目录前言环境Surprise介绍协同过滤数据集业务介绍编码部分1. PHP请求封装2. PHP发起推荐获取3. 数据集生成4. 协同过滤服务5. 基于用户推荐6. 基于物品推荐其他写在最后前言
前面一文介绍了通过基础的web项目结构实现简单的内容推荐,与其说那个是推荐不如说是一个排序算法。因为热度计算方式虽然解决了内容的时效质量动态化。但是相对用户而言,大家看到的都是几乎一致的内容(不一样也可能只是某时间里某视频的排前或靠后),没有做到个性化的千人千面。
尽管如此,基于内容的热度推荐依然有他独特的应用场景——热门榜单。所以只需要把这个功能换一个模块就可以了,将个性化推荐留给更擅长做这方面的算法。
当然了,做推荐系统的方法很多,平台层面的像spark和今天要讲的Surprise。方法层面可以用深度学习做,也可以用协同过滤,或综合一起等等。大厂可能就更完善了,在召回阶段就有很多通道,比如基于卷积截帧识别视频内容,文本相似度计算和现有数据支撑,后面又经过清洗,粗排,精排,重排等等流程,可能他们更多的是要保证平台内容的多样性。
那我们这里依然走入门实际使用为主,能让我们的项目快速对接上个性化推荐,以下就是在原因PHP项目结构上对接Surprise,实现用户和物品的相似度推荐。
环境python3.8Flask2.0pandas2.0mysql-connector-python surpriseopenpyxlgunicorn Surprise介绍
Surprise库是一款用于构建和分析推荐系统的工具库,他提供了多种推荐算法,包括基线算法、邻域方法、基于矩阵分解的算法(如SVD、PMF、SVD++、NMF)等。内置了多种相似性度量方法,如余弦相似性、均方差(MSD)、皮尔逊相关系数等。这些相似性度量方法可以用于评估用户之间的相似性,从而为推荐系统提供重要的数据支持。
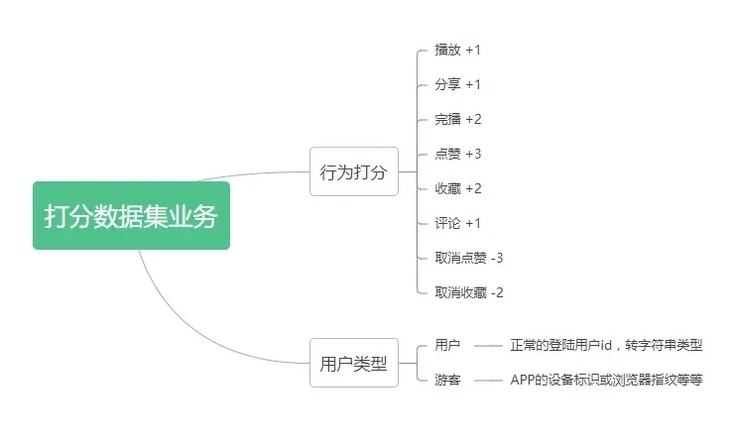
协同过滤数据集
既然要基于工具库完成协同过滤推荐,自然就需要按该库的标准进行。Surprise也和大多数协同过滤框架类似,数据集只需要有用户对某个物品打分分值,如果自己没有可以在网上下载免费的Movielens或Jester,以下是我根据业务创建的表格,自行参考。
CREATE TABLE `short_video_rating` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` varchar(120) DEFAULT '', `item_id` int(11) DEFAULT '0', `rating` int(11) unsigned DEFAULT '0' COMMENT '评分', `scoring_set` json DEFAULT NULL COMMENT '行为集合', `create_time` int(11) DEFAULT '0', `action_day_time` int(11) DEFAULT '0' COMMENT '更新当天时间', `update_time` int(11) DEFAULT '0' COMMENT '更新时间', `delete_time` int(11) DEFAULT '0' COMMENT '删除时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=107 DEFAULT CHARSET=utf8mb4 COMMENT='用户对视频评分表';业务介绍
Web业务端通过接口或埋点,在用户操作的地方根据预设的标准记录评分记录。当打分表有数据后,用python将SQL记录转为表格再导入Surprise,根据不同的算法训练,最后根据接收的参数返回对应的推荐top列表。python部分由Flask启动的服务,与php进行http交互,后面将以片段代码说明。
编码部分1. PHP请求封装<?php/** * Created by ZERO开发. * User: 北桥苏 * Date: 2023/6/26 0026 * Time: 14:43 */namespace app\common\service;class Recommend{ private $condition; private $cfRecommends = []; private $output = []; public function __construct($flag = 1, $lastRecommendIds = [], $userId = '') {$this->condition['flag'] = $flag;$this->condition['last_recommend_ids'] = $lastRecommendIds;$this->condition['user_id'] = $userId; } public function addObserver($cfRecommend) {$this->cfRecommends[] = $cfRecommend; } public function startRecommend() {foreach ($this->cfRecommends as $cfRecommend) { $res = $cfRecommend->recommend($this->condition); $this->output = array_merge($res, $this->output);}$this->output = array_values(array_unique($this->output));return $this->output; }}abstract class cfRecommendBase{ protected $cfGatewayUrl = '127.0.0.1:6016'; protected $limit = 15; public function __construct($limit = 15) {$this->limit = $limit;$this->cfGatewayUrl = config('api.video_recommend.gateway_url'); } abstract public function recommend($condition);}class mcf extends cfRecommendBase{ public function recommend($condition) {//echo 'mcf\n';$videoIdArr = [];$flag = $condition['flag'] ?? 