python初步实现word2vec操作
一、前言
一开始看到word2vec环境的安装还挺复杂的,安了半天Cygwin也没太搞懂。后来突然发现,我为什么要去安c语言版本的呢,我应该去用python版本的,然后就发现了gensim,安装个gensim的包就可以用word2vec了,不过gensim只实现了word2vec里面的skip-gram模型。若要用到其他模型,就需要去研究其他语言的word2vec了。
二、语料准备
有了gensim包之后,看了网上很多教程都是直接传入一个txt文件,但是这个txt文件长啥样,是什么样的数据格式呢,很多博客都没有说明,也没有提供可以下载的txt文件作为例子。进一步理解之后发现这个txt是一个包含巨多文本的分好词的文件。如下图所示,是我自己训练的一个语料,我选取了自己之前用爬虫抓取的7000条新闻当做语料并进行分词。注意,词与词之间一定要用空格:
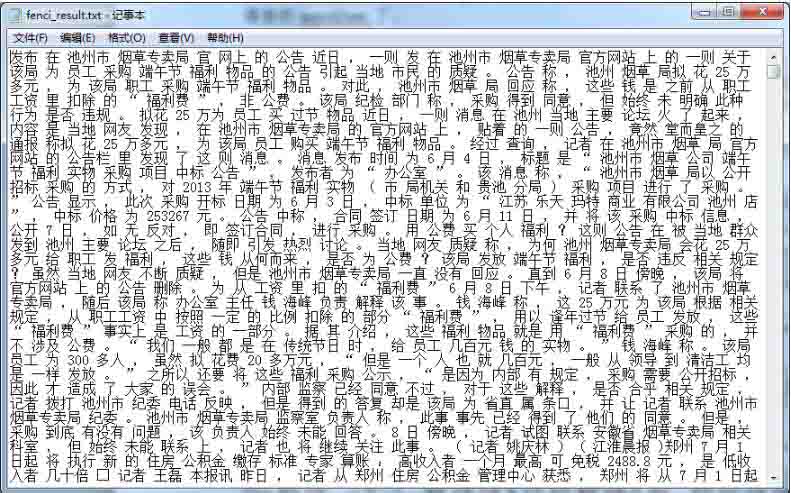
这里分词使用的是结巴分词。
这部分代码如下:
import jiebaf1 =open('fenci.txt')f2 =open('fenci_result.txt', ’a’)lines =f1.readlines() # 读取全部内容for line in lines: line.replace(’t’, ’’).replace(’n’, ’’).replace(’ ’,’’) seg_list = jieba.cut(line, cut_all=False) f2.write(' '.join(seg_list)) f1.close()f2.close()
还要注意的一点就是语料中的文本一定要多,看网上随便一个语料都是好几个G,而且一开始我就使用了一条新闻当成语料库,结果很不好,输出都是0。然后我就用了7000条新闻作为语料库,分词完之后得到的fenci_result.txt是20M,虽然也不大,但是已经可以得到初步结果了。
三、使用gensim的word2vec训练模型
相关代码如下:
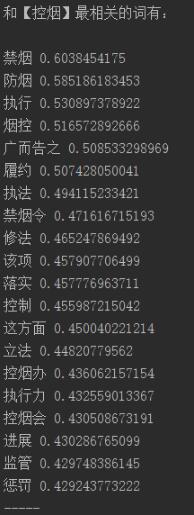
from gensim.modelsimport word2vecimport logging # 主程序logging.basicConfig(format=’%(asctime)s:%(levelname)s: %(message)s’, level=logging.INFO)sentences =word2vec.Text8Corpus(u'fenci_result.txt') # 加载语料model =word2vec.Word2Vec(sentences, size=200) #训练skip-gram模型,默认window=5 print model# 计算两个词的相似度/相关程度try: y1 = model.similarity(u'国家', u'国务院')except KeyError: y1 = 0print u'【国家】和【国务院】的相似度为:', y1print'-----n'## 计算某个词的相关词列表y2 = model.most_similar(u'控烟', topn=20) # 20个最相关的print u'和【控烟】最相关的词有:n'for item in y2: print item[0], item[1]print'-----n' # 寻找对应关系print u'书-不错,质量-'y3 =model.most_similar([u’质量’, u’不错’], [u’书’], topn=3)for item in y3: print item[0], item[1]print'----n' # 寻找不合群的词y4 =model.doesnt_match(u'书 书籍 教材 很'.split())print u'不合群的词:', y4print'-----n' # 保存模型,以便重用model.save(u'书评.model')# 对应的加载方式# model_2 =word2vec.Word2Vec.load('text8.model') # 以一种c语言可以解析的形式存储词向量#model.save_word2vec_format(u'书评.model.bin', binary=True)# 对应的加载方式# model_3 =word2vec.Word2Vec.load_word2vec_format('text8.model.bin',binary=True)
输出如下:
'D:program filespython2.7.0python.exe' 'D:/pycharm workspace/毕设/cluster_test/word2vec.py'D:program filespython2.7.0libsite-packagesgensimutils.py:840: UserWarning: detected Windows; aliasing chunkize to chunkize_serial warnings.warn('detected Windows; aliasing chunkize to chunkize_serial')D:program filespython2.7.0libsite-packagesgensimutils.py:1015: UserWarning: Pattern library is not installed, lemmatization won’t be available. warnings.warn('Pattern library is not installed, lemmatization won’t be available.')2016-12-12 15:37:43,331: INFO: collecting