Python基础进阶之海量表情包多线程爬虫功能的实现
在我们日常聊天的过程中会使用大量的表情包,那么如何去获取表情包资源呢?今天老师带领大家使用python中的爬虫去一键下载海量表情包资源
二、知识点requests网络库bs4选择器文件操作多线程
三、所用到得库import osimport requestsfrom bs4 import BeautifulSoup四、 功能
# 多线程程序需要用到的一些包# 队列from queue import Queuefrom threading import Thread五、环境配置
解释器 python3.6编辑器 pycharm专业版 激活码
六、多线程类代码# 多线程类class Download_Images(Thread): # 重写构造函数 def __init__(self, queue, path): Thread.__init__(self) # 类属性 self.queue = queue self.path = path if not os.path.exists(path): os.mkdir(path) def run(self) -> None: while True: # 图片资源的url链接地址 url = self.queue.get() try:download_images(url, self.path) except:print(’下载失败’) finally:# 当爬虫程序执行完成/出错中断之后发送消息给线程 代表线程必须停止执行self.queue.task_done()七、爬虫代码
# 爬虫代码def download_images(url, path): headers = { ’User-Agent’: ’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36’ } response = requests.get(url, headers=headers) soup = BeautifulSoup(response.text, ’lxml’) img_list = soup.find_all(’img’, class_=’ui image lazy’) for img in img_list: image_title = img[’title’] image_url = img[’data-original’] try: with open(path + image_title + os.path.splitext(image_url)[-1], ’wb’) as f:image = requests.get(image_url, headers=headers).contentprint(’正在保存图片:’, image_title)f.write(image)print(’保存成功:’, image_title) except: passif __name__ == ’__main__’: _url = ’https://fabiaoqing.com/biaoqing/lists/page/{page}.html’ urls = [_url.format(page=page) for page in range(1, 201)] queue = Queue() path = ’./threading_images/’ for x in range(10): worker = Download_Images(queue, path) worker.daemon = True worker.start() for url in urls: queue.put(url) queue.join() print(’下载完成...’)八、爬取效果图片
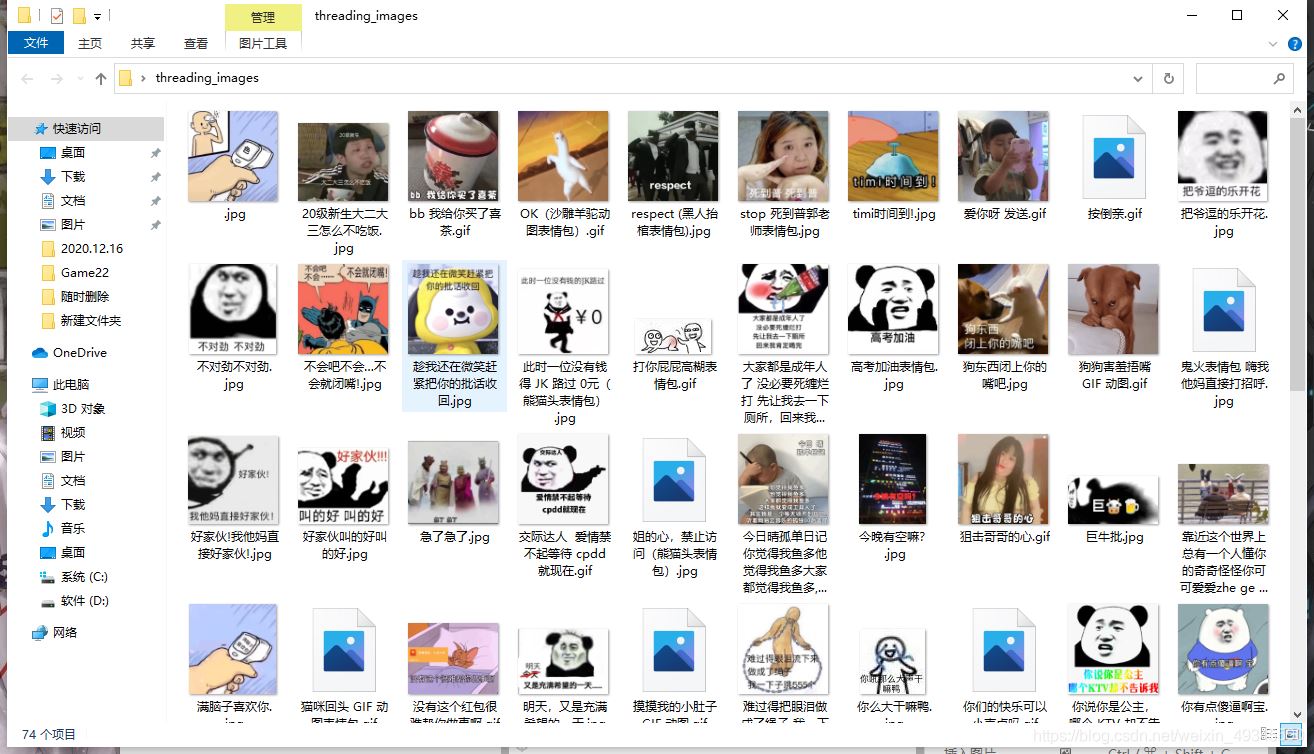
到此这篇关于Python基础进阶之海量表情包多线程爬虫的文章就介绍到这了,更多相关Python多线程爬虫内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
 网公网安备
网公网安备