Python根据URL地址下载文件并保存至对应目录的实现
引言
在编程中经常会遇到图片等数据集将图片等数据以URL形式存储在txt文档中,为便于后续的分析,需要将其下载下来,并按照文件夹分类存储。本文以Github中Alexander Kim提供的图片分类数据集为例,下载其提供的图片样本并分类保存
Python 3.6.5,Anaconda, VSCode
1. 下载数据集文件
建立项目文件夹,下载上述Github项目中的raw_data文件夹,并保存至项目目录中。
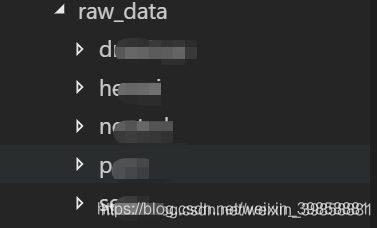
2. 获取样本文件位置
编写get_doc_path.py,根据根目录位置,获取目录及其子目录所有数据集文件
import osdef get_file(root_path, all_files={}): ’’’ 递归函数,遍历该文档目录和子目录下的所有文件,获取其path ’’’ files = os.listdir(root_path) for file in files: if not os.path.isdir(root_path + ’/’ + file): # not a dir all_files[file] = root_path + ’/’ + file else: # is a dir get_file((root_path+’/’+file), all_files) return all_filesif __name__ == ’__main__’: path = ’./raw_data’ print(get_file(path))
3. 下载文件
3.1 读取url列表并
for filename, path in paths.items(): print(’reading file: {}’.format(filename)) with open(path, ’r’) as f: lines = f.readlines() url_list = [] for line in lines:url_list.append(line.strip(’n’)) print(url_list)
3.2 创建文件夹
foldername = './picture_get_by_url/pic_download/{}'.format(filename.split(’.’)[0])if not os.path.exists(folder_path): print('Selected folder not exist, try to create it.') os.makedirs(folder_path)
3.3 下载图片
def get_pic_by_url(folder_path, lists): if not os.path.exists(folder_path): print('Selected folder not exist, try to create it.') os.makedirs(folder_path) for url in lists: print('Try downloading file: {}'.format(url)) filename = url.split(’/’)[-1] filepath = folder_path + ’/’ + filename if os.path.exists(filepath): print('File have already exist. skip') else: try:urllib.request.urlretrieve(url, filename=filepath) except Exception as e:print('Error occurred when downloading file, error message:')print(e)
4. 完整源码
4.1 get_doc_path.py
import osdef get_file(root_path, all_files={}): ’’’ 递归函数,遍历该文档目录和子目录下的所有文件,获取其path ’’’ files = os.listdir(root_path) for file in files: if not os.path.isdir(root_path + ’/’ + file): # not a dir all_files[file] = root_path + ’/’ + file else: # is a dir get_file((root_path+’/’+file), all_files) return all_filesif __name__ == ’__main__’: path = ’./raw_data’ print(get_file(path))
4.2 get_pic.py
import get_doc_pathimport osimport urllib.requestdef get_pic_by_url(folder_path, lists): if not os.path.exists(folder_path): print('Selected folder not exist, try to create it.') os.makedirs(folder_path) for url in lists: print('Try downloading file: {}'.format(url)) filename = url.split(’/’)[-1] filepath = folder_path + ’/’ + filename if os.path.exists(filepath): print('File have already exist. skip') else: try:urllib.request.urlretrieve(url, filename=filepath) except Exception as e:print('Error occurred when downloading file, error message:')print(e)if __name__ == '__main__': root_path = ’./picture_get_by_url/raw_data’ paths = get_doc_path.get_file(root_path) print(paths) for filename, path in paths.items(): print(’reading file: {}’.format(filename)) with open(path, ’r’) as f: lines = f.readlines() url_list = [] for line in lines:url_list.append(line.strip(’n’)) foldername = './picture_get_by_url/pic_download/{}'.format(filename.split(’.’)[0]) get_pic_by_url(foldername, url_list)
4.3 运行结果
执行get_pic.py当程序意外停止或再次执行时,程序会自动跳过文件夹中已下载的文件,继续下载未下载的内容
{‘urls_drawings.txt’: ‘./picture_get_by_url/raw_data/drawings/urls_drawings.txt’, ‘urls_hentai.txt’: ‘./picture_get_by_url/raw_data/hentai/urls_hentai.txt’, ‘urls_neutral.txt’: ‘./picture_get_by_url/raw_data/neutral/urls_neutral.txt’, ‘urls_porn.txt’: ‘./picture_get_by_url/raw_data/porn/urls_porn.txt’, ‘urls_sexy.txt’: ‘./picture_get_by_url/raw_data/sexy/urls_sexy.txt’}reading file: urls_drawings.txtTry downloading file: http://41.media.tumblr.com/xxxxxx.jpgTry downloading file: http://41.media.tumblr.com/xxxxxx.jpgTry downloading file: http://ak1.polyvoreimg.com/cgi/img-thing/size/l/tid/xxxxxx.jpgError occurred when downloading file, error message:HTTP Error 502: No data received from server or forwarderTry downloading file: http://akicocotte.weblike.jp/gaugau/xxxxxx.jpgTry downloading file: http://animewriter.files.wordpress.com/2009/01/nagisa-xxxxxx-xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpgTry downloading file: http://cdn.awwni.me/xxxxxx.jpg
后注:由于样本数据集内容的问题,上述地址以xxxxx代替具体地址,案例项目也已经失效,但是方法仍然可以借鉴
20.9.23更新:数据集地址:https://github.com/ZQ-Qi/nsfw_data_scrapper,单纯为了学习和实践本文代码的可以下载该数据集进行尝试
到此这篇关于Python根据URL地址下载文件并保存至对应目录的实现的文章就介绍到这了,更多相关Python URL下载文件内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
 网公网安备
网公网安备