Docker部署ELK7.3.0日志收集服务最佳实践
写在最前面
本文仅包含ELK7.3.0部署!
部署环境:
系统 CentOS 7 Docker Docker version 19.03.5 CPU 2核 内存 2.5G 磁盘 30G(推荐设置,磁盘不足可能会引发es报错) Filebeat v7.3.0,单节点 ElasticSearch v7.3.0,两份片 Kibana v7.3.0,单节点 Logstash v7.3.1,单节点
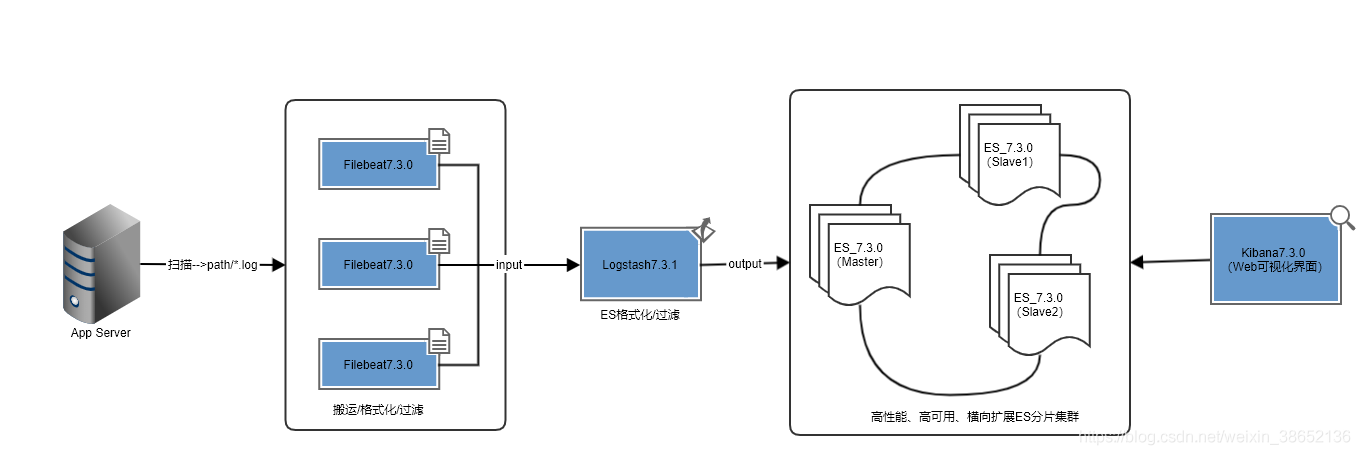
ELK分布式集群部署方案
linux中elasticsearch用户拥有的内存权限太小,至少需要262144,报错信息(max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]),因此先修改系统配置。
# 修改配置sysctl.confvi /etc/sysctl.conf# 添加下面配置:vm.max_map_count=262144# 重新加载:sysctl -p# 最后重新启动elasticsearch,即可启动成功。
环境均采用Docker部署,为了更方便的使用Docker命令,我们安装一下bash-completion自动补全插件:
# 安装依赖工具bash-completeyum install -y bash-completionource /usr/share/bash-completion/completions/dockersource /usr/share/bash-completion/bash_completion
部署顺序:ES --> Kibana --> Logstash --> Filebeat
ElasticSearch7.3.0部署
主节点部署
创建配置文件和数据存放目录
mkdir -p {/mnt/es1/master/data,/mnt/es1/master/logs}vim /mnt/es1/master/conf/es-master.yml
es-master.yml配置
# 集群名称cluster.name: es-cluster# 节点名称node.name: es-master# 是否可以成为master节点node.master: true# 是否允许该节点存储数据,默认开启node.data: false# 网络绑定network.host: 0.0.0.0# 设置对外服务的http端口http.port: 9200# 设置节点间交互的tcp端口transport.port: 9300# 集群发现discovery.seed_hosts: - 172.17.0.2:9300 - 172.17.0.3:9301# 手动指定可以成为 mater 的所有节点的 name 或者 ip,这些配置将会在第一次选举中进行计算cluster.initial_master_nodes: - 172.17.0.2# 支持跨域访问http.cors.enabled: truehttp.cors.allow-origin: '*'# 安全认证xpack.security.enabled: false#http.cors.allow-headers: 'Authorization'bootstrap.memory_lock: falsebootstrap.system_call_filter: false#解决跨域问题#http.cors.enabled: true#http.cors.allow-origin: '*'#http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE#http.cors.allow-headers: 'X-Requested-With, Content-Type, Content-Length, X-User'
pull镜像时会有些慢,耐心等待!
