PHP内核探索 —— 理解Zend里的哈希表
在PHP的Zend引擎中,有一个数据结构非常重要,它无处不在,是PHP数据存储的核心,各种常量、变量、函数、类、对象等都用它来组织,这个数据结构就是HashTable。
HashTable在通常的数据结构教材中也称作散列表,哈希表。其基本原理比较简单(如果你对其不熟悉,请查阅随便一本数据结构教材或在网上搜索),但PHP的实现有其独特的地方。理解了HashTable的数据存储结构,对我们分析PHP的源代码,特别是Zend Engine中的虚拟机的实现时,有很重要的帮助。它可以帮助我们在大脑中模拟一个完整的虚拟机的形象。它也是PHP中其它一些数据结构如数组实现的基础。
Zend HashTable的实现结合了双向链表和向量(数组)两种数据结构的优点,为PHP提供了非常高效的数据存储和查询机制。
HashTable的数据结构在Zend Engine中的HashTable的实现代码主要包括zend_hash.h, zend_hash.c这两个文件中。Zend HashTable包括两个主要的数据结构,其一是Bucket(桶)结构,另一个是HashTable结构。Bucket结构是用于保存数据的容器,而 HashTable结构则提供了对所有这些Bucket(或桶列)进行管理的机制。
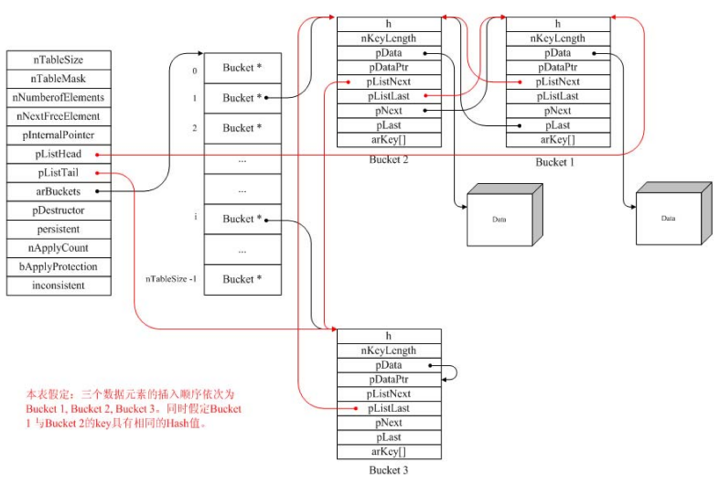
typedef struct bucket { ulong h; /* Used for numeric indexing */ uint nKeyLength; /* key 长度 */ void *pData; /* 指向Bucket中保存的数据的指针 */ void *pDataPtr; /* 指针数据 */ struct bucket *pListNext; /* 指向HashTable桶列中下一个元素 */ struct bucket *pListLast; /* 指向HashTable桶列中前一个元素 */ struct bucket *pNext; /* 指向具有同一个hash值的桶列的后一个元素 */ struct bucket *pLast; /* 指向具有同一个hash值的桶列的前一个元素 */ char arKey[1]; /* 必须是最后一个成员,key名称*/} Bucket;
在Zend HashTable中,每个数据元素(Bucket)有一个键名(key),它在整个HashTable中是唯一的,不能重复。根据键名可以唯一确定 HashTable中的数据元素。键名有两种表示方式。第一种方式使用字符串arKey作为键名,该字符串的长度为nKeyLength。注意到在上面的数据结构中arKey虽然只是一个长度为1的字符数组,但它并不意味着key只能是一个字符。实际上Bucket是一个可变长的结构体,由于arKey是 Bucket的最后一个成员变量,通过arKey与nKeyLength结合可确定一个长度为nKeyLength的key。这是C语言编程中的一个比较 常用的技巧。另一种键名的表示方式是索引方式,这时nKeyLength总是0,长整型字段h就表示该数据元素的键名。简单的来说,即如果 nKeyLength=0,则键名为h;否则键名为arKey, 键名的长度为nKeyLength。
当nKeyLength > 0时,并不表示这时的h值就没有意义。事实上,此时它保存的是arKey对应的hash值。不管hash函数怎么设计,冲突都是不可避免的,也就是说不同 的arKey可能有相同的hash值。具有相同hash值的Bucket保存在HashTable的arBuckets数组(参考下面的解释)的同一个索 引对应的桶列中。这个桶列是一个双向链表,其前向元素,后向元素分别用pLast, pNext来表示。新插入的Bucket放在该桶列的最前面。
在Bucket中,实际的数据是保存在pData指针指向的内存块中,通常这个内存块是系统另外分配的。但有一种情况例外,就是当Bucket保存的数据是一个指针时,HashTable将不会另外请求系统分配空间来保存这个指针,而是直接将该指针保存到pDataPtr中,然后再将pData指向 本结构成员的地址。这样可以提高效率,减少内存碎片。由此我们可以看到PHP HashTable设计的精妙之处。如果Bucket中的数据不是一个指针,pDataPtr为NULL。
HashTable中所有的Bucket通过pListNext, pListLast构成了一个双向链表。最新插入的Bucket放在这个双向链表的最后。
注意在一般情况下,Bucket并不能提供它所存储的数据大小的信息。所以在PHP的实现中,Bucket中保存的数据必须具有管理自身大小的能力。
typedef struct _hashtable { uint nTableSize; uint nTableMask; uint nNumOfElements; ulong nNextFreeElement; Bucket *pInternalPointer; Bucket *pListHead; Bucket *pListTail; Bucket **arBuckets; dtor_func_t pDestructor; zend_bool persistent; unsigned char nApplyCount; zend_bool bApplyProtection; #if ZEND_DEBUG int inconsistent; #endif} HashTable;
