django haystack实现全文检索的示例代码
全文检索里的组件简介
1. 什么是haystack?
1. haystack是django的开源搜索框架,该框架支持Solr,Elasticsearch,Whoosh, *Xapian*搜索引擎,不用更改代码,直接切换引擎,减少代码量。
2. 搜索引擎使用Whoosh,这是一个由纯Python实现的全文搜索引擎, 没有二进制文件等,比较小巧,配置比较简单,当然性能自然略低。
3. 中文分词Jieba,由于Whoosh自带的是英文分词,对中文的分词支持不是太好,故用jieba替换whoosh的分词组件
2. 什么是jieba?
很多的搜索引擎对中的支持不友好,jieba作为一个中文分词器就是加强对中文的检索功能
3. Whoosh是什么
1. Python的全文搜索库,Whoosh是索引文本及搜索文本的类和函数库
2. Whoosh 自带的是英文分词,对中文分词支持不太好,使用 jieba 替换 whoosh 的分词组件。
haystack配置使用(前后端分离)
1. 安装需要的包
pip3 install django-haystackpip3 install whooshpip3 install jieba
2. 在setting.py中配置
’’’注册app ’’’INSTALLED_APPS = [ ’django.contrib.admin’, ’django.contrib.auth’, ’django.contrib.contenttypes’, ’django.contrib.sessions’, ’django.contrib.messages’, ’django.contrib.staticfiles’, # haystack要放在应用的上面 ’haystack’, ’myapp’, # 这个jsapp是自己创建的app]’’’配置haystack ’’’# 全文检索框架配置HAYSTACK_CONNECTIONS = { ’default’: { # 指定whoosh引擎 ’ENGINE’: ’haystack.backends.whoosh_backend.WhooshEngine’, # ’ENGINE’: ’myapp.whoosh_cn_backend.WhooshEngine’, # whoosh_cn_backend是haystack的whoosh_backend.py改名的文件为了使用jieba分词 # 索引文件路径 ’PATH’: os.path.join(BASE_DIR, ’whoosh_index’), }}# 添加此项,当数据库改变时,会自动更新索引,非常方便HAYSTACK_SIGNAL_PROCESSOR = ’haystack.signals.RealtimeSignalProcessor’
3. 定义数据库
from django.db import models# Create your models here.class UserInfo(models.Model): name = models.CharField(max_length=254) age = models.IntegerField()class ArticlePost(models.Model): author = models.ForeignKey(UserInfo,on_delete=models.CASCADE) title = models.CharField(max_length=200) desc = models.SlugField(max_length=500) body = models.TextField()
索引文件生成
1. 在子应用下创建索引文件
在子应用的目录下,创建一个名为 myapp/search_indexes.py 的文件
from haystack import indexesfrom .models import ArticlePost# 修改此处,类名为模型类的名称+Index,比如模型类为GoodsInfo,则这里类名为GoodsInfoIndex(其实可以随便写)class ArticlePostIndex(indexes.SearchIndex, indexes.Indexable): # text为索引字段 # document = True,这代表haystack和搜索引擎将使用此字段的内容作为索引进行检索 # use_template=True 指定根据表中的那些字段建立索引文件的说明放在一个文件中 text = indexes.CharField(document=True, use_template=True) # 对那张表进行查询 def get_model(self): # 重载get_model方法,必须要有! # 返回这个model return ArticlePost # 建立索引的数据 def index_queryset(self, using=None): # 这个方法返回什么内容,最终就会对那些方法建立索引,这里是对所有字段建立索引 return self.get_model().objects.all()
2.指定索引模板文件
创建文件路径命名必须这个规范:templates/search/indexes/应用名称/模型类名称_text.txt如:templates/search/indexes/myapp/articlepost_text.txt
