Flink开发IDEA环境搭建与测试的方法
一.IDEA开发环境
1.pom文件设置
<properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.11.12</scala.version> <scala.binary.version>2.11</scala.binary.version> <hadoop.version>2.7.6</hadoop.version> <flink.version>1.6.1</flink.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.38</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.22</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.0</version><executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args><!-- <arg>-make:transitive</arg> --><arg>-dependencyfile</arg><arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution></executions> </plugin> <plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>2.18.1</version><configuration> <useFile>false</useFile> <disableXmlReport>true</disableXmlReport> <includes> <include>**/*Test.*</include> <include>**/*Suite.*</include> </includes></configuration> </plugin> <plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.0.0</version><executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters><filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes></filter> </filters> <transformers><transformer implementation='org.apache.maven.plugins.shade.resource.ManifestResourceTransformer'> <mainClass>org.apache.spark.WordCount</mainClass></transformer> </transformers> </configuration> </execution></executions> </plugin> </plugins> </build>
2.flink开发流程
Flink具有特殊类DataSet并DataStream在程序中表示数据。您可以将它们视为可以包含重复项的不可变数据集合。在DataSet数据有限的情况下,对于一个DataStream元素的数量可以是无界的。
这些集合在某些关键方面与常规Java集合不同。首先,它们是不可变的,这意味着一旦创建它们就无法添加或删除元素。你也不能简单地检查里面的元素。
集合最初通过在弗林克程序添加源创建和新的集合从这些通过将它们使用API方法如衍生map,filter等等。
Flink程序看起来像是转换数据集合的常规程序。每个程序包含相同的基本部分:
1.获取execution environment,
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
2.加载/创建初始化数据
DataStream<String> text = env.readTextFile(file:///path/to/file);
3.指定此数据的转换
val mapped = input.map { x => x.toInt }
4.指定放置计算结果的位置
writeAsText(String path)print()
5.触发程序执行
在local模式下执行程序
execute()
将程序达成jar运行在线上
./bin/flink run -m node21:8081 ./examples/batch/WordCount.jar --input hdfs:///user/admin/input/wc.txt--outputhdfs:///user/admin/output2
二.Wordcount案例
1.Scala代码
package com.xyg.streamingimport org.apache.flink.api.java.utils.ParameterToolimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.api.windowing.time.Time/** * Author: Mr.Deng * Date: 2018/10/15 * Desc: */object SocketWindowWordCountScala { def main(args: Array[String]) : Unit = { // 定义一个数据类型保存单词出现的次数 case class WordWithCount(word: String, count: Long) // port 表示需要连接的端口 val port: Int = try { ParameterTool.fromArgs(args).getInt('port') } catch { case e: Exception => { System.err.println('No port specified. Please run ’SocketWindowWordCount --port <port>’') return } } // 获取运行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment // 连接此socket获取输入数据 val text = env.socketTextStream('node21', port, ’n’) //需要加上这一行隐式转换 否则在调用flatmap方法的时候会报错 import org.apache.flink.api.scala._ // 解析数据, 分组, 窗口化, 并且聚合求SUM val windowCounts = text .flatMap { w => w.split('s') } .map { w => WordWithCount(w, 1) } .keyBy('word') .timeWindow(Time.seconds(5), Time.seconds(1)) .sum('count') // 打印输出并设置使用一个并行度 windowCounts.print().setParallelism(1) env.execute('Socket Window WordCount') }}
