Python ADF 单位根检验 如何查看结果的实现
如下所示:
from statsmodels.tsa.stattools import adfuller
print(adfuller(data))
(-8.14089819118415, 1.028868757881713e-12, 8, 442, {’1%’: -3.445231637930579, ’5%’: -2.8681012763264233, ’10%’: -2.5702649212751583}, -797.2906467666614)
第一个是adt检验的结果,简称为T值,表示t统计量。
第二个简称为p值,表示t统计量对应的概率值。
第三个表示延迟。
第四个表示测试的次数。
第五个是配合第一个一起看的,是在99%,95%,90%置信区间下的临界的ADF检验的值。
第一点,1%、%5、%10不同程度拒绝原假设的统计值和ADF Test result的比较,ADF Test result同时小于1%、5%、10%即说明非常好地拒绝该假设。本数据中,adf结果为-8, 小于三个level的统计值
第二点,p值要求小于给定的显著水平,p值要小于0.05,等于0是最好的。本数据中,P-value 为 1e-15,接近0.
ADF检验的原假设是存在单位根,只要这个统计值是小于1%水平下的数字就可以极显著的拒绝原假设,认为数据平稳。注意,ADF值一般是负的,也有正的,但是它只有小于1%水平下的才能认为是及其显著的拒绝原假设。
对于ADF结果在1% 以上 5%以下的结果,也不能说不平稳,关键看检验要求是什么样子的。
补充知识:python 编写ADF 检验 ,代码结果参数所表示的含义
我就废话不多说了,大家还是直接看代码吧!
from statsmodels.tsa.stattools import adfullerimport numpy as npimport pandas as pdadf_seq = np.array([1,2,3,4,5,7,5,1,54,3,6,87,45,14,24])dftest = adfuller(adf_seq,autolag=’AIC’)dfoutput = pd.Series(dftest[0:4],index=[’Test Statistic’,’p-value’,’#Lags Used’,’Number of Observations Used’])# 第一种显示方式for key,value in dftest[4].items():dfoutput[’Critical Value (%s)’ % key] = valueprint(dfoutput)# 第二种显示方式print(dftest)
(1)第一种显示方式如图所示:
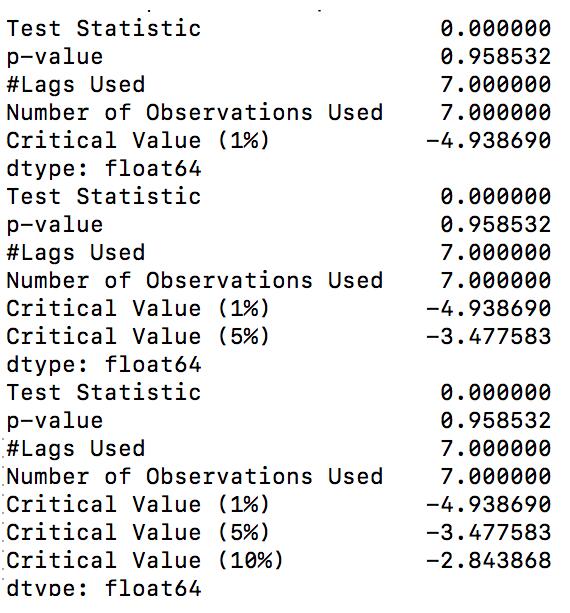
具体的参数含义如下所示:
Test Statistic : T值,表示T统计量
p-value: p值,表示T统计量对应的概率值
Lags Used:表示延迟
Number of Observations Used: 表示测试的次数
Critical Value 1% : 表示t值下小于 - 4.938690 , 则原假设发生的概率小于1%, 其它的数值以此类推。
其中t值和p值是最重要的,其实这两个值是等效的,既可以看t值也可以看p值。
p值越小越好,要求小于给定的显著水平,p值小于0.05,等于0最好。
t值,ADF值要小于t值,1%, 5%, 10% 的三个level,都是一个临界值,如果小于这个临界值,说明拒绝原假设。
其中,1% : 严格拒绝原假设; 5%: 拒绝原假设; 10% 以此类推,程度越来越低。如果,ADF小于1% level, 说明严格拒绝原假设。
(2)第二种表示方式,如下图所示:
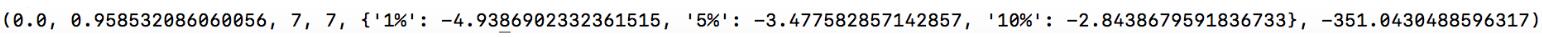
第一个值(0.0): 表示Test Statistic , 即T值,表示T统计量
第二个值(0.958532086060056):p-value,即p值,表示T统计量对应的概率值
第三个值(7):Lags Used,即表示延迟
第四个值(7):Number of Observations Used,即表示测试的次数
大括号中的值,分别表示1%, 5%, 10% 的三个level
查阅了资料,简单的做的总结经验。
以上这篇Python ADF 单位根检验 如何查看结果的实现就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持好吧啦网。
相关文章:

 网公网安备
网公网安备