Python中Selenium模块的使用详解
Selenium的介绍、配置和调用
Selenium(浏览器自动化测试框架) 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
框架底层使用JavaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。 使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。 使用简单,可使用Java,Python等多种语言编写用例脚本。Selenium的配置
1、安装 Selenium模块: pip install Selenium
2、下载浏览器驱动,Selenium3.x调用浏览器必须有一个webdriver驱动文件
Chrome驱动文件下载:点击下载chromedrive
Firefox 驱动文件下载 :点解下载geckodriver
下载之后,解压到任意目录(路径不要有中文)。
Selenium的调用
from selenium import webdriver## 如果是chrome浏览器的驱动driver=webdriver.Chrome('G:Anaconda3-5.3.0chromedriver.exe')##如果是firefox浏览器的驱动driver=webdriver.Firefox(executable_path='G:Anaconda3-5.3.0geckodriver.exe')######如果浏览器驱动的目录加入了环境变量的话## 如果是chrome浏览器的驱动driver=webdriver.Chrome()##如果是firefox浏览器的驱动driver=webdriver.Firefox()
Selenium的使用 定位
Selenium提供了8种定位方式
1.id2.name3.class name4.tag name5.link text6.partial link text7.xpath8.css selector
定位元素的使用
定位一个元素 定位多个元素 含义 find_element_by_id find_elements_by_id 通过元素id定位 find_element_by_name find_elements_by_name 通过元素name定位 find_element_by_class_name find_elements_by_class_name 通过classname进行定位 find_element_by_tag_name find_elements_by_tag_name 通过标签定位 find_element_by_link_text find_elements_by_link_tex 通过完整超链接定位 find_element_by_partial_link_text find_elements_by_partial_link_text 通过部分链接定位 find_elements_by_css_selector find_elements_by_css_selector 通过css选择器进行定位 find_element_by_xpath find_elements_by_xpath 通过xpath表达式定位
例如:
<html> <body> <form id='loginForm'> <input name='username' type='text' classname='xie' /> <input name='password' type='password' 型号 /> <input name='continue' type='submit' value='Login' /> <input name='continue' type='button' value='Clear' /> </form> <a href='http://www.baidu.com' rel='external nofollow' >百度一下</a> </body></html>