# 拉取镜像,可以直接构建容器,忽略此步docker pull elasticsearch:7.3.0# 构建容器## 映射5601是为Kibana预留的端口docker run -d -e ES_JAVA_OPTS='-Xms256m -Xmx256m' -p 9200:9200 -p 9300:9300 -p 5601:5601 -v /mnt/es1/master/conf/es-master.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mnt/es1/master/data:/usr/share/elasticsearch/data -v /mnt/es1/master/logs:/usr/share/elasticsearch/logs -v /etc/localtime:/etc/localtime --name es-master elasticsearch:7.3.0
/etc/localtime:/etc/localtime:宿主机与容器时间同步。
从节点部署
创建配置文件和数据存放目录
mkdir -p {/mnt/es1/slave1/data,/mnt/es1/slave1/logs}vim /mnt/es1/slave1/conf/es-slave1.yml
es-slave1.yml配置
# 集群名称cluster.name: es-cluster# 节点名称node.name: es-slave1# 是否可以成为master节点node.master: true# 是否允许该节点存储数据,默认开启node.data: true# 网络绑定network.host: 0.0.0.0# 设置对外服务的http端口http.port: 9201# 设置节点间交互的tcp端口transport.port: 9301# 集群发现discovery.seed_hosts: - 172.17.0.2:9300 - 172.17.0.3:9301# 手动指定可以成为 mater 的所有节点的 name 或者 ip,这些配置将会在第一次选举中进行计算cluster.initial_master_nodes: - 172.17.0.2# 支持跨域访问http.cors.enabled: truehttp.cors.allow-origin: '*'# 安全认证xpack.security.enabled: false#http.cors.allow-headers: 'Authorization'bootstrap.memory_lock: falsebootstrap.system_call_filter: false
pull镜像时会有些慢,耐心等待!
# 拉取镜像,可以直接构建容器,忽略此步docker pull elasticsearch:7.3.0# 构建容器docker run -d -e ES_JAVA_OPTS='-Xms256m -Xmx256m' -p 9201:9200 -p 9301:9300 -v /mnt/es1/slave1/conf/es-slave1.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mnt/es1/slave1/data:/usr/share/elasticsearch/data -v /mnt/es1/slave1/logs:/usr/share/elasticsearch/logs -v /etc/localtime:/etc/localtime --name es-slave1 elasticsearch:7.3.0
修改配置重启容器