在HashTable结构中,nTableSize指定了HashTable的大小,同时它限定了HashTable中能保存Bucket的最大数量,此 数越大,系统为HashTable分配的内存就越多。为了提高计算效率,系统自动会将nTableSize调整到最小一个不小于nTableSize的2 的整数次方。也就是说,如果在初始化HashTable时指定一个nTableSize不是2的整数次方,系统将会自动调整nTableSize的值。即
nTableSize = 2ceil(log(nTableSize, 2)) 或 nTableSize = pow(ceil(log(nTableSize,2)))
例如,如果在初始化HashTable的时候指定nTableSize = 11,HashTable初始化程序会自动将nTableSize增大到16。
arBuckets是HashTable的关键,HashTable初始化程序会自动申请一块内存,并将其地址赋值给arBuckets,该内存大 小正好能容纳nTableSize个指针。我们可以将arBuckets看作一个大小为nTableSize的数组,每个数组元素都是一个指针,用于指向 实际存放数据的Bucket。当然刚开始时每个指针均为NULL。
nTableMask的值永远是nTableSize – 1,引入这个字段的主要目的是为了提高计算效率,是为了快速计算Bucket键名在arBuckets数组中的索引。
nNumberOfElements记录了HashTable当前保存的数据元素的个数。当nNumberOfElement大于nTableSize时,HashTable将自动扩展为原来的两倍大小。
nNextFreeElement记录HashTable中下一个可用于插入数据元素的arBuckets的索引。
pListHead, pListTail则分别表示Bucket双向链表的第一个和最后一个元素,这些数据元素通常是根据插入的顺序排列的。也可以通过各种排序函数对其进行重 新排列。pInternalPointer则用于在遍历HashTable时记录当前遍历的位置,它是一个指针,指向当前遍历到的Bucket,初始值是 pListHead。
pDestructor是一个函数指针,在HashTable的增加、修改、删除Bucket时自动调用,用于处理相关数据的清理工作。
persistent标志位指出了Bucket内存分配的方式。如果persisient为TRUE,则使用操作系统本身的内存分配函数为Bucket分配内存,否则使用PHP的内存分配函数。具体请参考PHP的内存管理。
nApplyCount与bApplyProtection结合提供了一个防止在遍历HashTable时进入递归循环时的一种机制。
inconsistent成员用于调试目的,只在PHP编译成调试版本时有效。表示HashTable的状态,状态有四种:
状态值的含义:
HT_IS_DESTROYING 正在删除所有的内容,包括arBuckets本身HT_IS_DESTROYED 已删除,包括arBuckets本身HT_CLEANING 正在清除所有的arBuckets指向的内容,但不包括arBuckets本身HT_OK 正常状态,各种数据完全一致typedef struct _zend_hash_key { char *arKey; /* hash元素key名称 */ uint nKeyLength; /* hash 元素key长度 */ ulong h; /* key计算出的hash值或直接指定的数值下标 */} zend_hash_key;
现在来看zend_hash_key结构就比较容易理解了。它通过arKey, nKeyLength, h三个字段唯一确定了HashTable中的一个元素。
根据上面对HashTable相关数据结构的解释,我们可以画出HashTable的内存结构图:
本节具体介绍一下PHP中HashTable的实现。以下函数均取自于zend_hash.c。只要充分理解了上述数据结构,HashTable实现的代码并不难理解。
1. HashTable初始化
HashTable提供了一个zend_hash_init宏来完成HashTable的初始化操作。实际上它是通过下面的内部函数来实现的:
ZEND_API int _zend_hash_init(HashTable *ht, uint nSize, hash_func_t pHashFunction, dtor_func_t pDestructor, zend_bool persistent ZEND_FILE_LINE_DC){ uint i = 3; Bucket **tmp; SET_INCONSISTENT(HT_OK); if (nSize >= 0×80000000) {/* prevent overflow */ht->nTableSize = 0×80000000; } else {while ((1U << i) < nSize) { /* 自动调整nTableSize至2的n次方 */ i++; } ht->nTableSize = 1 << i; /* i的最小值为3,因此HashTable大小最小为8 */ } ht->nTableMask = ht->nTableSize - 1; ht->pDestructor = pDestructor; ht->arBuckets = NULL; ht->pListHead = NULL; ht->pListTail = NULL; ht->nNumOfElements = 0; ht->nNextFreeElement = 0; ht->pInternalPointer = NULL; ht->persistent = persistent; ht->nApplyCount = 0; ht->bApplyProtection = 1; /* 根据persistent使用不同方式分配arBuckets内存,并将其所有指针初始化为NULL*/ /* Uses ecalloc() so that Bucket* == NULL */ if (persistent) {tmp = (Bucket **) calloc(ht->nTableSize, sizeof(Bucket *));if (!tmp) { return FAILURE;}ht->arBuckets = tmp; } else {tmp = (Bucket **) ecalloc_rel(ht->nTableSize, sizeof(Bucket *));if (tmp) { ht->arBuckets = tmp;} } return SUCCESS;}
在以前的版本中,可以使用pHashFunction来指定hash函数。但现PHP已强制使用DJBX33A算法,因此实际上pHashFunction这个参数并不会用到,保留在这里只是为了与以前的代码兼容。
2. 增加、插入和修改元素
向HashTable中添加一个新的元素最关键的就是要确定将这个元素插入到arBuckets数组中的哪个位置。根据上面对Bucket结构键名 的解释,我们可以知道有两种方式向HashTable添加一个新的元素。第一种方法是使用字符串作为键名来插入Bucket;第二种方法是使用索引作为键 名来插入Bucket。第二种方法具体又可以分为两种情况:指定索引或不指定索引,指定索引指的是强制将Bucket插入到指定的索引位置中;不指定索引 则将Bucket插入到nNextFreeElement对应的索引位置中。这几种插入数据的方法实现比较类似,不同的只是定位Bucket的方法。
修改HashTable中的数据的方法与增加数据的方法也很类似。
我们先看第一种使用字符串作为键名增加或修改Bucket的方法:
ZEND_API int _zend_hash_add_or_update(HashTable *ht, char *arKey, uint nKeyLength, void *pData, uint nDataSize, void **pDest, int flag ZEND_FILE_LINE_DC){ ulong h; uint nIndex; Bucket *p; IS_CONSISTENT(ht); // 调试信息输出 if (nKeyLength <= 0) {#if ZEND_DEBUG ZEND_PUTS(”zend_hash_update: Can’t put in empty keyn”); #endif return FAILURE; } /* 使用hash函数计算arKey的hash值 */ h = zend_inline_hash_func(arKey, nKeyLength); /* 将hash值和nTableMask按位与后生成该元素在arBuckets中的索引。让它和 * nTableMask按位与是保证不会产生一个使得arBuckets越界的数组下标。 */ nIndex = h & ht->nTableMask; p = ht->arBuckets[nIndex]; /* 取得相应索引对应的Bucket的指针 */ /* 检查对应的桶列中是否包含有数据元素(key, hash) */ while (p != NULL) {if ((p->h == h) && (p->nKeyLength == nKeyLength)) { if (!memcmp(p->arKey, arKey, nKeyLength)) { if (flag & HASH_ADD) { return FAILURE; // 对应的数据元素已存在,不能进行插入操作 } HANDLE_BLOCK_INTERRUPTIONS(); #if ZEND_DEBUG if (p->pData == pData) { ZEND_PUTS(”Fatal error in zend_hash_update: p->pData == pDatan”); HANDLE_UNBLOCK_INTERRUPTIONS(); return FAILURE; } #endif if (ht->pDestructor) { /* 如果数据元素存在,对原来的数据进行析构操作 */ ht->pDestructor(p->pData); } /* 用新的数据来更新原来的数据 */ UPDATE_DATA(ht, p, pData, nDataSize); if (pDest) { *pDest = p->pData; } HANDLE_UNBLOCK_INTERRUPTIONS(); return SUCCESS; }}p = p->pNext; } /* HashTable中没有key对应的数据,新增一个Bucket */ p = (Bucket *) pemalloc(sizeof(Bucket) - 1 + nKeyLength, ht->persistent); if (!p) {return FAILURE; } memcpy(p->arKey, arKey, nKeyLength); p->nKeyLength = nKeyLength; INIT_DATA(ht, p, pData, nDataSize); p->h = h; // 将Bucket加入到相应的桶列中 CONNECT_TO_BUCKET_DLLIST(p, ht->arBuckets[nIndex]); if (pDest) {*pDest = p->pData; } HANDLE_BLOCK_INTERRUPTIONS(); // 将Bucket 加入到HashTable的双向链表中 CONNECT_TO_GLOBAL_DLLIST(p, ht); ht->arBuckets[nIndex] = p; HANDLE_UNBLOCK_INTERRUPTIONS(); ht->nNumOfElements++; // 如果HashTable已满,重新调整HashTable的大小。 ZEND_HASH_IF_FULL_DO_RESIZE(ht); /* If the Hash table is full, resize it */ return SUCCESS;}
因为这个函数是使用字符串作为键名来插入数据的,因此它首先检查nKeyLength的值是否大于0,如果不是的话就直接退出。然后计算arKey对应的 hash值h,将其与nTableMask按位与后得到一个无符号整数nIndex。这个nIndex就是将要插入的Bucket在arBuckets数 组中的索引位置。
现在已经有了arBuckets数组的一个索引,我们知道它包括的数据是一个指向Bucket的双向链表的指针。如果这个双向链表不为空的话我们首先检查 这个双向链表中是否已经包含了用字符串arKey指定的键名的Bucket,这样的Bucket如果存在,并且我们要做的操作是插入新Bucket(通过 flag标识),这时就应该报错 – 因为在HashTable中键名不可以重复。如果存在,并且是修改操作,则使用在HashTable中指定了析构函数pDestructor对原来的 pData指向的数据进行析构操作;然后将用新的数据替换原来的数据即可成功返回修改操作。
如果在HashTable中没有找到键名指定的数据,就将该数据封装到Bucket中,然后插入HashTable。这里要注意的是如下的两个宏:
CONNECT_TO_BUCKET_DLLIST(p, ht->arBuckets[nIndex])CONNECT_TO_GLOBAL_DLLIST(p, ht)前者是将该Bucket插入到指定索引的Bucket双向链表中,后者是插入到整个HashTable的Bucket双向链表中。两者的插入方式也不同,前者是将该Bucket插入到双向链表的最前面,后者是插入到双向链表的最末端。
下面是第二种插入或修改Bucket的方法,即使用索引的方法:
ZEND_API int _zend_hash_index_update_or_next_insert(HashTable *ht, ulong h, void *pData, uint nDataSize, void **pDest, int flag ZEND_FILE_LINE_DC){uint nIndex;Bucket *p;IS_CONSISTENT(ht);if (flag & HASH_NEXT_INSERT) {h = ht->nNextFreeElement;}nIndex = h & ht->nTableMask;p = ht->arBuckets[nIndex];// 检查是否含有相应的数据while (p != NULL) {if ((p->nKeyLength == 0) && (p->h == h)) {if (flag & HASH_NEXT_INSERT || flag & HASH_ADD) {return FAILURE;}//// …… 修改Bucket数据,略//if ((long)h >= (long)ht->nNextFreeElement) {ht->nNextFreeElement = h + 1;}if (pDest) {*pDest = p->pData;}return SUCCESS;}p = p->pNext;}p = (Bucket *) pemalloc_rel(sizeof(Bucket) - 1, ht->persistent);if (!p) {return FAILURE;}p->nKeyLength = 0; /* Numeric indices are marked by making the nKeyLength == 0 */p->h = h;INIT_DATA(ht, p, pData, nDataSize);if (pDest) {*pDest = p->pData;}CONNECT_TO_BUCKET_DLLIST(p, ht->arBuckets[nIndex]);HANDLE_BLOCK_INTERRUPTIONS();ht->arBuckets[nIndex] = p;CONNECT_TO_GLOBAL_DLLIST(p, ht);HANDLE_UNBLOCK_INTERRUPTIONS();if ((long)h >= (long)ht->nNextFreeElement) {ht->nNextFreeElement = h + 1;}ht->nNumOfElements++;ZEND_HASH_IF_FULL_DO_RESIZE(ht);return SUCCESS;}