all words and their counts2016-12-12 15:37:43,332: INFO: PROGRESS: at sentence #0, processed 0 words, keeping 0 word types2016-12-12 15:37:45,236: INFO: collected 99865 word types from a corpus of 3561156 raw words and 357 sentences2016-12-12 15:37:45,236: INFO: Loading a fresh vocabulary2016-12-12 15:37:45,413: INFO: min_count=5 retains 29982 unique words (30% of original 99865, drops 69883)2016-12-12 15:37:45,413: INFO: min_count=5 leaves 3444018 word corpus (96% of original 3561156, drops 117138)2016-12-12 15:37:45,602: INFO: deleting the raw counts dictionary of 99865 items2016-12-12 15:37:45,615: INFO: sample=0.001 downsamples 29 most-common words2016-12-12 15:37:45,615: INFO: downsampling leaves estimated 2804247 word corpus (81.4% of prior 3444018)2016-12-12 15:37:45,615: INFO: estimated required memory for 29982 words and 200 dimensions: 62962200 bytes2016-12-12 15:37:45,746: INFO: resetting layer weights2016-12-12 15:37:46,782: INFO: training model with 3 workers on 29982 vocabulary and 200 features, using sg=0 hs=0 sample=0.001 negative=5 window=52016-12-12 15:37:46,782: INFO: expecting 357 sentences, matching count from corpus used for vocabulary survey2016-12-12 15:37:47,818: INFO: PROGRESS: at 1.96% examples, 267531 words/s, in_qsize 6, out_qsize 02016-12-12 15:37:48,844: INFO: PROGRESS: at 3.70% examples, 254229 words/s, in_qsize 3, out_qsize 12016-12-12 15:37:49,871: INFO: PROGRESS: at 5.99% examples, 273509 words/s, in_qsize 3, out_qsize 12016-12-12 15:37:50,867: INFO: PROGRESS: at 8.18% examples, 281557 words/s, in_qsize 6, out_qsize 02016-12-12 15:37:51,872: INFO: PROGRESS: at 10.20% examples, 280918 words/s, in_qsize 5, out_qsize 02016-12-12 15:37:52,898: INFO: PROGRESS: at 12.44% examples, 284750 words/s, in_qsize 6, out_qsize 02016-12-12 15:37:53,911: INFO: PROGRESS: at 14.17% examples, 278948 words/s, in_qsize 0, out_qsize 02016-12-12 15:37:54,956: INFO: PROGRESS: at 16.47% examples, 284101 words/s, in_qsize 2, out_qsize 12016-12-12 15:37:55,934: INFO: PROGRESS: at 18.60% examples, 285781 words/s, in_qsize 6, out_qsize 12016-12-12 15:37:56,933: INFO: PROGRESS: at 20.84% examples, 288045 words/s, in_qsize 6, out_qsize 02016-12-12 15:37:57,973: INFO: PROGRESS: at 23.03% examples, 289083 words/s, in_qsize 6, out_qsize 22016-12-12 15:37:58,993: INFO: PROGRESS: at 24.87% examples, 285990 words/s, in_qsize 6, out_qsize 12016-12-12 15:38:00,006: INFO: PROGRESS: at 27.17% examples, 288266 words/s, in_qsize 4, out_qsize 12016-12-12 15:38:01,081: INFO: PROGRESS: at 29.52% examples, 290197 words/s, in_qsize 1, out_qsize 22016-12-12 15:38:02,065: INFO: PROGRESS: at 31.88% examples, 292344 words/s, in_qsize 6, out_qsize 02016-12-12 15:38:03,188: INFO: PROGRESS: at 34.01% examples, 291356 words/s, in_qsize 2, out_qsize 22016-12-12 15:38:04,161: INFO: PROGRESS: at 36.02% examples, 290805 words/s, in_qsize 6, out_qsize 02016-12-12 15:38:05,174: INFO: PROGRESS: at 38.26% examples, 292174 words/s, in_qsize 3, out_qsize 02016-12-12 15:38:06,214: INFO: PROGRESS: at 40.56% examples, 293297 words/s, in_qsize 4, out_qsize 12016-12-12 15:38:07,201: INFO: PROGRESS: at 42.69% examples, 293428 words/s, in_qsize 4, out_qsize 12016-12-12 15:38:08,266: INFO: PROGRESS: at 44.65% examples, 292108 words/s, in_qsize 1, out_qsize 12016-12-12 15:38:09,295: INFO: PROGRESS: at 46.83% examples, 292097 words/s, in_qsize 4, out_qsize 12016-12-12 15:38:10,315: INFO: PROGRESS: at 49.13% examples, 292968 words/s, in_qsize 2, out_qsize 22016-12-12 15:38:11,326: INFO: PROGRESS: at 51.37% examples, 293621 words/s, in_qsize 5, out_qsize 02016-12-12 15:38:12,367: INFO: PROGRESS: at 53.39% examples, 292777 words/s, in_qsize 2, out_qsize 22016-12-12 15:38:13,348: INFO: PROGRESS: at 55.35% examples, 292187 words/s, in_qsize 5, out_qsize 02016-12-12 15:38:14,349: INFO: PROGRESS: at 57.31% examples, 291656 words/s, in_qsize 6, out_qsize 02016-12-12 15:38:15,374: INFO: PROGRESS: at 59.50% examples, 292019 words/s, in_qsize 6, out_qsize 02016-12-12 15:38:16,403: INFO: PROGRESS: at 61.68% examples, 292318 words/s, in_qsize 4, out_qsize 22016-12-12 15:38:17,401: INFO: PROGRESS: at 63.81% examples, 292275 words/s, in_qsize 6, out_qsize 02016-12-12 15:38:18,410: INFO: PROGRESS: at 65.71% examples, 291495 words/s, in_qsize 4, out_qsize 12016-12-12 15:38:19,433: INFO: PROGRESS: at 67.62% examples, 290443 words/s, in_qsize 6, out_qsize 02016-12-12 15:38:20,473: INFO: PROGRESS: at 69.58% examples, 289655 words/s, in_qsize 6, out_qsize 22016-12-12 15:38:21,589: INFO: PROGRESS: at 71.71% examples, 289388 words/s, in_qsize 2, out_qsize 22016-12-12 15:38:22,533: INFO: PROGRESS: at 73.78% examples, 289366 words/s, in_qsize 0, out_qsize 12016-12-12 15:38:23,611: INFO: PROGRESS: at 75.46% examples, 287542 words/s, in_qsize 5, out_qsize 12016-12-12 15:38:24,614: INFO: PROGRESS: at 77.25% examples, 286609 words/s, in_qsize 3, out_qsize 02016-12-12 15:38:25,609: INFO: PROGRESS: at 79.33% examples, 286732 words/s, in_qsize 5, out_qsize 12016-12-12 15:38:26,621: INFO: PROGRESS: at 81.40% examples, 