详解Java中的hashcode
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
这个说的有点官方,你就可以把它简单的理解为一个key,就像是map的key值一样,是不可重复的。
二、hash有什么用?,在什么地方用到?1.在散列表
2.map集合
此处只是做了一个简单的介绍,其实远远没有那么简单,如算法里面的散列表,散列函数,以及map的一个不可重复到底是怎么样去判断的,以及hash冲突的问题,都与hash值离不开关系。
三、java中String类的hashcode方法public int hashCode() {int h = hash;if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) {h = 31 * h + val[i]; } hash = h;}return h; }
可以看到,String类的hashcode方法是通过,char类型的方式进行一个相加,因为String类的底层就是通过char数组来实现的。
如:String str='ab'; 其实就是一个char数组 char[] str={’a’,’b’};
如:字符串 String star=“ab”;那么他对应的hash值就是:3105
怎么算出来的呢?
val[0]=’a’ ; val[1]=’b’
a对应的Ascall码值为:97b对的Ascall码值为:98那么经过如下代码的循环相加
for (int i = 0; i < value.length; i++) { h = 31 * h + val[i];}
得出:97*31+98=3105;
我们再看: int h = hash;这一个代码,为什么有时候调用hashcode方法返回的hash值是负数呢?
因为如果这个字符串很长?那么h的值就会超过int类型的最大值,有没有想过,如果一个int类型的最大值,超过他的范围之后会怎么样呢?
我们先来看这样一个简单的代码:
int count=0; while (true){ if (count++<10){ System.out.println('hello world'); } }
大家认为hello world会输出多少次呢?正常情况来说count小于10就不会输出了对么?但是其实并不是这样的,很明确的告诉大家,这是一个死循环。
因为count一直加,最开始if成立,到后面的if不成立,再到后面if会再次成立,为什么会成立呢?因为count变为了负数。
???? 为什么?因为count一直无限制的加,由于是线性增长,计算速度是非常快的,所以,要不了多久,就会超出int类型的最大值。控制输出的count变为了负数,所以呢此时的if条件又成立了。

首先我们来看下int的范围 :int 为4个字节,一个字节为8位,一个int值是需要的存储空间是32位,但是呢?这是一个有符号位的int,需要一个符号位来表示正数和负数,int值的范围就是:-2^31 ~ 2^31 也就是:-2147483648 到2147483647
我们来看下int最大值对应的二进制位是对少?
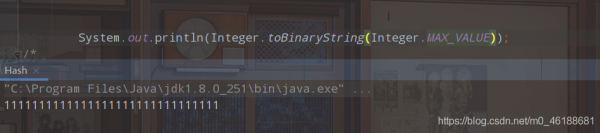
全是1? 2147483647最大值不是一个正数么?难道第一位难道不是应该用0表示么?
此时这个0他是省略掉了没写的,由于二进制系统是通过补码来保存数据的。第一位是符号位,0为正,1为负,当正的除了符号位全为1,再加1就进位了,符号位就会变成1,是负数,其他为0。所以说当int的最大值加一个1,就变为了,最小值
来!口说无凭,没有说服力,我们直接来看代码:
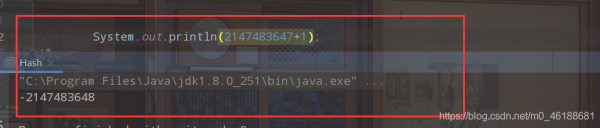
那么我们在反过来想,最小值减1呢?那是不是就是对对应的是我们int类型的最大值了呀?
认真仔细的看完这个,你就知道为什么hashcode方法调用的时候有时候是正数,有时候是负数了吧?所以说底层还是很有意思的,比如往后做大数据开发,那么肯定是需要深入理解这些数据类型的范围,以及他的一个变化规则,否则有时候不知不觉的就犯错了,你还不知道错误在那儿?严重的话就是会损失精度,导致结果和你预期的结果相差甚远。就因为加了个1,就导致结果和预期结果相差十万八千里。
这是String类的hashcode方法的一个具体实现过程。
四、两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?首先呢?这个肯定是不对的。
因为这两个方法都可以重写,如果是自己的类,那么可以灵活重写,如果是jdk自己的类,那就要看他到底有没有重写这两个方法。
我们以String类的equlas方法为例:我们都知道,如果equlas方法如果没有重写,那就继承Object类的equlas方法,默认比较的是两个对象的内存地址,如果重写了,那就根据我们自己重写的规则来比较两个对象是否相等。
如下是jdkString类中自己重写的equals方法,
public boolean equals(Object anObject) { // 如果两个String类型的对象内存地址相等直接返回trueif (this == anObject) { return true;} // 如下做的操作就是比较两个字符串中的每一个char类型的数据,如果都完全匹配,那么就是返回true,如果有一个不相同,直接返回false,并且两个字符串的长度要相等,如果不相同,那么肯定也就不可能值一样了嘛if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) {char v1[] = value;char v2[] = anotherString.value;int i = 0;while (n-- != 0) { if (v1[i] != v2[i])return false; i++;}return true; }}return false; }
再看下String的hashcode方法:就是我们上面刚刚讲过的那个方法
public int hashCode() {int h = hash;if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) {h = 31 * h + val[i]; } hash = h;}return h; }
1:如果两个String类型的对象内存地址相等直接返回true
2:比较两个字符串中的每一个char类型的数据,如果都完全匹配,那么就是返回true,如果有一个不相同,直接返回false,并且两个字符串的长度要相等,如果不相同,那么肯定也就不可能值一样了嘛
由此可以看出,equals方法是否返回true跟hashcode方法没有半毛钱关系嘛。
接下来我们看下,我们自定义的对象,我创建一个User类,里面有属性id和name
public class User { int id; String name; @Override public String toString() {return 'User{' +'id=' + id +', name=’' + name + ’’’ +’}’; }}
在没有重写hashcode方法和equals方法的情况下进行比较:
User user1 = new User();User user2 = new User();System.out.println(user1.hashCode());System.out.println(user2.hashCode());System.out.println(user1.equals(user2));

