Python实现多线程下载脚本的示例代码
0x01 分析
一个简单的多线程下载资源的Python脚本,主要实现部分包含两个类:
Download类:包含download()和get_complete_rate()两种方法。
download()方法种首先用 urlopen() 方法打开远程资源并通过 Content-Length获取资源的大小,然后计算每个线程应该下载网络资源的大小及对应部分吗,最后依次创建并启动多个线程来下载网络资源的指定部分。 get_complete_rate()则是用来返回已下载的部分占全部资源大小的比例,用来回显进度。ThreadDownload类:该线程类继承了threading.Thread类,包含了一个run()方法。
run()方法主要负责每个线程读取网络数据并写入本地。
0x02 代码
# 文件名:ThreadDownload.pyimport threadingfrom urllib.request import *class Download: def __init__(self, link, file_path, thread_num): # 下载路径 self.link = link # 保存位置 self.file_path = file_path # 使用多少线程 self.thread_num = thread_num # 初始化threads数组 self.threads = [] def download(self): req = Request(url=self.link, method=’GET’) req.add_header(’Accept’, ’*/*’) req.add_header(’Charset’, ’UTF-8’) req.add_header(’Connection’, ’Keep-Alive’) f = urlopen(req) # 获取要下载的文件的大小 self.file_size = int(dict(f.headers).get(’Content-Length’, 0)) f.close() # 计算每个线程要下载的资源的大小 current_part_size = self.file_size // self.thread_num + 1 for i in range(self.thread_num): # 计算每个线程下载的开始位置 start_pos = i * current_part_size # 每个线程使用一个wb模式打开的文件进行下载 t = open(self.file_path, ’wb’) t.seek(start_pos, 0) # 创建下载线程 td = ThreadDownload(self.link, start_pos, current_part_size, t) self.threads.append(td) td.start() # 获下载的完成百分比 def get_complete_rate(self): sum_size = 0 for i in range(self.thread_num): sum_size += self.threads[i].length return sum_size / self.file_sizeclass ThreadDownload(threading.Thread): def __init__(self, link, start_pos, current_part_size, current_part): super().__init__() # 下载路径 self.link = link # 当前线程的下载位置 self.start_pos = start_pos # 定义当前线程负责下载的文件大小 self.current_part_size = current_part_size # 当前文件需要下载的文件快 self.current_part = current_part # 定义该线程已经下载的字节数 self.length = 0 def run(self): req = Request(url = self.link, method=’GET’) req.add_header(’Accept’, ’*/*’) req.add_header(’Charset’, ’UTF-8’) req.add_header(’Connection’, ’Keep-Alive’) f = urlopen(req) # 跳过self.start_pos个字节,表明该线程只负责下载自己负责的那部分内容 for i in range(self.start_pos): f.read(1) # 读取网络数据,并写入本地 while self.length < self.current_part_size: data = f.read(1024) if data is None or len(data) <= 0:break self.current_part.write(data) # 累计该线程下载的总大小 self.length += len(data) self.current_part.close() f.close()
#!/usr/bin/env python # -*- coding: utf-8 -*- # 文件名:thread_download-master.pyimport sysimport timefrom ThreadDownload import *def show_process(dl): while dl.get_complete_rate() < 1: complete_rate = int(dl.get_complete_rate()*100) print(’r’ + ’下载中···(已下载’ + str(complete_rate) + ’%)’, end=’’, flush=True) time.sleep(0.01)def main(): try: Link = input(’[+]’ + ’Link: ’) file_path = input(’[+]’ + ’File Path: ’) thread_number = input(’[+]’ + ’Thread Number: ’) thread_number = int(thread_number) dl = Download(Link, file_path, thread_number) dl.download() print(’n开始下载!’) show_process(dl) print(’r’ + ’下载中···(已下载’ + ’100%)’, end=’’, flush=True) print(’n下载完成!’) except Exception: print(’Parameter Setting Error’) sys.exit(1)if __name__==’__main__’: main()
0x03 运行结果
下载歌曲《男孩》为例,下载到./Download/目录下并命名为男孩.mp3,设置5个线程:
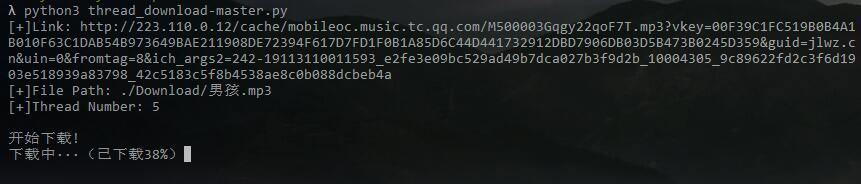
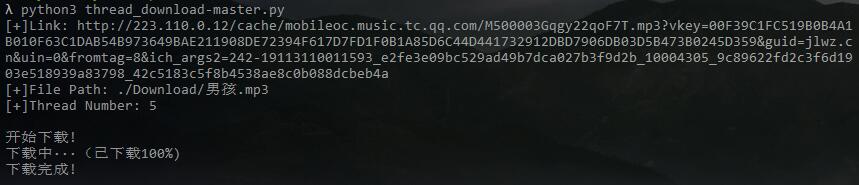
下载成功:

到此这篇关于Python实现多线程下载脚本的示例代码的文章就介绍到这了,更多相关Python 多线程下载脚本内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:

 网公网安备
网公网安备