request = input(’请输入URL、PMID、DOI或者论文标题:’) print(’搜索中...’) downUrl = search_article(request) if downUrl == ’’: print(’未找到相关论文,请重新搜索!’) else: print(’论文链接:%s’%downUrl) print(’下载中...’) pdf = download_article(downUrl) with open(’%s.pdf’%request, ’wb’) as f: f.write(pdf) print(’---下载完成---’) time.sleep(0.8)
不出所料,代码一跑,我便轻松完成了师姐交给我的任务,不香嘛?
到此这篇关于Python实现一个论文下载器的过程的文章就介绍到这了,更多相关python论文下载器内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
1. js select支持手动输入功能实现代码2. PHP正则表达式函数preg_replace用法实例分析3. vue使用moment如何将时间戳转为标准日期时间格式4. Android studio 解决logcat无过滤工具栏的操作5. vue-drag-chart 拖动/缩放图表组件的实例代码6. 什么是Python变量作用域7. Android 实现彻底退出自己APP 并杀掉所有相关的进程8. bootstrap select2 动态从后台Ajax动态获取数据的代码9. Android Studio3.6.+ 插件搜索不到终极解决方案(图文详解)10. 一个 2 年 Android 开发者的 18 条忠告
 网公网安备
网公网安备