详解用Python爬虫获取百度企业信用中企业基本信息
一、背景
希望根据企业名称查询其经纬度,所在的省份、城市等信息。直接将企业名称传给百度地图提供的API,得到的经纬度是非常不准确的,因此希望获取企业完整的地理位置,这样传给API后结果会更加准确。百度企业信用提供了企业基本信息查询的功能。希望通过Python爬虫获取企业基本信息。目前已基本实现了这一需求。本文最后会提供具体的代码。代码仅供学习参考,希望不要恶意爬取数据!
二、分析
以苏宁为例。输入“江苏苏宁”后,查询结果如下:
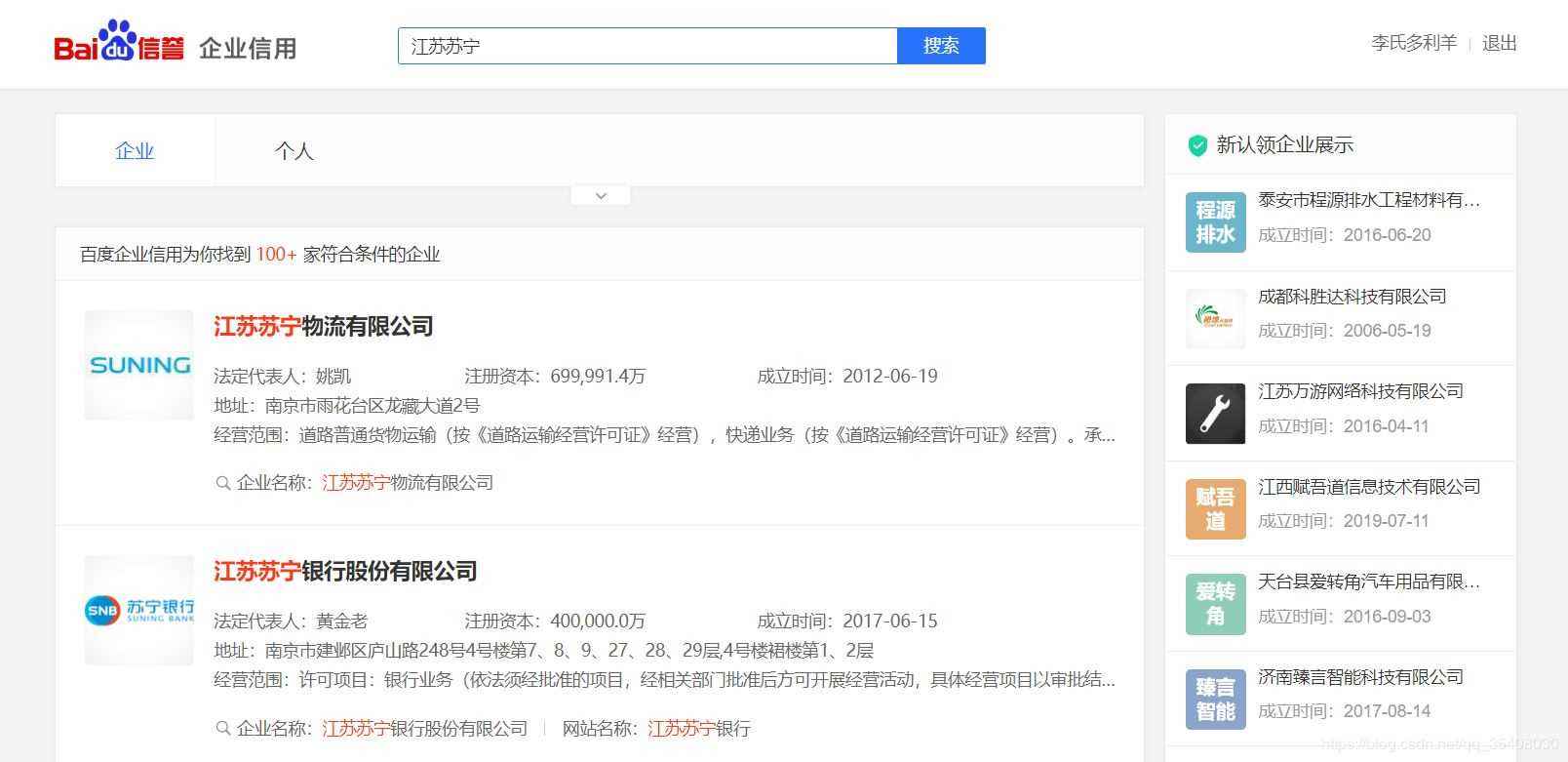
经过分析,这里列示的企业信息是用JavaScript动态生成的。服务器最初传过来的未经渲染的HTML如下:
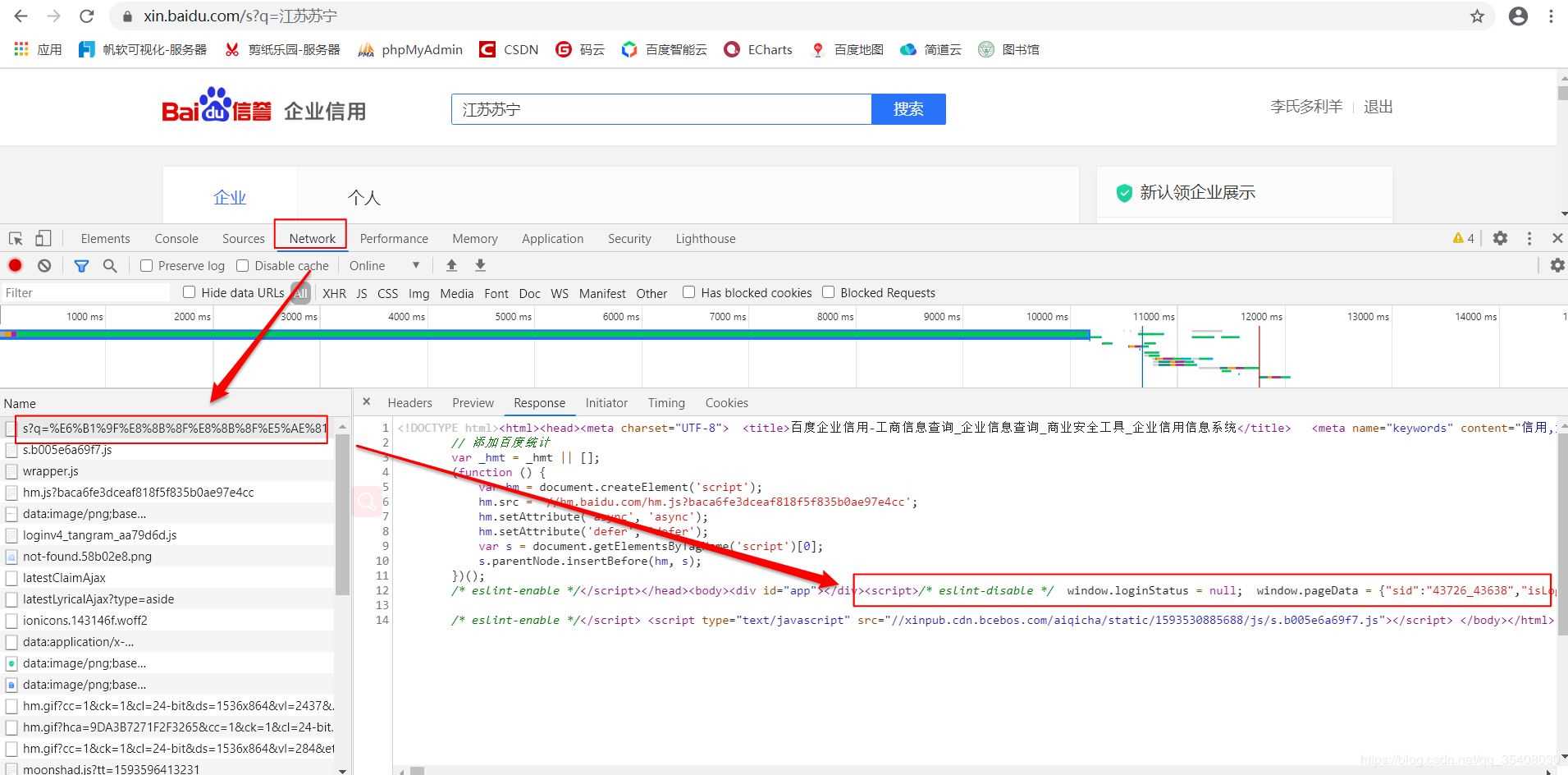
注意其中标注出来的JS代码。有意思的是,企业基本信息都可以直接从这段JS代码中获取,无需构造复杂的参数。

这是进一步查看的结果,注意那个“resultList”,后面存放的就是页面中的企业信息。显然,利用正则表达式提取需要的字符串,转换成JSON就可以了。
三、源码
以下代码为查询某个企业的基本信息提供了API:
#!/usr/bin/env python# -*- coding:utf-8 -*-# @Author: Wild Orange# @Email: jixuanfan_seu@163.com# @Date: 2020-06-19 22:38:14# @Last Modified time: 2020-07-01 17:33:13import requestsimport reimport jsonheaders={’User-Agent’: ’Chrome/76.0.3809.132’}#正则表达式提取数据re_get_js=re.compile(r’<script>([sS]*?)