1;$userId = $condition['user_id'] ?? '';$url = '{$this->cfGatewayUrl}/mcf_recommend';if ($flag == 1 && $userId) { //echo 'mcf2\n'; $param['raw_uid'] = (string)$userId; $param['top_k'] = $this->limit; $list = httpRequest($url, $param, 'json'); $videoIdArr = json_decode($list, true) ?? [];}return $videoIdArr; }}class icf extends cfRecommendBase{ public function recommend($condition) {//echo 'icf\n';$videoIdArr = [];$flag = $condition['flag'] ?? 1;$userId = $condition['user_id'] ?? '';$lastRecommendIds = $condition['last_recommend_ids'] ?? [];$url = '{$this->cfGatewayUrl}/icf_recommend';if ($flag > 1 && $lastRecommendIds && $userId) { //echo 'icf2\n'; $itemId = $lastRecommendIds[0] ?? 0; $param['raw_item_id'] = $itemId; $param['top_k'] = $this->limit; $list = httpRequest($url, $param, 'json'); $videoIdArr = json_decode($list, true) ?? [];}return $videoIdArr; }}2. PHP发起推荐获取
由于考虑到前期视频存量不足,是采用协同过滤加热度榜单结合的方式,前端获取视频推荐,接口返回视频推荐列表的同时也带了下次请求的标识(分页码)。这个分页码用于当协同过滤服务挂了或没有推荐时,放在榜单列表的分页。但是又要保证分页数是否实际有效,所以当页码太大没有数据返回就通过递归重置为第一页,也把页码返回前端让数据获取更流畅。
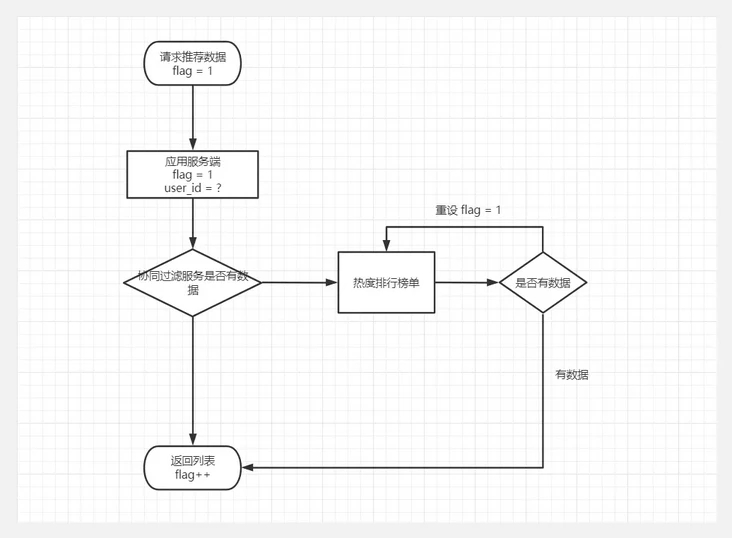
public static function recommend($flag, $videoIds, $userId) {$nexFlag = $flag + 1;$formatterVideoList = [];try { // 协同过滤推荐 $isOpen = config('api.video_recommend.is_open'); $cfVideoIds = []; if ($isOpen == 1) {$recommend = new Recommend($flag, $videoIds, $userId);$recommend->addObserver(new mcf(15));$recommend->addObserver(new icf(15));$cfVideoIds = $recommend->startRecommend(); } // 已读视频 $nowTime = strtotime(date('Ymd')); $timeBefore = $nowTime - 60 * 60 * 24 * 100; $videoIdsFilter = self::getUserVideoRatingByTime($userId, $timeBefore); $cfVideoIds = array_diff($cfVideoIds, $videoIdsFilter); // 违规视频过滤 $videoPool = []; $cfVideoIds && $videoPool = ShortVideoModel::listByOrderRaw($cfVideoIds, $flag); // 冷启动推荐 !$videoPool && $videoPool = self::hotRank($userId, $videoIdsFilter, $flag); if ($videoPool) {list($nexFlag, $videoList) = $videoPool;$formatterVideoList = self::formatterVideoList($videoList, $userId); }} catch (\Exception $e) { $preFileName = str::snake(__FUNCTION__); $path = self::getClassName(); write_log('msg:' . $e->getMessage(), $preFileName . '_error', $path);}return [$nexFlag, $formatterVideoList]; }3. 数据集生成import osimport mysql.connectorimport datetimeimport pandas as pdnow = datetime.datetime.now()year = now.yearmonth = now.monthday = now.dayfullDate = str(year) + str(month) + str(day)dir_data = './collaborative_filtering/cf_excel'file_path = '{}/dataset_{}.xlsx'.format(dir_data, fullDate)db_config = { 'host': '127.0.0.1', 'database': 'database', 'user': 'user', 'password': 'password'}if not os.path.exists(file_path): cnx = mysql.connector.connect(user=db_config['user'], password=db_config['password'], host=db_config['host'], database=db_config['database']) df = pd.read_sql_query('SELECT user_id, item_id, rating FROM short_video_rating', cnx) print('---------------插入数据集----------------') # 将数据帧写入Excel文件 df.to_excel(file_path, index=False)if not os.path.exists(file_path): raise IOError('Dataset file is not exists!')4. 