2.Java代码
package com.xyg.streaming;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.java.utils.ParameterTool;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.windowing.time.Time;import org.apache.flink.util.Collector;/** * Author: Mr.Deng * Date: 2018/10/15 * Desc: 使用flink对指定窗口内的数据进行实时统计,最终把结果打印出来 * 先在node21机器上执行nc -l 9000 */public class StreamingWindowWordCountJava { public static void main(String[] args) throws Exception { //定义socket的端口号 int port; try{ ParameterTool parameterTool = ParameterTool.fromArgs(args); port = parameterTool.getInt('port'); }catch (Exception e){ System.err.println('没有指定port参数,使用默认值9000'); port = 9000; } //获取运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //连接socket获取输入的数据 DataStreamSource<String> text = env.socketTextStream('node21', port, 'n'); //计算数据 DataStream<WordWithCount> windowCount = text.flatMap(new FlatMapFunction<String, WordWithCount>() { public void flatMap(String value, Collector<WordWithCount> out) throws Exception { String[] splits = value.split('s'); for (String word:splits) {out.collect(new WordWithCount(word,1L)); } } })//打平操作,把每行的单词转为<word,count>类型的数据 //针对相同的word数据进行分组 .keyBy('word') //指定计算数据的窗口大小和滑动窗口大小 .timeWindow(Time.seconds(2),Time.seconds(1)) .sum('count'); //把数据打印到控制台,使用一个并行度 windowCount.print().setParallelism(1); //注意:因为flink是懒加载的,所以必须调用execute方法,上面的代码才会执行 env.execute('streaming word