Python中免验证跳转到内容页的实例代码
相信很多人在浏览网页时,经常会碰到需要输入验证码才可以继续浏览的情况吧,遇到这种问题,大多数人只能进行繁琐的注册验证,今天小编教大家只要使用python就可以免验证方法。
以经常用到的解答网站——上学吧为例,在网站里点击答案页面,会显示验证后才可以查看提示,下面就使用python实现跳过验证码。
我们需要通过python构造随机的 X-Forwarded-For 信息来绕过 ASP 网站的 IP 检测,可以实现对输入的网址正确性进行检查、对验证码核验不通过时的处理等等。
python免验证跳转页面代码如下:
# 绕过验证码无限次获取上学吧题目答案# 上学吧网址:https://www.shangxueba.com/askimport osimport randomimport requestsimport urllib3urllib3.disable_warnings() # 这句和上面一句是为了忽略 https 安全验证警告,参考:https://www.cnblogs.com/ljfight/p/9577783.htmlfrom bs4 import BeautifulSoupfrom PIL import Imagedef get_verifynum(session): # 网址的验证码逻辑是先去这个网址获取验证码图片,提交计算结果到另外一个网址进行验证。r = session.get('https://www.shangxueba.com/ask/VerifyCode2.aspx', verify=False) # HTTPS 请求进行 SSL 验证或忽略 SSL 验证才能请求成功,忽略方式为 verify=False。参考:https://www.cnblogs.com/ljfight/p/9577783.htmlwith open(’temp.png’,’wb+’) as f:f.write(r.content)image = Image.open(’temp.png’)image.show() # 调用系统的图片查看软件打开验证码图片,如果不能打开,可以自己找到 temp.png 打开。verifynum = input('n请输入验证码图片中的计算结果:')image.close()os.remove('temp.png')return verifynumdef get_question(session):r = session.get(link)soup = BeautifulSoup(r.content, 'html.parser')description = soup.find(attrs={'name':'description'})[’content’] # 抓取题干内容return descriptiondef get_answer(session, verifynum, dataid):data1 = {'Verify': verifynum,'action': 'CheckVerify',}session.post('https://www.shangxueba.com/ask/ajax/GetZuiJia.aspx', data=data1) # 核查验证码正确性data2 = {'phone':'','dataid': dataid,'action': 'submitVerify','siteid': '1001','Verify': verifynum,}r = session.post('https://www.shangxueba.com/ask/ajax/GetZuiJia.aspx', data=data2)soup = BeautifulSoup(r.content, 'html.parser')ans = soup.find(’h6’)print('n' + ’-’*45)if(ans): # 只有验证码核查通过才会显示答案print('n题目:' + get_question(session))print(ans.text)else:print(’n没有找到答案!请检查验证码或网址是否输入有误!n’)print(’-’*45)if __name__ == ’__main__’:s = requests.session()while True:s.headers.update({'X-Forwarded-For':'%d.%d.%d.%d'%(random.randint(120,125),random.randint(1,200),random.randint(1,200),random.randint(1,200))}) # 这一句是整个程序的关键,通过修改 X-Forwarded-For 信息来欺骗 ASP 站点对于 IP 的验证。link = input('n请输入上学吧网站上某道题目的网址,例如:https://www.shangxueba.com/ask/8952241.htmlnn请输入:').strip() # 过滤首尾的空格if(link[0:31] != 'https://www.shangxueba.com/ask/' or link[-4:] != 'html'):print('n网址输入有误!请重新输入!n')continuedataid = link.split('/')[-1].replace(r'.html','') # 提取网址最后的数字部分if(dataid.isdigit()): # 根据格式,dataid 应该全部为数字,判断字符串是否全部为数字,返回 True 或者 Falseverifynum = get_verifynum(s)get_answer(s, verifynum, dataid)else:print('n网址输入有误!请重新输入!n')continue
注意:其中 requests 和 beautifulsoup 两个库需要另外安装,建议使用 pip 方式安装:
pip install requestspip install beautifulsoup4
Python 脚本运行流程:
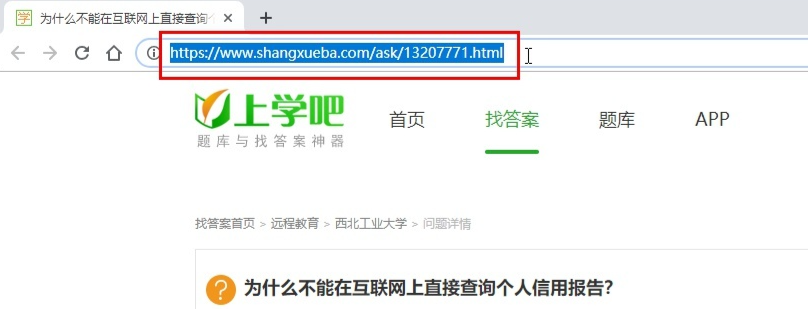
首先复制上学吧某道题目的网址,类似以下格式:
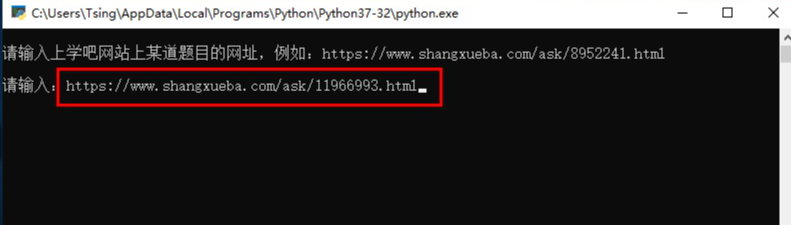
然后运行python脚本,复制粘贴网址。
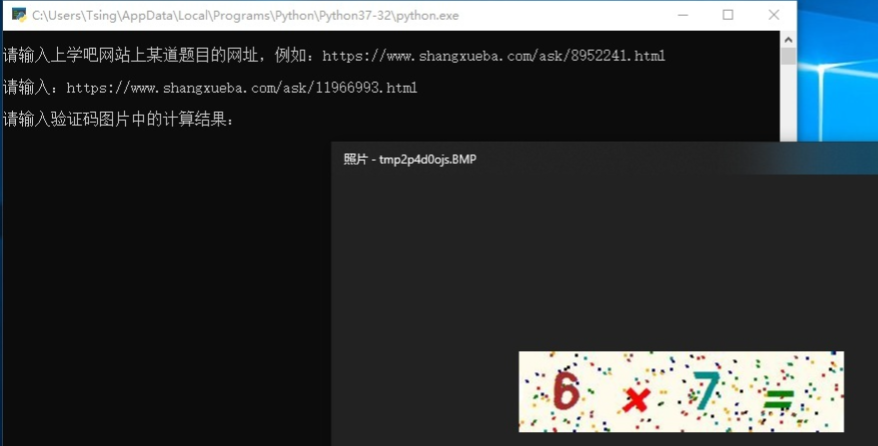
按Enter键,自动下载验证码图片存为 temp.png,然后自动读取图片并展示,也可以手动打开同目录下的 temp.png 图片。
最后在命令行窗口输入验证码图片中的计算结果即可获取题目详情以及正确答案。
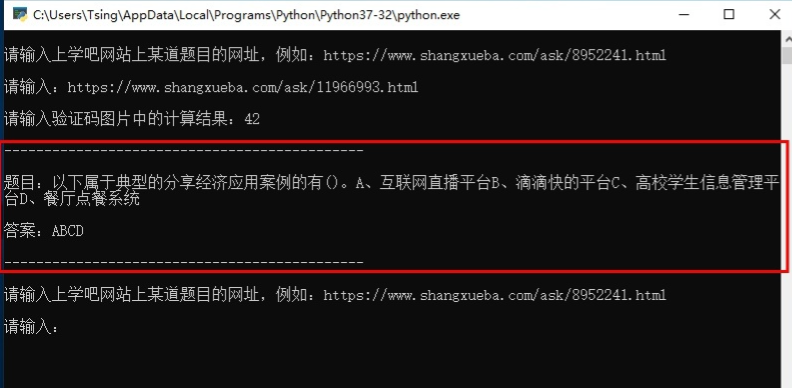
到此这篇关于Python中免验证跳转到内容页的实例代码的文章就介绍到这了,更多相关Python如何免验证跳转到内容页内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
 网公网安备
网公网安备