协同过滤服务from flask import Flask, request, json, Response, abortfrom collaborative_filtering import cf_itemfrom collaborative_filtering import cf_userfrom collaborative_filtering import cf_mixfrom werkzeug.middleware.proxy_fix import ProxyFixapp = Flask(__name__)@app.route('/')def hello_world(): return abort(404)@app.route('/mcf_recommend', methods=['POST', 'GET'])def get_mcf_recommendation(): json_data = request.get_json() raw_uid = json_data.get('raw_uid') top_k = json_data.get('top_k') recommend_result = cf_mix.collaborative_fitlering(raw_uid, top_k) return Response(json.dumps(recommend_result), mimetype='application/json')@app.route('/ucf_recommend', methods=['POST', 'GET'])def get_ucf_recommendation(): json_data = request.get_json() raw_uid = json_data.get('raw_uid') top_k = json_data.get('top_k') recommend_result = cf_user.collaborative_fitlering(raw_uid, top_k) return Response(json.dumps(recommend_result), mimetype='application/json')@app.route('/icf_recommend', methods=['POST', 'GET'])def get_icf_recommendation(): json_data = request.get_json() raw_item_id = json_data.get('raw_item_id') top_k = json_data.get('top_k') recommend_result = cf_item.collaborative_fitlering(raw_item_id, top_k) return Response(json.dumps(recommend_result), mimetype='application/json')if __name__ == '__main__': app.run(host='0.0.0.0', debug=True, port=6016 )5. 基于用户推荐# -*- coding: utf-8 -*-# @File : cf_recommendation.pyfrom __future__ import (absolute_import, division, print_function,unicode_literals)from collections import defaultdictimport osfrom surprise import Datasetfrom surprise import Readerfrom surprise import BaselineOnlyfrom surprise import KNNBasicfrom surprise import KNNBaselinefrom heapq import nlargestimport pandas as pdimport datetimeimport timedef get_top_n(predictions, n=10): top_n = defaultdict(list) for uid, iid, true_r, est, _ in predictions:top_n[uid].append((iid, est)) for uid, user_ratings in top_n.items():top_n[uid] = nlargest(n, user_ratings, key=lambda s: s[1]) return top_nclass PredictionSet(): def __init__(self, algo, trainset, user_raw_id=None, k=40):self.algo = algoself.trainset = trainsetself.k = kif user_raw_id is not None: self.r_uid = user_raw_id self.i_uid = trainset.to_inner_uid(user_raw_id) self.knn_userset = self.algo.get_neighbors(self.i_uid, self.k) user_items = set([j for (j, _) in self.trainset.ur[self.i_uid]]) self.neighbor_items = set() for nnu in self.knn_userset:for (j, _) in trainset.ur[nnu]: if j not in user_items:self.neighbor_items.add(j) def user_build_anti_testset(self, fill=None):fill = self.trainset.global_mean if fill is None else float(fill)anti_testset = []user_items = set([j for (j, _) in self.trainset.ur[self.i_uid]])anti_testset += [(self.r_uid, self.trainset.to_raw_iid(i), fill) for i in self.neighbor_items if i not in user_items]return anti_testsetdef user_build_anti_testset(trainset, user_raw_id, fill=None): fill = trainset.global_mean if fill is None else float(fill) i_uid = trainset.to_inner_uid(user_raw_id) anti_testset = [] user_items = set([j for (j, _) in trainset.ur[i_uid]]) anti_testset += [(user_raw_id, trainset.to_raw_iid(i), fill) for i in trainset.all_items() if i not in user_items] return anti_testset# ================= surprise 推荐部分 ====================def collaborative_fitlering(raw_uid, top_k): now = datetime.datetime.now() year = now.year month = now.month day = now.day fullDate = str(year) + str(month) + str(day) dir_data = './collaborative_filtering/cf_excel' file_path = '{}/dataset_{}.xlsx'.format(dir_data, fullDate) if not os.path.exists(file_path):raise IOError('Dataset file is not exists!') # 读取数据集##################### alldata = pd.read_excel(file_path) reader = Reader(line_format='user item rating') dataset = Dataset.load_from_df(alldata, reader=reader) # 所有数据生成训练集 trainset = dataset.build_full_trainset() # ================= BaselineOnly ================== bsl_options = {'method': 'sgd', 'learning_rate': 0.0005} algo_BaselineOnly = BaselineOnly(bsl_options=bsl_options) algo_BaselineOnly.fit(trainset) # 获得推荐结果 rset = user_build_anti_testset(trainset, raw_uid) # 测试休眠5秒,让客户端超时 # time.sleep(5) # print(rset) # exit() predictions = algo_BaselineOnly.test(rset) top_n_baselineonly = get_top_n(predictions, n=5) # ================= KNNBasic ================== sim_options = {'name': 'pearson', 'user_based': True} algo_KNNBasic = KNNBasic(sim_options=sim_options) algo_KNNBasic.fit(trainset) # 获得推荐结果 --- 只考虑 knn 用户的 predictor = PredictionSet(algo_KNNBasic, trainset, raw_uid) knn_anti_set = predictor.user_build_anti_testset() predictions = algo_KNNBasic.test(knn_anti_set) top_n_knnbasic = get_top_n(predictions, n=top_k) # ================= KNNBaseline ================== sim_options = {'name': 'pearson_baseline', 'user_based': True} algo_KNNBaseline = KNNBaseline(sim_options=sim_options) algo_KNNBaseline.fit(trainset) # 获得推荐结果 --- 只考虑 knn 用户的 predictor = PredictionSet(algo_KNNBaseline, trainset, raw_uid) knn_anti_set = predictor.user_build_anti_testset() predictions = algo_KNNBaseline.test(knn_anti_set) top_n_knnbaseline = get_top_n(predictions, n=top_k) # =============== 按比例生成推荐结果 ================== recommendset = set() for results in [top_n_baselineonly, top_n_knnbasic, top_n_knnbaseline]:for key in results.keys(): for recommendations in results[key]:iid, rating = recommendationsrecommendset.add(iid) items_baselineonly = set() for key in top_n_baselineonly.keys():for recommendations in top_n_baselineonly[key]: iid, rating = recommendations items_baselineonly.add(iid) items_knnbasic = set() for key in top_n_knnbasic.keys():for recommendations in top_n_knnbasic[key]: iid, rating = recommendations items_knnbasic.add(iid) items_knnbaseline = set() for key in top_n_knnbaseline.keys():for recommendations in top_n_knnbaseline[key]: iid, rating = recommendations items_knnbaseline.add(iid) rank = dict() for recommendation in recommendset:if recommendation not in rank: rank[recommendation] = 0if recommendation in items_baselineonly: rank[recommendation] += 1if recommendation in items_knnbasic: rank[recommendation] += 1if recommendation in items_knnbaseline: rank[recommendation] += 1 max_rank = max(rank, key=lambda s: rank[s]) if max_rank == 1:return list(items_baselineonly) else:result = nlargest(top_k, rank, key=lambda s: rank[s])return list(result)# print('排名结果: {}'.format(result))6. 