count');} /** * 主要为了存储单词以及单词出现的次数 */ public static class WordWithCount{ public String word; public long count; public WordWithCount(){} public WordWithCount(String word, long count) { this.word = word; this.count = count; } @Override public String toString() { return 'WordWithCount{' + 'word=’' + word + ’’’ + ', count=' + count + ’}’; } }}
3.运行测试
首先,使用nc命令启动一个本地监听,命令是:
[admin@node21 ~]$ nc -l 9000
通过netstat命令观察9000端口。netstat -anlp | grep 9000,启动监听如果报错:-bash: nc: command not found,请先安装nc,在线安装命令:yum -y install nc。
然后,IDEA上运行flink官方案例程序
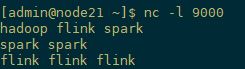
node21上输入
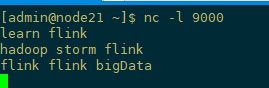
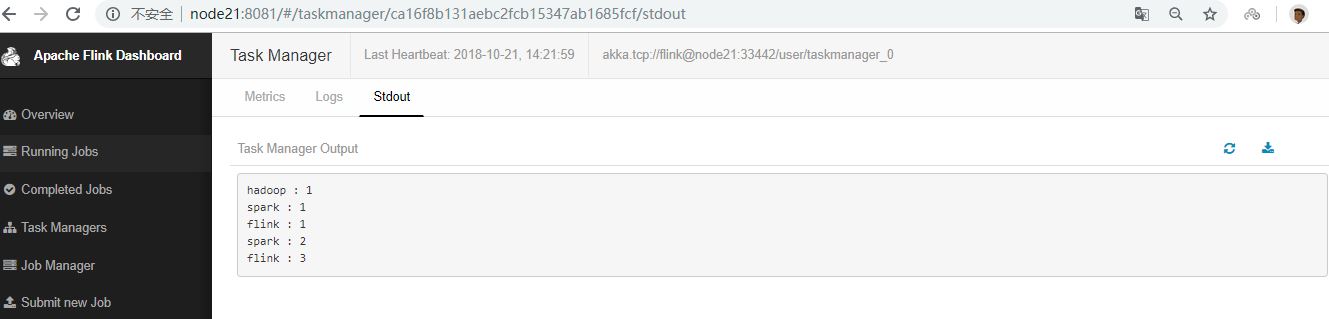
IDEA控制台输出如下
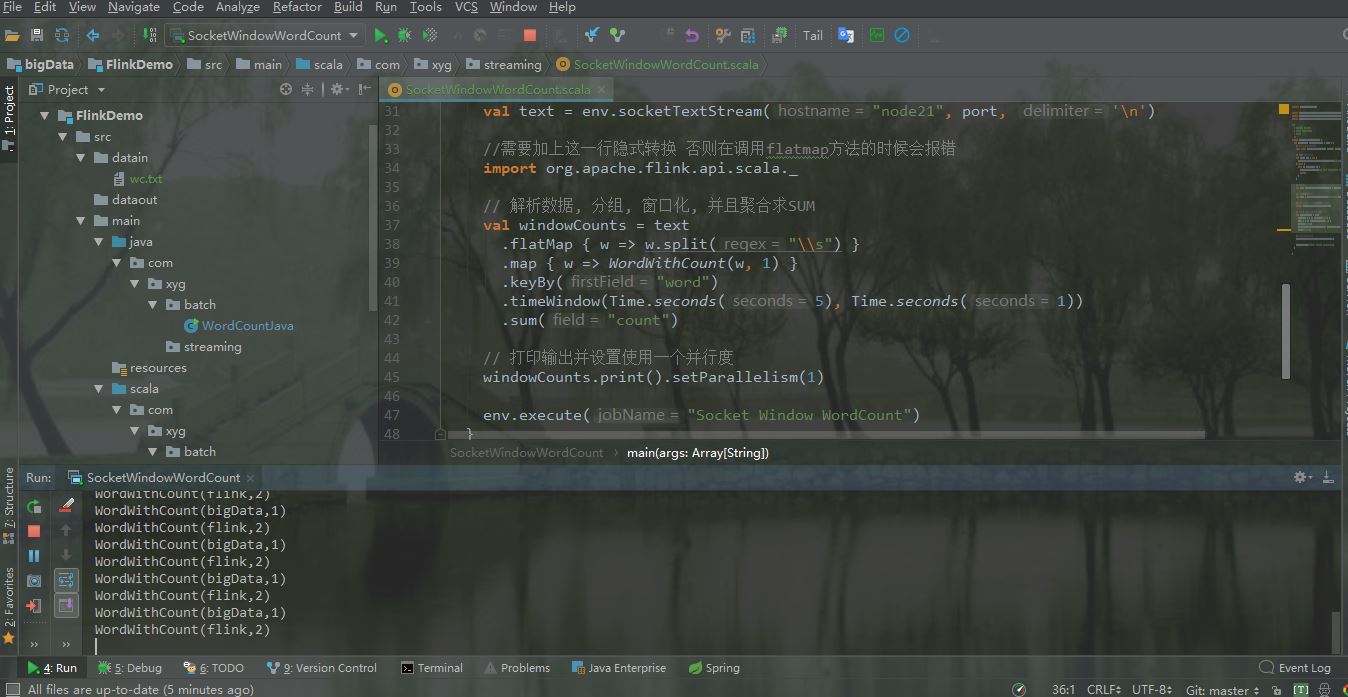
4.集群测试
这里单机测试官方案例
[admin@node21 flink-1.6.1]$ pwd/opt/flink-1.6.1[admin@node21 flink-1.6.1]$ ./bin/start-cluster.sh Starting cluster.Starting standalonesession daemon on host node21.Starting taskexecutor daemon on host node21.[admin@node21 flink-1.6.1]$ jpsStandaloneSessionClusterEntrypointTaskManagerRunnerJps[admin@node21 flink-1.6.1]$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
程序连接到套接字并等待输入。您可以检查Web界面以验证作业是否按预期运行:
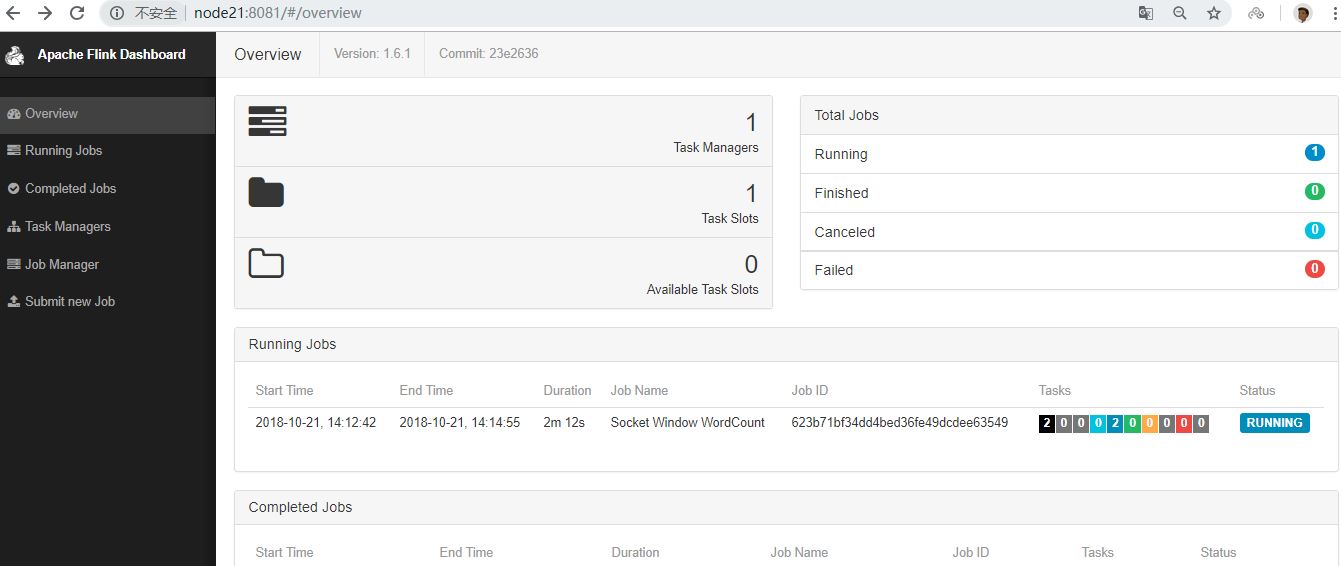
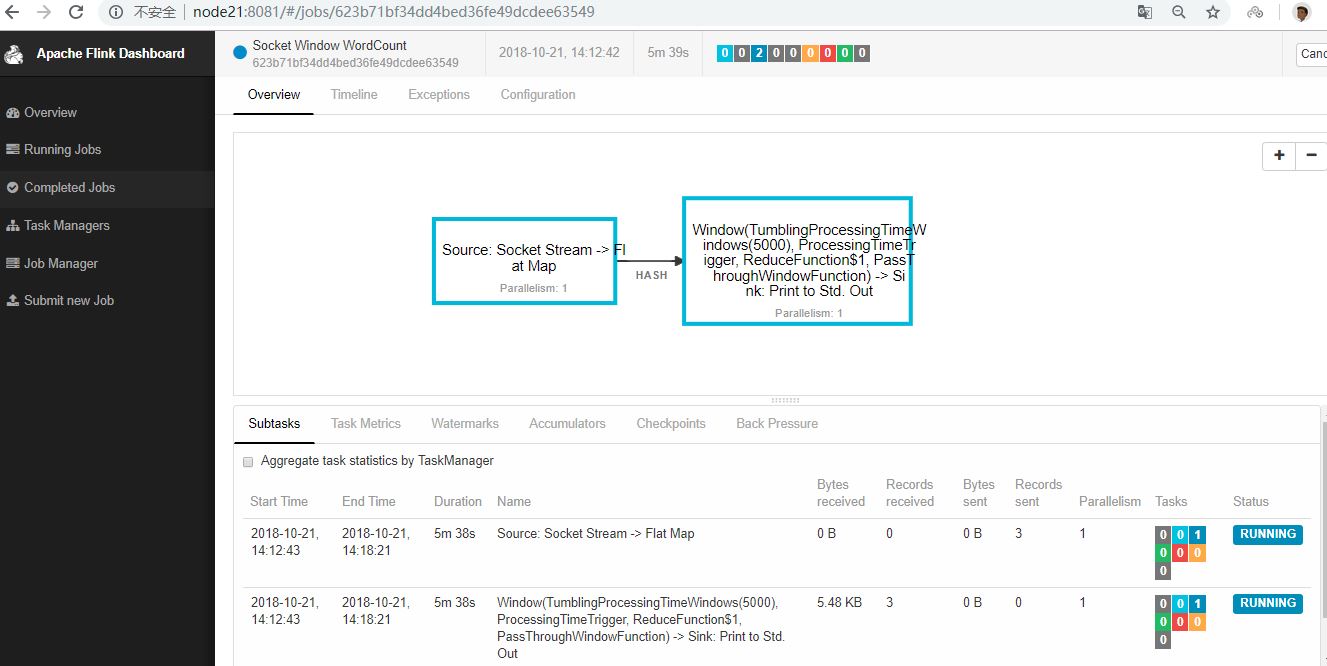
单词在5秒的时间窗口(处理时间,翻滚窗口)中计算并打印到stdout。监视TaskManager的输出文件并写入一些文本nc(输入在点击后逐行发送到Flink):
三.使用IDEA开发离线程序
Dataset是flink的常用程序,数据集通过source进行初始化,例如读取文件或者序列化集合,然后通过transformation(filtering、mapping、joining、grouping)将数据集转成,然后通过sink进行存储,既可以写入hdfs这种分布式文件系统,也可以打印控制台,flink可以有很多种运行方式,如local、flink集群、yarn等.