286595 words/s, in_qsize 2, out_qsize 02016-12-12 15:38:27,625: INFO: PROGRESS: at 83.53% examples, 286807 words/s, in_qsize 6, out_qsize 02016-12-12 15:38:28,683: INFO: PROGRESS: at 85.32% examples, 285651 words/s, in_qsize 5, out_qsize 32016-12-12 15:38:29,729: INFO: PROGRESS: at 87.56% examples, 286175 words/s, in_qsize 6, out_qsize 12016-12-12 15:38:30,706: INFO: PROGRESS: at 89.86% examples, 286920 words/s, in_qsize 5, out_qsize 02016-12-12 15:38:31,714: INFO: PROGRESS: at 92.10% examples, 287368 words/s, in_qsize 6, out_qsize 02016-12-12 15:38:32,756: INFO: PROGRESS: at 94.40% examples, 288070 words/s, in_qsize 4, out_qsize 22016-12-12 15:38:33,755: INFO: PROGRESS: at 96.30% examples, 287543 words/s, in_qsize 1, out_qsize 02016-12-12 15:38:34,802: INFO: PROGRESS: at 98.71% examples, 288375 words/s, in_qsize 4, out_qsize 02016-12-12 15:38:35,286: INFO: worker thread finished; awaiting finish of 2 more threads2016-12-12 15:38:35,286: INFO: worker thread finished; awaiting finish of 1 more threadsWord2Vec(vocab=29982, size=200, alpha=0.025)【国家】和【国务院】的相似度为: 0.387535493256-----2016-12-12 15:38:35,293: INFO: worker thread finished; awaiting finish of 0 more threads2016-12-12 15:38:35,293: INFO: training on 17805780 raw words (14021191 effective words) took 48.5s, 289037 effective words/s2016-12-12 15:38:35,293: INFO: precomputing L2-norms of word weight vectors和【控烟】最相关的词有:禁烟 0.6038454175防烟 0.585186183453执行 0.530897378922烟控 0.516572892666广而告之 0.508533298969履约 0.507428050041执法 0.494115233421禁烟令 0.471616715193修法 0.465247869492该项 0.457907706499落实 0.457776963711控制 0.455987215042这方面 0.450040221214立法 0.44820779562控烟办 0.436062157154执行力 0.432559013367控烟会 0.430508673191进展 0.430286765099监管 0.429748386145惩罚 0.429243773222-----书-不错,质量-生存 0.613928854465稳定 0.595371186733整体 0.592055797577----不合群的词: 很-----2016-12-12 15:38:35,515: INFO: saving Word2Vec object under 书评.model, separately None2016-12-12 15:38:35,515: INFO: not storing attribute syn0norm2016-12-12 15:38:35,515: INFO: not storing attribute cum_table2016-12-12 15:38:36,490: INFO: saved 书评.modelProcess finished with exit code 0


以上这篇python初步实现word2vec操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持好吧啦网。
相关文章:
1. IntelliJ IDEA设置条件断点的方法步骤2. IntelliJ IDEA导出项目的方法3. IDEA 2020.3.X 创建scala环境的详细教程4. 解决SpringBoot返回结果如果为null或空值不显示处理问题5. 史上最佳springboot Locale 国际化方案6. python中逻辑与或(and、or)和按位与或异或(&、|、^)区别7. vue将文件/图片批量打包下载zip的教程8. Springboot集成spring data elasticsearch过程详解9. Android自定义控件实现通用验证码输入框10. 图解Python中深浅copy(通俗易懂)

 网公网安备
网公网安备