通过id进行定位第一个input框: find_element_by_id('key')
通过name进行定位第一个input框:find_element_by_name('username')
通过classname进行定位第一个input框:find_element_by_class_name('xie')
通过标签tag进行定位input框:find_element_by_tag_name('input') //这里input太多了,用input标签定位会出错
通过完整超链接定位a标签: find_element_by_link_text('百度一下')
用xpath进行定位:
用绝对路径进行定位,input[1]代表form下面的第一个input标签,从1开始, input=input[1]driver.find_elemant_by_xpath('//html/body/form/input[1]')用相对路径进行定位,form标签下的第一个input标签,[1]省略了driver.find_element_by_xpath('//form/input')用相对路径和属性进行定位,form标签下的input标签的name值等于username的标签driver.find_element_by_xpath('//form/input[@name=’username’]')其他的属性值如果太长,也可以采取模糊方法定位例如页面中有这么一个标签 <a href='http://www.baidu.com?name=admin&passwd=pass&action=login' rel='external nofollow' >百度一下</a>则可以这么使用 driver.find_element_by_xpath('//a[contains(@href,’login’)]')
以上是普通的情况,存在可以定位的属性,当某个元素的各个属性及其组合都不足以定位时,我们可以利用其兄弟节点或者父节点等各种可以定位的元素进行定位,先看看xpath中支持的方法:
1、child 选取当前节点的所有子元素
2、parent 选取当前节点的父节点
3、descendant选取当前节点的所有后代元素(子、孙等)
4、ancestor 选取当前节点的所有先辈(父、祖父等)
5、descendant-or-self选取当前节点的所有后代元素(子、孙等)以及当前节点本身
6、ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身
7、preceding-sibling选取当前节点之前的所有同级节点
8、following-sibling选取当前节点之后的所有同级节点
9、preceding 选取文档中当前节点的开始标签之前的所有节点
10、following 选取文档中当前节点的结束标签之后的所有节点
11、self 选取当前节点
12、attribute 选取当前节点的所有属性
13、namespace选取当前节点的所有命名空间节点

上图实例,需要点击订单号为17051915200001的发货按钮,这时候不能直接定位到发货按钮,而是要先定位到订单号元素,再定位他的兄弟节点。参照上图,我们首先定位到td标签中包含订单号的td元素,然后选择其之后的同级节点,following-sibling,我们要找的元素在后面的第8个td标签下,因此定位可以写名为下面的格式