解答:因为我们没有重写,这两个方法都是继承自Object类的,所以呢?比较的是内存地址,因为我们是通过new的方式去创建的两个user对象,那么他们的内存地址肯定是不相同的,所以直接返回false,而hashcode方法是java的底层语言c++来写的,具体他内部是怎么实现的,封装了,我也就不得而知了,后面再了解,有的人说是跟内存地址相关,但是具体我没有看到具体实现,也不敢苟同,有的东西,需要自己不断的去摸索,自己亲自实践,才是真的,不要相信别人说的。
好的,接下来我们重写User类的hashcode方法:
public class User { int id; String name; @Override public String toString() {return 'User{' +'id=' + id +', name=’' + name + ’’’ +’}’; } @Override public int hashCode() {return Objects.hash(id, name); }}

可以看到的是,我们两个User对象的hashcode方法返回的hash值是完全一致的,但是通过equals方法进行比较,还是false,所以说,两个对象的hashcode方法返回的hash值相同,equlas也一定返回true是完全不成立的,直接推翻。
接下来我们再次重写equlas方法,此时我们规定,只要两个对象的id和name都相同,那么这两个对象就是同一个对象。并且删除掉刚刚我们重写的hashcode方法。
public class User { int id; String name; public User(int i, String name) {this.id = id;this.name = name; } @Override public String toString() {return 'User{' +'id=' + id +', name=’' + name + ’’’ +’}’; } @Override public boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;User user = (User) o;return id == user.id &&name.equals(user.name); }}
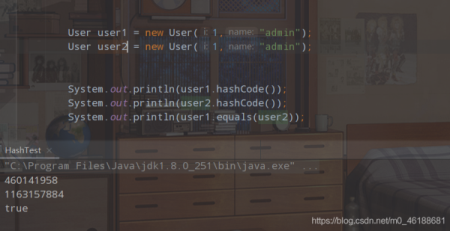
通过运行结果,我们可以看到,hashcode方法返回的hash值不一致,但是我们的equlas方法依旧返回的是true,因为这个equlas方法是我们重写过了,在调用的时候,就不在去掉Object的equlas方法,进行比较内存地址,而是按照我们的重写规则:如果两个user对象的id和name相同,那么就是同一个对象,所以到这里,你是不是就具体的理解了hashcode方法个equlas之间的关系呢?
如果还是不明白,那再看一次,我们现在把User类的equlas方法和hashcode方法都写上,但是呢?我会创建两i不同的User对象(也就是id和name都不一样)。
public class User { int id; String name; public User(int i, String name) {this.id = id;this.name = name; } @Override public String toString() {return 'User{' +'id=' + id +', name=’' + name + ’’’ +’}’; } @Override public boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;User user = (User) o;return id == user.id &&name.equals(user.name); } @Override public int hashCode() {return Objects.hash(id, name); }}

由此可以看到,虽然hashcode方法返回的hash值相同,但是通过equlas方法进行比较,返回的直接就是false。
这里我们说的有点??铝斯??纠慈?粤接锞涂梢运登宄?模??桥滦率峙笥巡焕斫猓??跃投??铝思妇洌?飧鑫恼率俏腋鋈说睦斫猓?绻?胁徽?返南M?愣嗖慰际橐约肮偻??斜榷裕?暇寡奂??德铮?乙膊桓彝耆?Vの揖褪嵌缘摹?/p>
到此这篇关于详解Java中的hashcode的文章就介绍到这了,更多相关Java hashcode内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
1. vue-drag-chart 拖动/缩放图表组件的实例代码2. vue使用moment如何将时间戳转为标准日期时间格式3. Android studio 解决logcat无过滤工具栏的操作4. 什么是Python变量作用域5. js select支持手动输入功能实现代码6. PHP正则表达式函数preg_replace用法实例分析7. Android Studio3.6.+ 插件搜索不到终极解决方案(图文详解)8. bootstrap select2 动态从后台Ajax动态获取数据的代码9. Android 实现彻底退出自己APP 并杀掉所有相关的进程10. 一个 2 年 Android 开发者的 18 条忠告
 网公网安备
网公网安备