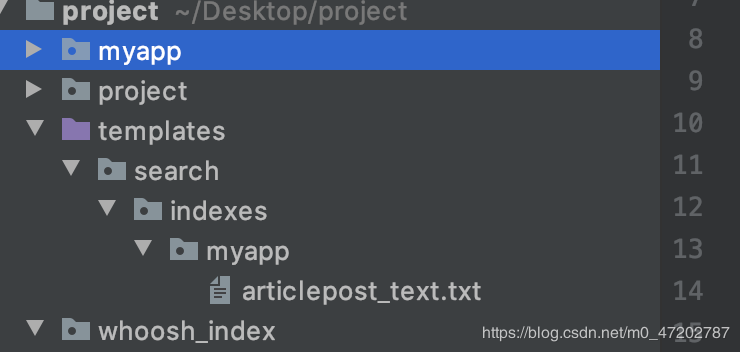
{{ object.title }}{{ object.author.name }}{{ object.body }}
3.使用命令创建索引
python manage.py rebuild_index # 建立索引文件
替换成jieba分词
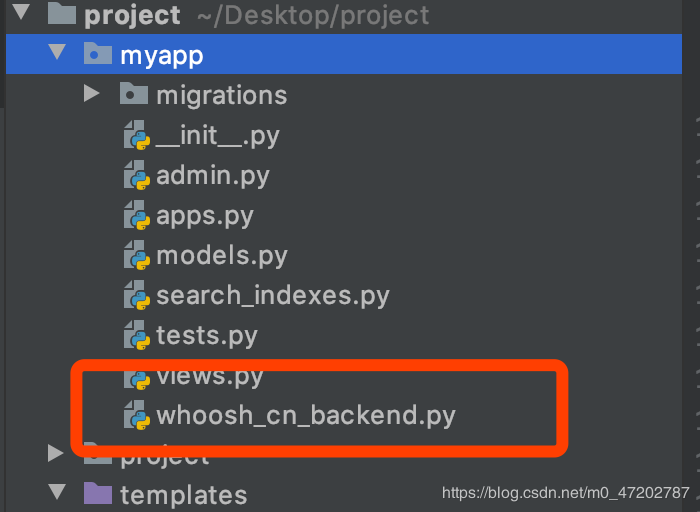
1.将haystack源码复制到项目中并改名
’’’1.复制源码中文件并改名 ’’’将 /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/haystack/backends/whoosh_backend.py文件复制到项目中并将 whoosh_backend.py改名为 whoosh_cn_backend.py 放在APP中如:myappwhoosh_cn_backend.py’’’2.修改源码中文件’’’# 在全局引入的最后一行加入jieba分词器from jieba.analyse import ChineseAnalyzer# 修改为中文分词法查找analyzer=StemmingAnalyzer()改为analyzer=ChineseAnalyzer()
索引文件使用
1. 编写视图
from django.shortcuts import render# Create your views here.import jsonfrom django.conf import settingsfrom django.core.paginator import InvalidPage, Paginatorfrom django.http import Http404, HttpResponse,JsonResponsefrom haystack.forms import ModelSearchFormfrom haystack.query import EmptySearchQuerySetRESULTS_PER_PAGE = getattr(settings, ’HAYSTACK_SEARCH_RESULTS_PER_PAGE’, 20)def basic_search(request, load_all=True, form_class=ModelSearchForm, searchqueryset=None, extra_context=None, results_per_page=None): query = ’’ results = EmptySearchQuerySet() if request.GET.get(’q’): form = form_class(request.GET, searchqueryset=searchqueryset, load_all=load_all) if form.is_valid(): query = form.cleaned_data[’q’] results = form.search() else: form = form_class(searchqueryset=searchqueryset, load_all=load_all) paginator = Paginator(results, results_per_page or RESULTS_PER_PAGE) try: page = paginator.page(int(request.GET.get(’page’, 1))) except InvalidPage: result = {'code': 404, 'msg': ’No file found!’, 'data': []} return HttpResponse(json.dumps(result), content_type='application/json') context = { ’form’: form, ’page’: page, ’paginator’: paginator, ’query’: query, ’suggestion’: None, } if results.query.backend.include_spelling: context[’suggestion’] = form.get_suggestion() if extra_context: context.update(extra_context) jsondata = [] print(len(page.object_list)) for result in page.object_list: data = { ’pk’: result.object.pk, ’title’: result.object.title, ’content’: result.object.body, } jsondata.append(data) result = {'code': 200, 'msg': ’Search successfully!’, 'data': jsondata} return JsonResponse(result, content_type='application/json')
到此这篇关于django haystack实现全文检索的示例代码的文章就介绍到这了,更多相关django haystack 全文检索内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
 网公网安备
网公网安备