driver.find_element_by_xpath('//td[contains(text(),’17051915200001’)]/following-sibling::td[8]/a[@class=’link’]')
但是如果页面中有两个相同的定位元素的话,我们这样使用就有可能会报错
比如有下面两个输入框,一个输入用户名的,一个输入密码的,但是 class 都是等于 inputclass 。这时,如果我们使用class_name 来定位元素的话,就会出现意想不到的错误
<input type='text' name='username'><input type='password' name='password'><br/>#python代码driver.find_element_by_class_name('inputclass').send_keys('admin')driver.find_element_by_class_name('inputclass').send_keys('password')
我们的本意是在username框内输入admin,password框内输入 password 。但是由于两个框的 class 相同,而我们又是使用class_name进行元素的定位,所以我们所有的操作都会对第一个元素进行。

还有如果我们定位的元素页面没有的话,也会报错
比如我们使用这条语句用class_name来进行定位元素,但是当页面没有 class_name='aa' 的元素的话,就会报错,表示找不到通过 class name 方法找的元素 aa
driver.find_element_by_class_name('aa').send_keys('bb')NoSuchElementException: no such element: Unable to locate element: {'method':'class name','selector':'aa'}
定位下拉标签元素

import SelectSelect(driver.find_element_by_xpath('//select[@id=’9560af43bfc949c4826d329c352e4eb6_class’]')).select_by_index(4) #定位公共互联网环境
在iframe框架之间切换

#切换到指定的iframe框架driver.switch_to.frame('mainFrame') #切换iframe框架driver.switch_to.default_content() #切换到主框架
上传文件
上传文件使用的是AutoIt,安装好后,打开AutoIt Window Info,鼠标选中Finder Tool,然后鼠标左键按住拖到文件名框内,得到如图数据
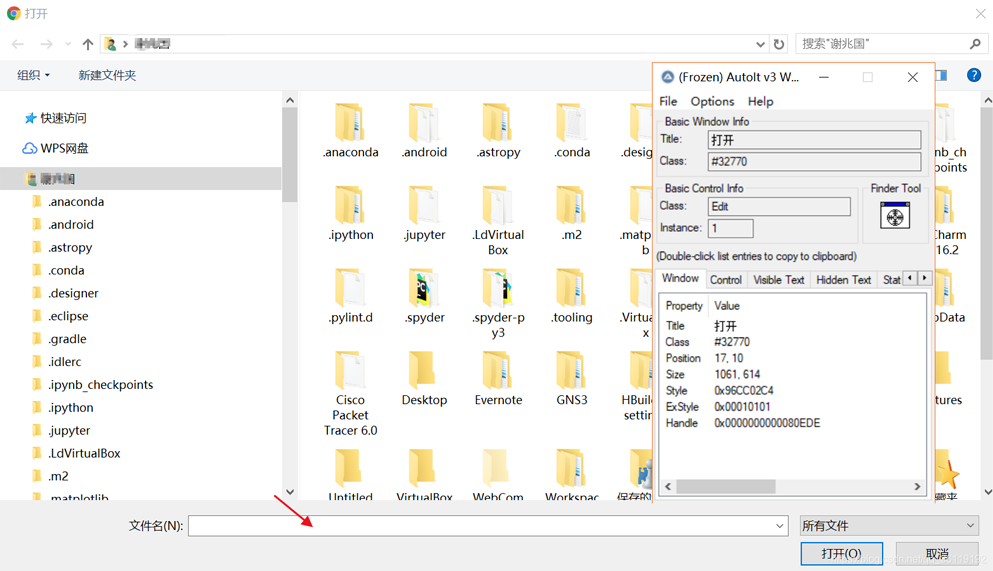
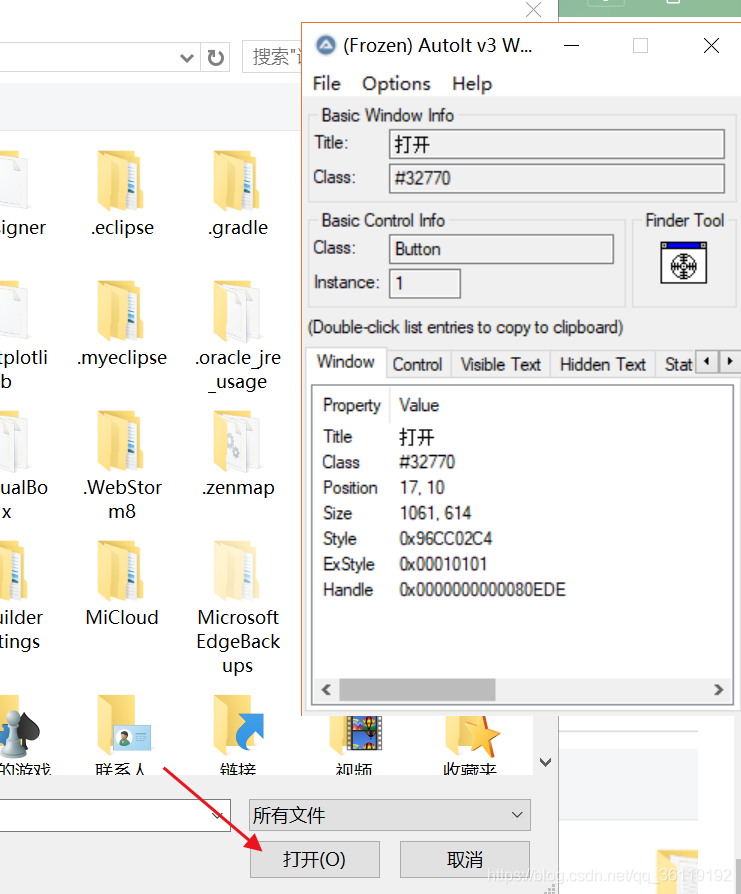
然后鼠标选中Finder Tool,鼠标左键按住拖到打开按钮,得到如图数据
打开SciTE Script Editor,输入如下内容
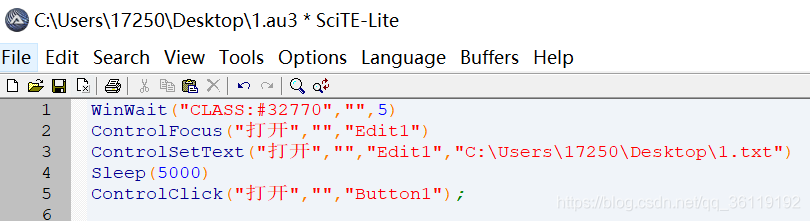
WinWait('CLASS:#32770','',5) #设置5秒用于等待上传窗口的显示ControlFocus('打开','','Edit1') #把输入焦点定位到上传文本框中ControlSetText('打开','','Edit1','C:Users17250Desktop1.txt') #输入文件路径Sleep(5000) #等待上传时间,单位毫秒ControlClick('打开','','Button1'); #点击打开按钮,开始上传