# 查看主从容器IPdocker inspect es-masterdocker inspect es-slave1
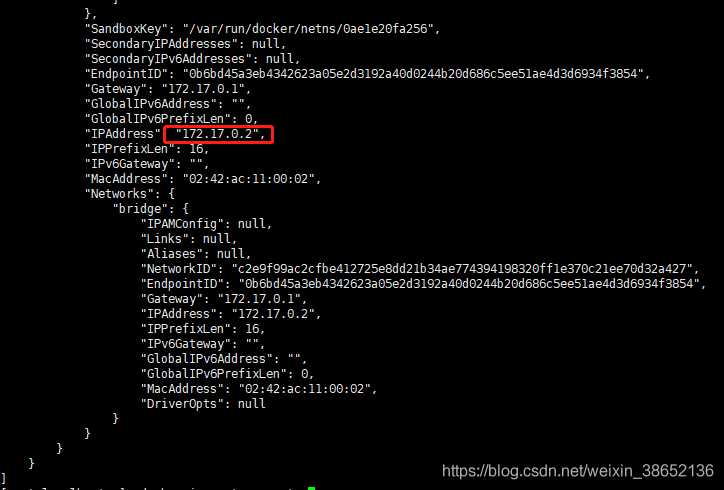
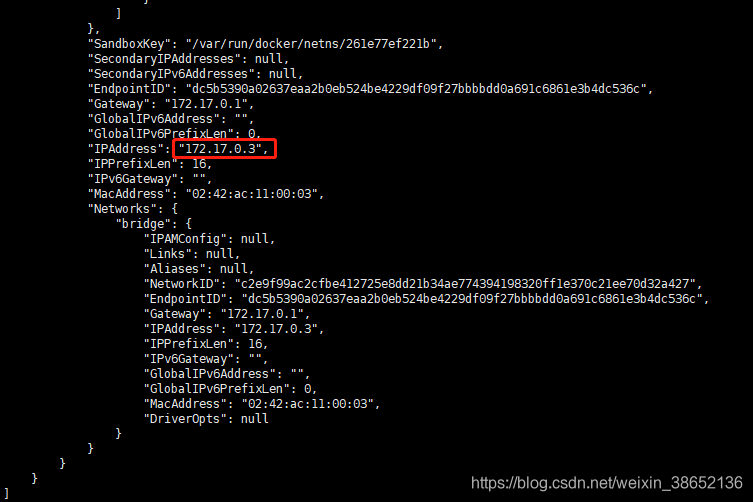
修改ES配置文件es-master.yml、es-slave1.yml中的discovery.seed_hosts、cluster.initial_master_nodes为对应的IP!重启容器:
docker restart es-masterdocker restart es-slave1# 查看es日志docker logs -f --tail 100f es-master
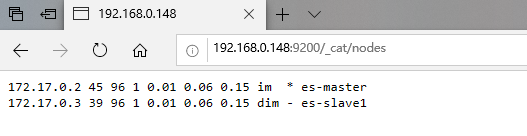
访问http://IP:9200/_cat/nodes确认查看ES集群信息,可以看到有主从节点部署成功:
节点部署常用API:
API 功能 http://IP:9200 查看ES版本信息 http://IP:9200/_cat/nodes
查看所有分片
http://IP:9200/_cat/indices 查看所有索引Kibana7.3.0部署
创建Kibana配置文件
vim /mnt/kibana.yml### ** THIS IS AN AUTO-GENERATED FILE **##### Default Kibana configuration for docker targetserver.name: kibana#配置Kibana的远程访问server.host: '0.0.0.0'#配置es访问地址elasticsearch.hosts: [ 'http://127.0.0.1:9200' ]#汉化界面i18n.locale: 'zh-CN'#xpack.monitoring.ui.container.elasticsearch.enabled: true
查看es-master容器ID
docker ps|grep es-master

部署Kibana
注意将命令中的40eff5876ffd 修改成es-master容器ID,拉取镜像,情耐性等待!
# 拉取镜像,可以直接构建容器,忽略此步docker pull docker.elastic.co/kibana/kibana:7.3.0# 构建容器## --network=container 表示共享容器网络docker run -it -d -v /mnt/kibana.yml:/usr/share/kibana/config/kibana.yml -v /etc/localtime:/etc/localtime -e ELASTICSEARCH_URL=http://172.17.0.2:9200 --network=container:40eff5876ffd --name kibana docker.elastic.co/kibana/kibana:7.3.0
查看Kibana容器日志,看到如下图所示日志则表示启动成功
docker logs -f --tail 100f kibana

访问http://IP:5601,可能会出现503,等一会在访问就OK了。可以访问到Kibana控制台则表示Kibana已安装成功,并已于es-master建立连接。
