简述python&pytorch 随机种子的实现
随机数广泛应用在科学研究, 但是计算机无法产生真正的随机数, 一般成为伪随机数. 它的产生过程: 给定一个随机种子(一个正整数), 根据随机算法和种子产生随机序列. 给定相同的随机种子, 计算机产生的随机数列是一样的(这也许是伪随机的原因).
随机种子是什么?
随机种子是针对随机方法而言的。
随机方法:常见的随机方法有 生成随机数,以及其他的像 随机排序 之类的,后者本质上也是基于生成随机数来实现的。在深度学习中,比较常用的随机方法的应用有:网络的随机初始化,训练集的随机打乱等。
随机种子的取值范围?
可以是任意数字,如10,1000
python random
下面以python的random函数为例, 做了一个测试.
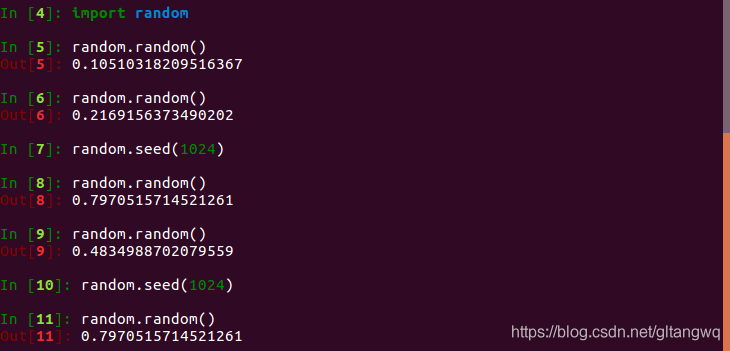
当用户未指定随机种子, 系统默认随机生成, 一般与系统当前时间有关.用户指定随机种子后, 使用随机函数产生的随机数可以复现.种子确定后, 每次使用随机函数相当于从随机序列去获取随机数, 每次获取的随机数是不同的.
pytorch
使用pytorch复现效果时, 总是无法做到完全的复现. 同一份代码运行两次, 有时结果差异很大. 这是由于算法中的随机性导致的. 要想每次获得的结果一致, 必须固定住随机种子. 首先, 我们需要找到算法在哪里使用了随机性, 再相应的固定住随机种子.
def seed_torch():seed = 1024 # 用户设定 # seed = int(time.time()*256) # 保存随机种子 with open(’seed.txt’, ’w’) as f: f.write(str(seed)) random.seed(seed) os.environ[’PYTHONHASHSEED’] = str(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.cuda.manual_seed_all(seed) torch.backends.cudnn.benchmark = False torch.backends.cudnn.deterministic = Trueseed_torch()
上面的代码固定了pytorch常用的随机种子, 但是如果你在预处理中涉及了随机性, 也需要固定住.
为了复现结果, 我们固定住了随机种子. 但pytorch训练模型时, 不同的随机种子会产生不同的结果. 每次使用固定的随机种子, 可能错失好的结果. 为此, 我们可以每次使用不一样的随机种子, 并保存下来
到此这篇关于简述python&pytorch 随机种子的实现的文章就介绍到这了,更多相关pytorch 随机种子内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
 网公网安备
网公网安备