python异常处理之try finally不报错的原因
因为有把python程序打包成exe的需求,所以,有了如下的代码
import timeclass LoopOver(Exception): def __init__(self, *args, **kwargs): passclass Spider: def __init__(self): super().__init__() def run(self): raise LoopOver @property def time(self): return ’总共用时:{}秒’.format(self.runtime)if __name__ == ’__main__’: try: spider = Spider() spider.run() print(spider.time) # 运行总时间 finally: print(’死掉了’) time.sleep(60 * 60)
但是遇到了一个问题
程序显示“死掉后”并不会显示堆栈的错误信息
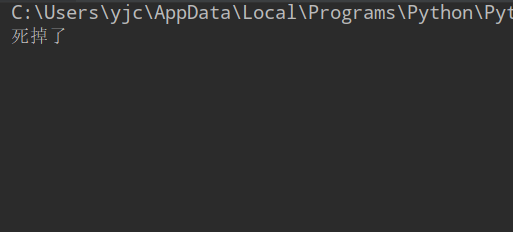
排查后发现,程序打印“堆栈的错误信息”并不是异步的,“堆栈的错误信息”会等到finally内的代码块执行完毕后才会输出
所以,把代码块改一下,需要导入traceback库来跟踪堆栈的错误信息如下所示
import timeimport tracebackclass LoopOver(Exception): def __init__(self, *args, **kwargs): passclass Spider: def __init__(self): super().__init__() def run(self): raise LoopOver @property def time(self): return ’总共用时:{}秒’.format(self.runtime)if __name__ == ’__main__’: try: spider = Spider() spider.run() print(spider.time) # 运行总时间 finally: traceback.print_exc() print(’死掉了’) time.sleep(60 * 60)
这种打印方式是异步的,不知道是多线程还是协程还是啥
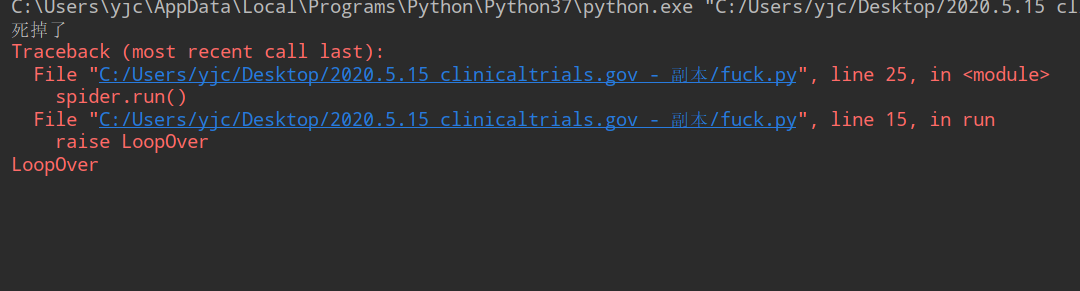
更多追踪堆栈错误信息的,可以看这篇文章Python捕获异常堆栈信息的几种方法
到此这篇关于python异常处理之try finally不报错的原因的文章就介绍到这了,更多相关python try finally不报错内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:

 网公网安备
网公网安备