Logstash7.3.1部署
编写Logstash配置文件
vim /mnt/logstash-filebeat.conf
input { # 来源beats beats { # 端口 port => '5044' }}# 分析、过滤插件,可以多个filter { grok {# grok 表达式存放的地方patterns_dir => '/grok'# grok 表达式重写 # match => {'message' => '%{SYSLOGBASE} %{DATA:message}'}# 删除掉原生 message字段overwrite => ['message'] # 定义自己的格式match => {'message' => '%{URIPATH:request} %{IP:clientip} %{NUMBER:response:int} '%{WORD:sources}' (?:%{URI:referrer}|-) [%{GREEDYDATA:agent}] {%{GREEDYDATA:params}}'} } # 查询归类插件 geoip { source => 'message' }}output {# 选择elasticsearchelasticsearch {# es 集群hosts => ['http://172.17.0.2:9200'] #username => 'root' #password => '123456'# 索引格式index => 'omc-block-server-%{[@metadata][version]}-%{+YYYY.MM.dd}'# 设置为true表示如果你有一个自定义的模板叫logstash,那么将会用你自定义模板覆盖默认模板logstashtemplate_overwrite => true}}
部署Logstash
# 拉取镜像,可以直接构建容器,忽略此步docker pull logstash:7.3.1 # 构建容器# xpack.monitoring.enabled 打开X-Pack的安全和监视服务# xpack.monitoring.elasticsearch.hosts 设置ES地址,172.17.0.2为es-master容器ip# docker允许在容器启动时执行一些命令,logsatsh -f 表示通过指定配置文件运行logstash,/usr/share/logstash/config/logstash-sample.conf是容器内的目录文件docker run -p 5044:5044 -d -v /mnt/logstash-filebeat.conf:/usr/share/logstash/config/logstash-sample.conf -v /etc/localtime:/etc/localtime -e elasticsearch.hosts=http://172.17.0.2:9200 -e xpack.monitoring.enabled=true -e xpack.monitoring.elasticsearch.hosts=http://172.17.0.2:9200 --name logstash logstash:7.3.1 -f /usr/share/logstash/config/logstash-sample.conf
这里需要注意es集群地址,这里我们只配置es-master的ip(172.17.0.2),详细Logstash配置。 查看到如下日志则表示安装成功:

Filebeat7.3.0部署
Filebeat 并不是一个必须的组件,通过Logstash我们同样也可以实现日志的搬运工作。
例如,实现将所有非“20”开头的日志进行合并,可以使用如下Logstash配置:
input { # 来源beats beats { # 端口 port => '5044' } file { type => 'server-log' path => '/logs/*.log' start_position => 'beginning' codec=>multiline{// 正则表达式,所有“20”前缀日志, 如果你的日志是以“[2020-06-15”这类前缀则,可以替换成'^['pattern => '^20'// 是否对正则规则取反negate => true// previous 表示合并到上一行,next 表示合并到下一行what => 'previous' } }}
注意,Filebeat必须与应用部署在同一服务器,这里应用采用docker部署,/mnt/omc-dev/logs应用日志文件的映射目录,如果你也是通过docker进行服务部署,请记得通过【-v /mnt/omc-dev/logs:/应用工作/logs】日志文件映射出来哦!
创建Filebeat配置文件
## /mnt/omc-dev/logs 为应用日志目录,必须将应用的部署目录映射出来mkdir -p {/mnt/omc-dev/logs,/mnt/filebeat/logs,/mnt/filebeat/data}vim /mnt/filebeat/filebeat.yml
filebeat.inputs:- type: log enabled: true paths: # 当前目录下的所有.log文件 - /home/project/spring-boot-elasticsearch/logs/*.log multiline.pattern: ’^20’ multiline.negate: true multiline.match: previouslogging.level: debugfilebeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled: falsesetup.template.settings: index.number_of_shards: 1setup.dashboards.enabled: falsesetup.kibana: host: 'http://172.17.0.2:5601'# 不直接传输至ES#output.elasticsearch:# hosts: ['http://es-master:9200']# index: 'filebeat-%{[beat.version]}-%{+yyyy.MM.dd}'output.logstash: hosts: ['172.17.0.5:5044']#scan_frequency: 1sclose_inactive: 12hbackoff: 1smax_backoff: 1sbackoff_factor: 1flush.timeout: 1sprocessors: - add_host_metadata: ~ - add_cloud_metadata: ~
注意修改Logstash IP和端口。
