Java 实现LZ78压缩算法的示例代码
通过多路搜索树提高检索速度
package com.wretchant.lz78;import java.util.*;/** 多路英文单词查找树 */class Trie { private TrieNode root; public Trie() {root = new TrieNode();root.wordEnd = false; } public void insert(String word) {TrieNode node = root;for (int i = 0; i < word.length(); i++) { Character c = word.charAt(i); if (!node.childdren.containsKey(c)) {node.childdren.put(c, new TrieNode()); } node = node.childdren.get(c);}node.wordEnd = true; } public boolean search(String word) {TrieNode node = root;for (int i = 0; i < word.length(); i++) { Character c = word.charAt(i); if (!node.childdren.containsKey(c)) {return false; } node = node.childdren.get(c);}return node.wordEnd; }}class TrieNode { Map<Character, TrieNode> childdren; boolean wordEnd; public TrieNode() {childdren = new HashMap<Character, TrieNode>();wordEnd = false; }}/** 编码表 */class Output { private Integer index; private Character character; Output(Integer index, Character character) {this.index = index;this.character = character; } public Integer getIndex() {return index; } public Character getCharacter() {return character; }}class LZencode { @FunctionalInterface interface Encode {List<Output> encode(String message); } /** 构建多路搜索树 */ static Trie buildTree(Set<String> keys) {Trie trie = new Trie();keys.forEach(trie::insert);return trie; } public static final Encode ENCODE = message -> {// 构建压缩后的编码表List<Output> outputs = new ArrayList<>();Map<String, Integer> treeDict = new HashMap<>();int mLen = message.length();int i = 0;while (i < mLen) { Set<String> keySet = treeDict.keySet(); // 生成多路搜索树 Trie trie = buildTree(keySet); char messageI = message.charAt(i); String messageIStr = String.valueOf(messageI); // 使用多路树进行搜索 if (!trie.search(messageIStr)) {outputs.add(new Output(0, messageI));treeDict.put(messageIStr, treeDict.size() + 1);i++; } else if (i == mLen - 1) {outputs.add(new Output(treeDict.get(messageIStr), ’ ’));i++; } else {for (int j = i + 1; j < mLen; j++) { String substring = message.substring(i, j + 1); String str = message.substring(i, j); // 使用多路树进行搜索 if (!trie.search(substring)) {outputs.add(new Output(treeDict.get(str), message.charAt(j)));treeDict.put(substring, treeDict.size() + 1);i = j + 1;break; } if (j == mLen - 1) {outputs.add(new Output(treeDict.get(substring), ’ ’));i = j + 1; }} }}return outputs; };}2、解压缩算法的实现
package com.wretchant.lz78;import java.util.HashMap;import java.util.List;import java.util.Map;public class LZdecode { @FunctionalInterface interface Decode {/** @param outputs 编码表 @return 解码后的字符串 */String decode(List<Output> outputs); } /** 根据编码表进行解码 */ public static final Decode DECODE = (List<Output> outputs) -> {StringBuilder unpacked = new StringBuilder();Map<Integer, String> treeDict = new HashMap<>();for (Output output : outputs) { Integer index = output.getIndex(); Character character = output.getCharacter(); if (index == 0) {unpacked.append(character);treeDict.put(treeDict.size() + 1, character.toString());continue; } String term = '' + treeDict.get(index) + character; unpacked.append(term); treeDict.put(treeDict.size() + 1, term);}return unpacked.toString(); };}3、测试和使用
package com.wretchant.lz78;import java.io.InputStream;import java.util.List;import java.util.Scanner;import java.util.function.ToIntFunction;public class LZpack { public static final ToIntFunction<List<Output>> DICT_PRINT = outputs -> {outputs.forEach(output -> { System.out.println('index :' + output.getIndex() + ' char :' + output.getCharacter());});return 1; }; public static void main(String[] args) {Scanner scanner = new Scanner(System.in);System.out.println('Please input text ');String input = scanner.nextLine();LZencode.Encode encode = LZencode.ENCODE;List<Output> outputs = encode.encode(input);DICT_PRINT.applyAsInt(outputs); }}
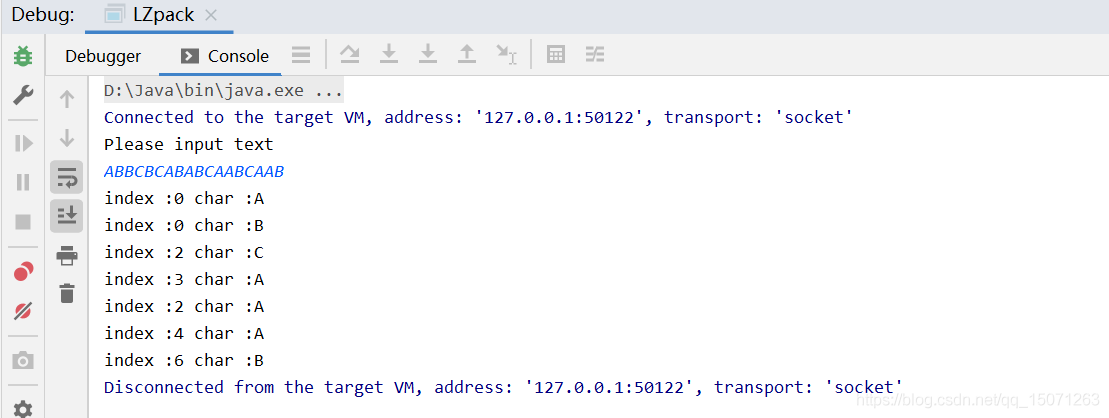
测试结果如下
def compress(message): tree_dict, m_len, i = {}, len(message), 0 while i < m_len:# case Iif message[i] not in tree_dict.keys(): yield (0, message[i]) tree_dict[message[i]] = len(tree_dict) + 1 i += 1# case IIIelif i == m_len - 1: yield (tree_dict.get(message[i]), ’’) i += 1else: for j in range(i + 1, m_len):# case IIif message[i:j + 1] not in tree_dict.keys(): yield (tree_dict.get(message[i:j]), message[j]) tree_dict[message[i:j + 1]] = len(tree_dict) + 1 i = j + 1 break# case IIIelif j == m_len - 1: yield (tree_dict.get(message[i:j + 1]), ’’) i = j + 1def uncompress(packed): unpacked, tree_dict = ’’, {} for index, ch in packed:if index == 0: unpacked += ch tree_dict[len(tree_dict) + 1] = chelse: term = tree_dict.get(index) + ch unpacked += term tree_dict[len(tree_dict) + 1] = term return unpackedif __name__ == ’__main__’: messages = [’ABBCBCABABCAABCAAB’, ’BABAABRRRA’, ’AAAAAAAAA’] for m in messages:pack = compress(m)unpack = uncompress(pack)print(unpack == m)
到此这篇关于Java 实现LZ78压缩算法的文章就介绍到这了,更多相关Java LZ78压缩算法内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
 网公网安备
网公网安备