基于物品推荐-*- coding: utf-8 -*-from __future__ import (absolute_import, division, print_function,unicode_literals)from collections import defaultdictimport ioimport osfrom surprise import SVD, KNNBaseline, Reader, Datasetimport pandas as pdimport datetimeimport mysql.connectorimport pickle# ================= surprise 推荐部分 ====================def collaborative_fitlering(raw_item_id, top_k): now = datetime.datetime.now() year = now.year month = now.month day = now.day fullDate = str(year) + str(month) + str(day) # dir_data = './collaborative_filtering/cf_excel' dir_data = './cf_excel' file_path = '{}/dataset_{}.xlsx'.format(dir_data, fullDate) if not os.path.exists(file_path):raise IOError('Dataset file is not exists!') # 读取数据集##################### alldata = pd.read_excel(file_path) reader = Reader(line_format='user item rating') dataset = Dataset.load_from_df(alldata, reader=reader) # 使用协同过滤必须有这行,将我们的算法运用于整个数据集,而不进行交叉验证,构建了新的矩阵 trainset = dataset.build_full_trainset() # print(pd.DataFrame(list(trainset.global_mean()))) # exit() # 度量准则:pearson距离,协同过滤:基于item sim_options = {'name': 'pearson_baseline', 'user_based': False} algo = KNNBaseline(sim_options=sim_options) algo.fit(trainset) # 将训练好的模型序列化到磁盘上 # with open('./cf_models/cf_item_model.pkl', 'wb') as f: # pickle.dump(algo, f) #从磁盘中读取训练好的模型 # with open('cf_item_model.pkl', 'rb') as f: # algo = pickle.load(f) # 转换为内部id toy_story_inner_id = algo.trainset.to_inner_iid(raw_item_id) # 根据内部id找到最近的10个邻居 toy_story_neighbors = algo.get_neighbors(toy_story_inner_id, k=top_k) # 将10个邻居的内部id转换为item id也就是raw toy_story_neighbors_rids = (algo.trainset.to_raw_iid(inner_id) for inner_id in toy_story_neighbors) result = list(toy_story_neighbors_rids) return result # print(list(toy_story_neighbors_rids))if __name__ == '__main__': res = collaborative_fitlering(15, 20) print(res)其他
推荐服务生产部署开发环境下可以通过python recommend_service.py启动,后面部署环境需要用到gunicorn,方式是安装后配置环境变量。代码里导入werkzeug.middleware.proxy_fix, 修改以下的启动部分以下内容,启动改为gunicorn -w 5 -b 0.0.0.0:6016 app:appapp.wsgi_app = ProxyFix(app.wsgi_app)app.run()
模型本地保存随着业务数据的累计,自然需要训练的数据集也越来越大,所以后期关于模型训练周期,可以缩短。也就是定时训练模型后保存到本地,然后根据线上的数据做出推荐,模型存储与读取方法如下。2.1. 模型存储
sim_options = {'name': 'pearson_baseline', 'user_based': False} algo = KNNBaseline(sim_options=sim_options) algo.fit(trainset) # 将训练好的模型序列化到磁盘上 with open('./cf_models/cf_item_model.pkl', 'wb') as f: pickle.dump(algo, f)
2.2. 模型读取
with open('cf_item_model.pkl', 'rb') as f:algo = pickle.load(f) # 转换为内部id toy_story_inner_id = algo.trainset.to_inner_iid(raw_item_id) # 根据内部id找到最近的10个邻居 toy_story_neighbors = algo.get_neighbors(toy_story_inner_id, k=top_k) # 将10个邻居的内部id转换为item id也就是raw toy_story_neighbors_rids = (algo.trainset.to_raw_iid(inner_id) for inner_id in toy_story_neighbors) result = list(toy_story_neighbors_rids) return result写在最后
上面的依然只是实现了推荐系统的一小部分,在做数据召回不管可以对视频截帧还可以分离音频,通过卷积神经网络识别音频种类和视频大致内容。再根据用户以往浏览记录形成的标签实现内容匹配等等,这个还要后期不断学习和完善的。
以上就是基于Surprise协同过滤实现短视频推荐方法示例的详细内容,更多关于Surprise短视频推荐的资料请关注好吧啦网其它相关文章!
 网公网安备
网公网安备