1. scala程序
package com.xyg.batchimport org.apache.flink.api.scala.ExecutionEnvironmentimport org.apache.flink.api.scala._/** * Author: Mr.Deng * Date: 2018/10/19 * Desc: */object WordCountScala{ def main(args: Array[String]) { //初始化环境 val env = ExecutionEnvironment.getExecutionEnvironment //从字符串中加载数据 val text = env.fromElements( 'Who’s there?', 'I think I hear them. Stand, ho! Who’s there?') //分割字符串、汇总tuple、按照key进行分组、统计分组后word个数 val counts = text.flatMap { _.toLowerCase.split('W+') filter { _.nonEmpty } } .map { (_, 1) } .groupBy(0) .sum(1) //打印 counts.print() }}
2. java程序
package com.xyg.batch;import org.apache.flink.api.common.functions.FlatMapFunction;import org.apache.flink.api.java.DataSet;import org.apache.flink.api.java.ExecutionEnvironment;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.util.Collector;/** * Author: Mr.Deng * Date: 2018/10/19 * Desc: */public class WordCountJava { public static void main(String[] args) throws Exception { //构建环境 final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //通过字符串构建数据集 DataSet<String> text = env.fromElements('Who’s there?','I think I hear them. Stand, ho! Who’s there?'); //分割字符串、按照key进行分组、统计相同的key个数 DataSet<Tuple2<String, Integer>> wordCounts = text.flatMap(new LineSplitter()).groupBy(0).sum(1); //打印 wordCounts.print(); } //分割字符串的方法 public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) { for (String word : line.split(' ')) {out.collect(new Tuple2<String, Integer>(word, 1)); } } }}
3.运行
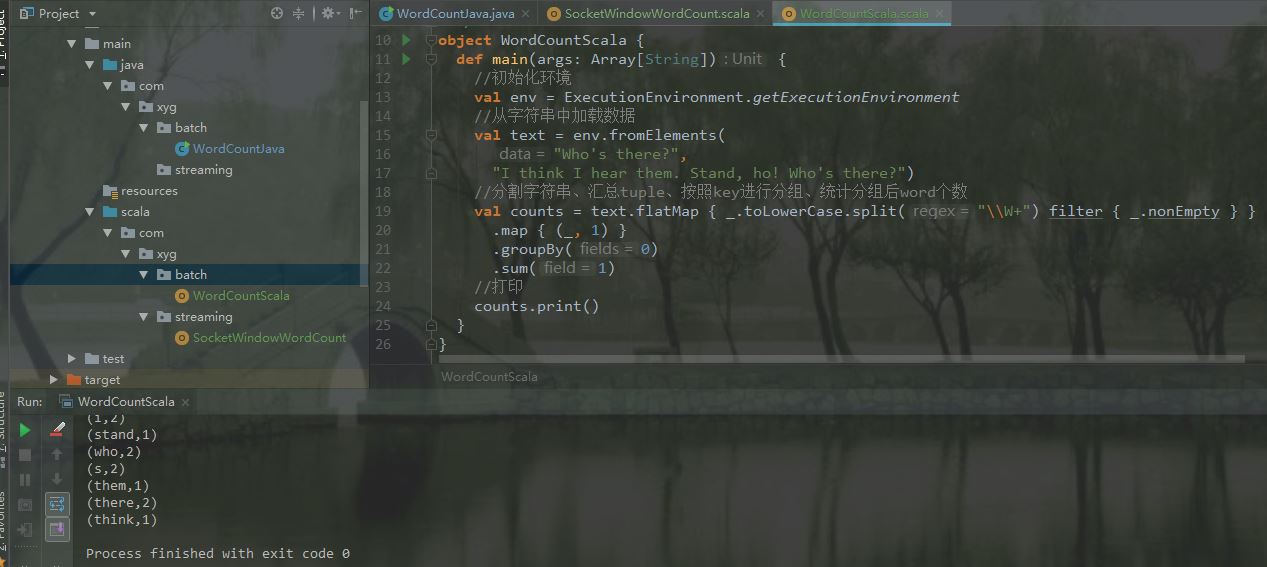
到此这篇关于Flink开发IDEA环境搭建与测试的方法的文章就介绍到这了,更多相关Flink IDEA环境搭建 内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
 网公网安备
网公网安备