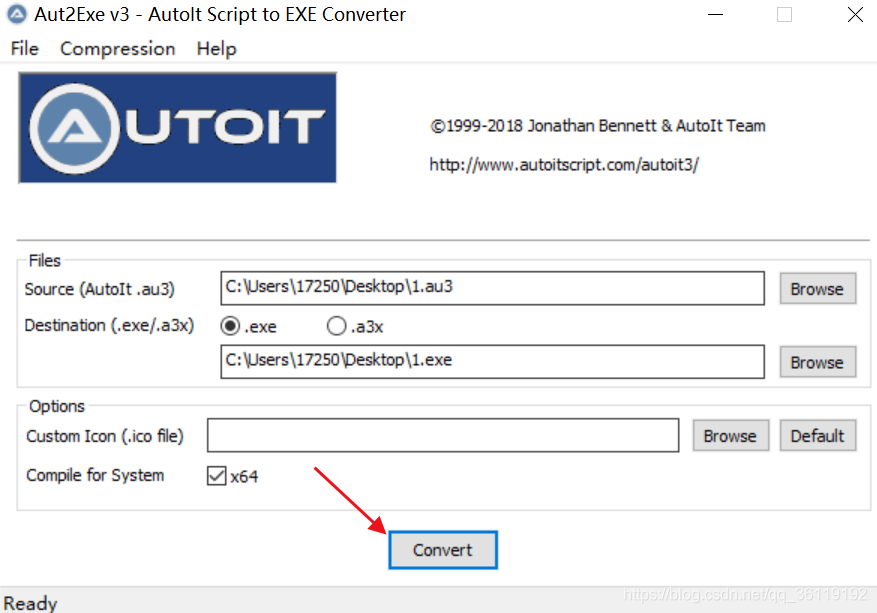
保存为1.au3,点击Tools->Go运行。
然后打开Compile Script to .exe ,然后选中1.au3,它会自动将其转换为1.exe。
在python中使用
os.system('C:Users17250Desktop1.exe')
Webdriver模块的使用
控制浏览器操作的一些方法
方法 说明 set_window_size() 设置浏览器的大小 back() 控制浏览器后退 forward() 控制浏览器前进 refresh() 刷新当前页面 clear() 清除文本 send_keys (value) 模拟按键输入 click() 单击元素 submit() 用于提交表单 get_attribute(name) 获取元素属性值 is_displayed() 设置该元素是否用户可见 size 返回元素的尺寸 text 获取元素的文本
鼠标事件
在 WebDriver 中, 将这些关于鼠标操作的方法封装在 ActionChains 类提供。
方法 说明 ActionChains(driver) 构造ActionChains对象 context_click() 执行鼠标悬停操作 move_to_element(above) 右击 double_click() 双击 drag_and_drop() 拖动 move_to_element(above) 执行鼠标悬停操作 context_click() 用于模拟鼠标右键操作, 在调用时需要指定元素定位 perform() 执行所有 ActionChains 中存储的行为,可以理解成是对整个操作的提交动作
键盘事件
Selenium中的Key模块为我们提供了模拟键盘按键的方法,那就是send_keys()方法。它不仅可以模拟键盘输入,也可以模拟键盘的操作。
常用的键盘操作如下:
模拟键盘按键 说明 send_keys(Keys.BACK_SPACE) 删除键(BackSpace) send_keys(Keys.SPACE) 空格键(Space) send_keys(Keys.TAB) 制表键(Tab) send_keys(Keys.ESCAPE) 回退键(Esc) send_keys(Keys.ENTER) 回车键(Enter)
组合键的使用
模拟键盘按键 说明 send_keys(Keys.CONTROL,‘a’) 全选(Ctrl+A) send_keys(Keys.CONTROL,‘c’) 复制(Ctrl+C) send_keys(Keys.CONTROL,‘x’) 剪切(Ctrl+X) send_keys(Keys.CONTROL,‘v’) 粘贴(Ctrl+V) send_keys(Keys.F1…Fn) 键盘 F1…Fn
获取断言信息
不管是在做功能测试还是自动化测试,最后一步需要拿实际结果与预期进行比较。这个比较的称之为断言。通过我们获取title 、URL和text等信息进行断言。
属性 说明 title 用于获得当前页面的标题 current_url 用户获得当前页面的URL text 获取搜索条目的文本信息
参考文章:https://blog.csdn.net/weixin_36279318/article/details/79475388
到此这篇关于Python中Selenium模块的使用详解的文章就介绍到这了,更多相关Python Selenium模块使用内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
 网公网安备
网公网安备