python-xpath获取html文档的部分内容
有些时候我在们需要的用正则提取出html中某一个部分的文字内容,如图:
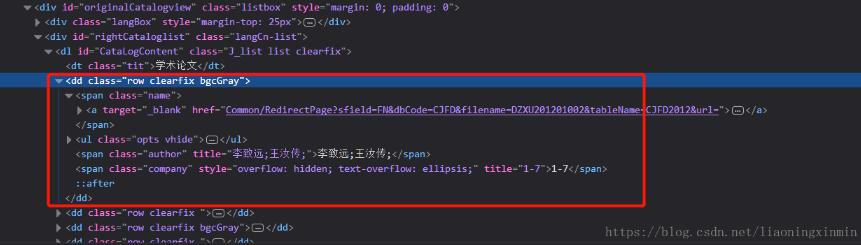
获取dd部分的html文档,我们要通过它的一个属性去确定他的位置才可以拿到他这个部分我们可以看到他的这个属性class=’row clearfix ’,然后用xpath去获取到这部分:
name = tree.xpath('//dd[@class=’row clearfix ’]')from lxml import htmlimport requestsurl = ’http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD’res = requests.get(url)tree = html.fromstring(res.text)name = tree.xpath('//dd[@class=’row clearfix ’]')print(name)
如果直接打印他是不能够出来的,

我们需要对Element进行处理,用到name1 = html.tostring(name[0]),代码如下:
from lxml import htmlimport requestsurl = ’http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD’res = requests.get(url)tree = html.fromstring(res.text)name = tree.xpath('//dd[@class=’row clearfix ’]')name1 = html.tostring(name[0])print(name1)
打印截图:

但是大家可以看到里面的等内容并不是中文,原因是我们使用tostring方法输出的是修正后的HTML代码,但是结果是bytes类型,在python中bytes类型是不可以进行编码的,需要转换成字符串,使用代码name1.decode(),此时我们将bytes类型转换为str(字符串)类型。
那么此时我们关键是如何将$#26080;此类的符号转换成汉字!!!那么首先要搞清楚这是什么编码?这类符号是HTML、XML 等 SGML 类语言的转义序列。它们不是”编码“,也就是说我们不能使用utf-8、gbk等编码进行处理,需要使用HTMLParse进行处理,完整代码如下:
from lxml import htmlimport requestsfrom html.parser import HTMLParser #导入html解析库url = ’http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD’res = requests.get(url)tree = html.fromstring(res.text)name = tree.xpath('//dd[@class=’row clearfix ’]')name1 = html.tostring(name[0])name2 = HTMLParser().unescape(name1.decode())print(name2)
此时运行结果如下:

那么此时就已经大功告成了!!!
以上这篇python-xpath获取html文档的部分内容就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持好吧啦网。
相关文章:

 网公网安备
网公网安备