</script>’)re_resultList=re.compile(r’'resultList':([{.+?}]}])’)def Get_company_info(name):’’’@func: 通过百度企业信用查询企业基本信息’’’url=’https://xin.baidu.com/s?q=%s’%nameres=requests.get(url,headers=headers)if res.status_code==200:html=res.textretVal=_parse_baidu_company_info(html)return retValelse:print(’无法获取%s的企业信息’%name)def _parse_baidu_company_info(html):’’’@function:解析百度企业信用提供的企业基本信息@output: list of dict, [{},{},...]pid: 跳转到具体企业页面的参数bid: 具体企业页面URL中的参数name: 企业名称type: 企业类型date: 成立日期address: 地址person: 法人代表status: 存续状态regCap: 注册资本scope: 经营范围’’’js=re_get_js.findall(html)[1]data=re_resultList.search(js)if not data:returncompant_list=json.loads(data.group(1))retVal=[]for x in compant_list:regCap=x[’regCap’].replace(’,’,’’)if regCap[-1]==’万’:regCap=regCap[:-1]regCap=float(regCap)address=x[’domicile’].replace(’<em>’,’’).replace(’</em>’,’’)temp_v={’pid’:x[’pid’],’bid’:x[’bid’],’name’:x[’titleName’],’type’:x[’entType’],’date’:x[’validityFrom’],’address’:address,’person’:x[’legalPerson’],’status’:x[’openStatus’],’regCap’:regCap,’scope’:x[’scope’]}retVal.append(temp_v)return retVal
四、使用方法
直接将需要查询的企业名称传入Get_company_info:
res=Get_company_info(’江苏苏宁’)print(res)
结果:

需要注意的是:
返回的是字典构成的数组,每个字典元素代表一家企业的信息。顺序与浏览器中显示的顺序相同。字典中参数的含义已在_parse_baidu_company_info函数的注释中说明。程序仅获取第一页的信息。如果要查询多页,可以修改源码。程序仅获取企业的基本信息,没有进入企业的具体页面,如:苏宁物流具体页面。不过返回结果中的pid或bid应该能用于构造查询页面的URL。
最后再次强调:代码仅供学习参考,希望不要恶意爬取数据!
到此这篇关于详解用Python爬虫获取百度企业信用中企业基本信息的文章就介绍到这了,更多相关Python爬虫获取百度企业信用内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
 网公网安备
网公网安备