# 拉取镜像,可以直接构建容器,忽略此步docker pull docker.elastic.co/beats/filebeat:7.3.0# 构建容器## --link logstash 将指定容器连接到当前连接,可以设置别名,避免ip方式导致的容器重启动态改变的无法连接情况,logstash 为容器名docker run -d -v /mnt/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml -v /mnt/omc-dev/logs:/home/project/spring-boot-elasticsearch/logs -v /mnt/filebeat/logs:/usr/share/filebeat/logs -v /mnt/filebeat/data:/usr/share/filebeat/data -v /etc/localtime:/etc/localtime --link logstash --name filebeat docker.elastic.co/beats/filebeat:7.3.0
查看日志,我们在配置文件中将Filebeat的日志级别配置成了debug,因此会开到所有收录到的信息
docker logs -f --tail 100f filebeat
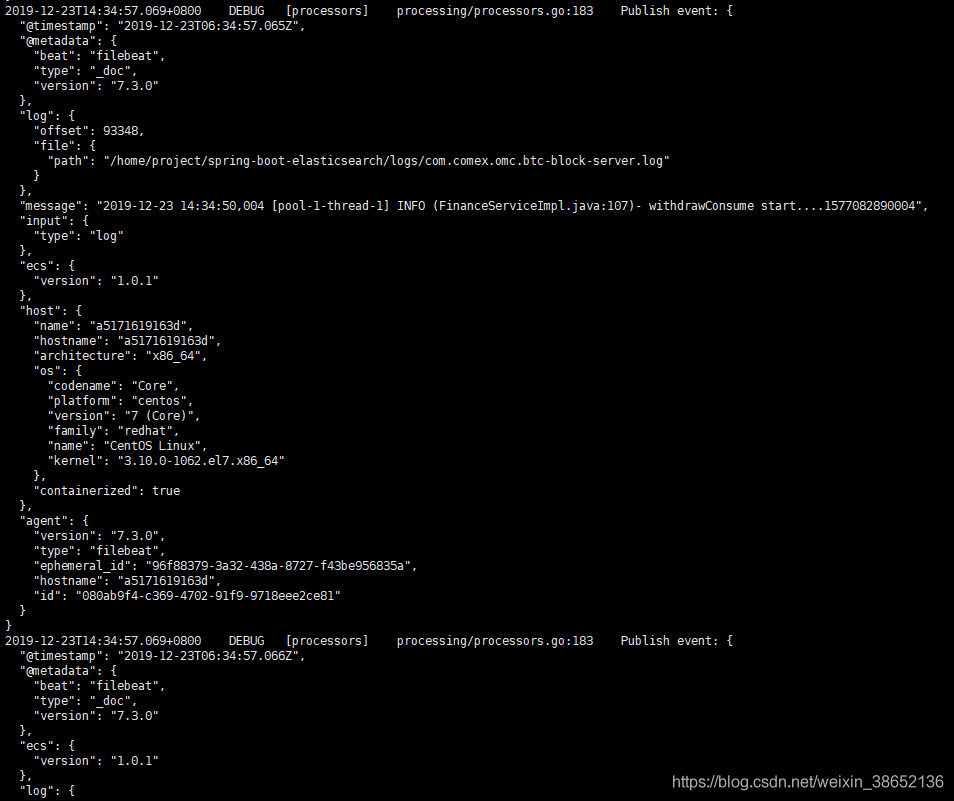
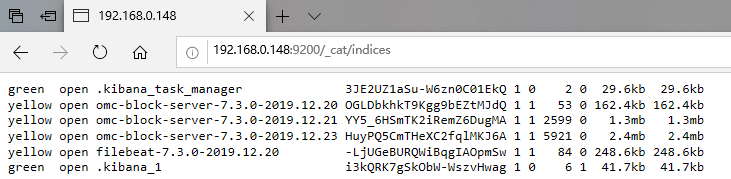
可以看到,通过查询ES索引,多出了三条索引,通过我们配置的按天进行索引分割,因为我这个环境已经跑了三天了,所以存在三个omc服务的索引(omc 是一个定时任务的服务,你也可以写一个简单的定时任务来进行测试)。
接下来我们创建一个Kibana索引模式,并进行日志查询:
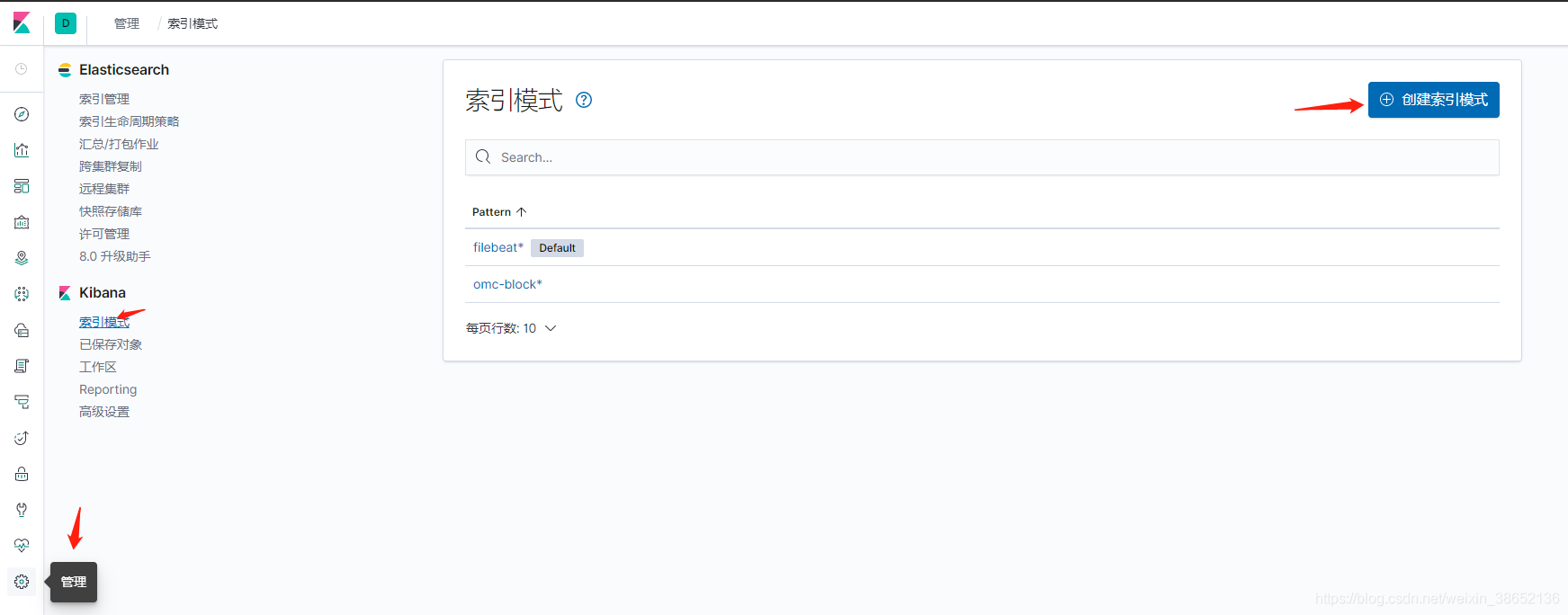
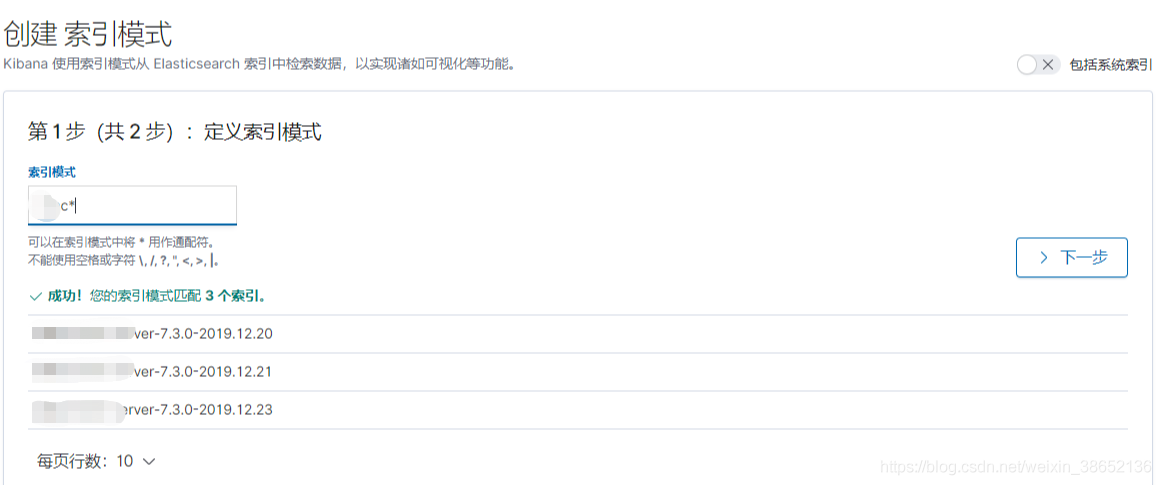
索引创建完成,到Discover视图就可以通过索引模式查询日志了。
文章到这里就结束了,如果你还有别的服务需要引入的话,只需要将日志挂载到指定目录就行了,当然如果服务是部署在其他服务器上,则需要在服务器上部署Filebeat,并且要保证服务器之间网络互通哦~~
最后,在这里推荐一个开源ELK自动化Docker部署项目:https://github.com/deviantony/docker-elk.git
--------------------------------------------------------
2020.6.28更新
最近发生了一起Logstash导致的物理内存暴涨问题。
简单阐述一下主要问题:
目前单服务单日日志量在2.2GB左右,由于早期没有限制Logstash内存,导致大量数据上来时,Logstash疯狂占用内存与IO。
随着近日,在同一服务器上面应用服务流量上涨,最终导致内存不足,出现OutOfMemoryError问题。
随后,通过设置优化JVM内存(具体我就不说了,网上一大把),并添加上Logstash响应内存配置,得以解决早前的遗留问题。
最后,将Logstash 添加到Kibana进行监控(当然你还可以将Logstash日志配置到ES上去):
https://blog.csdn.net/QiaoRui_/article/details/97667293
相关文章:

 网公网安备
网公网安备