Python 实现敏感目录扫描的示例代码
01 实现背景
1、PHPdict.txt,一个文本文件,包含可能的敏感目录后缀
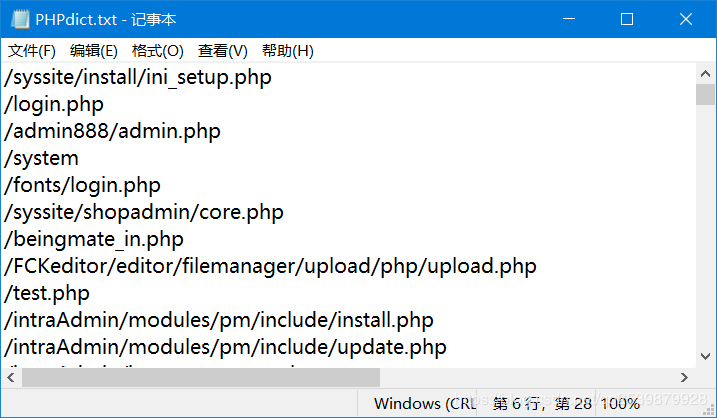
2、HackRequests模块,安全测试人员专用的类Requests模块
02 实现目标
利用HackRequests模块,配合敏感目录字典PHPdict.txt,实现一个简单的敏感目录扫描Python文件
03 注意事项
1、输入URL时要输全:如 https://www.baidu.com/、 https://www.csdn.net/
2、为防止网站可能存在的简单反爬机制,我们简单添加headers信息,尝试绕过反爬
04 实现代码
import HackRequestsdef HR(url): h = HackRequests.hackRequests() header = { 'Connection': 'keep-alive', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0' } try: u = h.http(url=url,headers=header) if u.status_code == 200: print('%s is success!' %url) else: print('%s is failed! %d' %(url,u.status_code)) except: passwith open('C:UsersDellDesktopPythonPHPdict.txt','r') as file: lines = file.readlines() urls = [] url_begin = input(’请输入你要扫描的网站:’) for line in lines: url = f’{url_begin}{line}’ urls.append(url)for url in urls: print(url) HR(url)
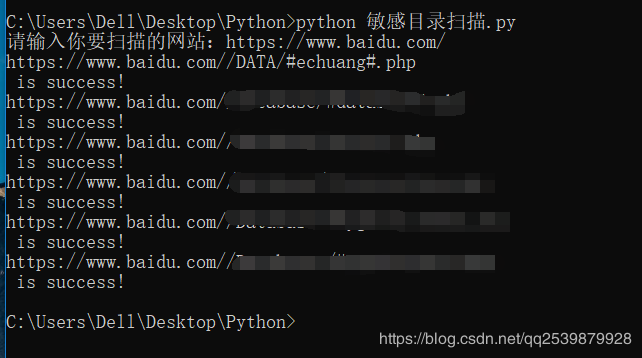
05 实现效果
总结
到此这篇关于Python 实现敏感目录扫描的示例代码的文章就介绍到这了,更多相关python 敏感目录扫描内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:

 网公网安备
网公网安备