flag标志指明当前操作是HASH_NEXT_INSERT(不指定索引插入或修改), HASH_ADD(指定索引插入)还是HASH_UPDATE(指定索引修改)。由于这些操作的实现代码基本相同,因此统一合并成了一个函数,再用flag加以区分。
本函数基本与前一个相同,不同的是如果确定插入到arBuckets数组中的索引的方法。如果操作是HASH_NEXT_INSERT,则直接使用nNextFreeElement作为插入的索引。注意nNextFreeElement的值是如何使用和更新的。
3. 访问元素
同样,HashTable用两种方式来访问元素,一种是使用字符串arKey的zend_hash_find();另一种是使用索引的访问方式zend_hash_index_find()。由于其实现的代码很简单,分析工作就留给读者自已完成。
4. 删除元素
HashTable删除数据均使用zend_hash_del_key_or_index()函数来完成,其代码也较为简单,这里也不再详细分析。需要的是注意如何根据arKey或h来计算出相应的下标,以及两个双向链表的指针的处理。
5. 遍历元素
/* This is used to recurse elements and selectively delete certain entries* from a hashtable. apply_func() receives the data and decides if the entry* should be deleted or recursion should be stopped. The following three* return codes are possible:* ZEND_HASH_APPLY_KEEP - continue* ZEND_HASH_APPLY_STOP - stop iteration* ZEND_HASH_APPLY_REMOVE - delete the element, combineable with the former*/ZEND_API void zend_hash_apply(HashTable *ht, apply_func_t apply_func TSRMLS_DC){Bucket *p;IS_CONSISTENT(ht);HASH_PROTECT_RECURSION(ht);p = ht->pListHead;while (p != NULL) {int result = apply_func(p->pData TSRMLS_CC);if (result & ZEND_HASH_APPLY_REMOVE) {p = zend_hash_apply_deleter(ht, p);} else {p = p->pListNext;}if (result & ZEND_HASH_APPLY_STOP) {break;}}HASH_UNPROTECT_RECURSION(ht);}
因为HashTable中所有Bucket都可以通过pListHead指向的双向链表来访问,因此遍历HashTable的实现也比较简单。这里值得一 提的是对当前遍历到的Bucket的处理使用了一个apply_func_t类型的回调函数。根据实际需要,该回调函数返回下面值之一:
ZEND_HASH_APPLY_KEEPZEND_HASH_APPLY_STOPZEND_HASH_APPLY_REMOVE它们分别表示继续遍历,停止遍历或删除相应元素后继续遍历。
还有一个要注意的问题就是遍历时的防止递归的问题,也就是防止对同一个HashTable同时进行多次遍历。这是用下面两个宏来实现的:
HASH_PROTECT_RECURSION(ht)HASH_UNPROTECT_RECURSION(ht)其主要原理是如果遍历保护标志bApplyProtection为真,则每次进入遍历函数时将nApplyCount值加1,退出遍历函数时将nApplyCount值减1。开始遍历之前如果发现nApplyCount > 3就直接报告错误信息并退出遍历。
上面的apply_func_t不带参数。HashTable还提供带一个参数或可变参数的回调方式,对应的遍历函数分别为:
typedef int (*apply_func_arg_t)(void *pDest,void *argument TSRMLS_DC);void zend_hash_apply_with_argument(HashTable *ht,apply_func_arg_t apply_func, void *data TSRMLS_DC);typedef int (*apply_func_args_t)(void *pDest,int num_args, va_list args, zend_hash_key *hash_key);void zend_hash_apply_with_arguments(HashTable *ht,apply_func_args_t apply_func, int numargs, …);
除了上面提供的几种提供外,还有许多其它操作HashTable的API。如排序、HashTable的拷贝与合并等等。只要充分理解了上述HashTable的数据结构,理解这些代码并不困难。
相关文章:

 网公网安备
网公网安备