mysql中的utf8与utf8mb4存储及区别
目录
- 一、如何设置utf8mb4
- 二、问题
- 1、为什么存储的时候要区分utf8和utf8mb4
- 2、为什么读取的时候要区分utf8和utf8mb4
一、如何设置utf8mb4
mysql中针对字符串类型,在设置charset的时候可以精确到字段。
如果只将某个字段设置utf8mb4,那么其他字段不会受影响。
如果针对表来设置,那么已经存在的字段依然是utf8,并且会多出utf8的标记,之后所创建的字段才会是utf8mb4。
如果针对库来设置,那么已经存在的表依然是utf8,之后所创建的表才会是utf8mb4。
除此之外呢,我们在连接数据库的时候,也要指明charset=utf8mb4,否则的话,此连接无法向utf8mb4的字段写入数据,并且读取的时候是乱码。
在使用 navicat 的时候,发现没有地方设置连接的字符编码,他会自动扫面你的数据库,表,字段的编码,来自动设置一个合适的编码,当然,这也跟 navicat 版本有关,高版本才行,我的低版本就不行,如果你发现你的 navicat 无法显示表情,只能看到问好,那么可以通过show variables like '%char%'查看一下。
我还遇到一个情况,我的 navicat 没法自动设置 utf8mb4,因此,在 utf8 的情况下,我将线上的表情同步到了我本地,这使得我在后面即使设置了 utf8mb4 的情况下也看不到表情,这是因为我在 utf8 的时候同步过来的数据被破坏了,字符集不兼容,所以需要先设置好字符编码再拉取一次数据。
二、问题
1、为什么存储的时候要区分utf8和utf8mb4
按理说,不管我存进去的是单字节还是多字节,本质都是二进制,我写入什么你就存什么不就好了,干嘛还要有限制。这是因为,Mysql对每个字段都定义了长度,比如varchar(10)表示10个字符,而不是字节,所以当存入数据的时候,mysql是做了解析的,这样才能知道字符串里有几个字符;当面对4字节字符的时候,mysql依然会以3字节的编码规则来解析,显然会解析出错的,因此就不让写入。
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。好在 utf8mb4 是 utf8 的超集,除了将编码改为 utf8mb4 外不需要做其他转换。当然,为了节省空间,一般情况下使用 utf8 也就够了。
utf8 是 Mysql 中的一种字符集,只支持最长三个字节的 UTF-8 字符,可能是因为 Mysql 刚开始开发那会,Unicode 还没有4字节的字符。至于后续的版本为什么不对 4 字节长度的 UTF-8 字符提供支持,应该是为了向后兼容性的考虑,还有就是4字节字符确实很少用到。
2、为什么读取的时候要区分utf8和utf8mb4
按理说,我读取的都是二进制,不管是三字节还是四字节,我自己来展示,为什么在读取 utf8mb4 字段的时候,我使用 utf8 的连接得到的是乱码,使用 utf8mb4 连接得到的是正常的。实际上我的电脑是能展示四字节字符的。
因为mysql有个连接器组件,它处于客户端和服务器之间,用于字符集的转换。
现在有一个字段name,为了兼容emoj表情,字段设置为utf8mb4,在写入的时候数据库连接设置了charset=utf8mb4,因此可以正常写入;在读取的时候数据库连接设置charset=utf8,于是读出来展示的时候是乱码,如果改成charset=utf8mb4,读出来就能正常展示,那就是说,utf8的连接读到的结果并不是真实的数据,而是经过了连接器的转换,它将utf8mb4转换成了utf8,四字节字符被转换成了三字节,自然就是乱码。
那么,为什么要有这个转码的过程呢?
那是因为mysql支持很多的字符编码。
mysql> show character set;+----------+-----------------------------+---------------------+--------+| Charset | Description | Default collation | Maxlen |+----------+-----------------------------+---------------------+--------+| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 || dec8 | DEC West European | dec8_swedish_ci | 1 || cp850 | DOS West European | cp850_general_ci | 1 || hp8 | HP West European | hp8_english_ci | 1 || koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 || latin1 | cp1252 West European| latin1_swedish_ci | 1 || latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 || swe7 | 7bit Swedish| swe7_swedish_ci | 1 || ascii | US ASCII | ascii_general_ci | 1 || ujis | EUC-JP Japanese | ujis_japanese_ci | 3 || sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 || hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 || tis620 | TIS620 Thai | tis620_thai_ci | 1 || euckr | EUC-KR Korean | euckr_korean_ci | 2 || koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 || gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 || greek | ISO 8859-7 Greek | greek_general_ci | 1 || cp1250 | Windows Central European | cp1250_general_ci | 1 || gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 || latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 || armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 || utf8 | UTF-8 Unicode | utf8_general_ci | 3 || ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 || cp866 | DOS Russian | cp866_general_ci | 1 || keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 || macce | Mac Central European| macce_general_ci | 1 || macroman | Mac West European | macroman_general_ci | 1 || cp852 | DOS Central European| cp852_general_ci | 1 || latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 || utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 || cp1251 | Windows Cyrillic | cp1251_general_ci | 1 || utf16 | UTF-16 Unicode | utf16_general_ci | 4 || utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 || cp1256 | Windows Arabic | cp1256_general_ci | 1 || cp1257 | Windows Baltic | cp1257_general_ci | 1 || utf32 | UTF-32 Unicode | utf32_general_ci | 4 || binary | Binary pseudo charset | binary | 1 || geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 || cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 || eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |+----------+-----------------------------+---------------------+--------+40 rows in set
collation为排序规则,Maxlen为最大字节数。
不同的编码规则,会得到不同的二进制数,因此正确的编码转换是必要的。
查看当前的编码
mysql> show variables like "%char%";+--------------------------+--------+| Variable_name | Value |+--------------------------+--------+| character_set_client | utf8 || character_set_connection | utf8 || character_set_database | utf8 || character_set_filesystem | binary || character_set_results | utf8 || character_set_server | utf8 || character_set_system | utf8 || character_sets_dir ||+--------------------------+--------+
设置当前连接的编码,只针对此连接有效
mysql -h xxxxxx.mysql.rds.aliyuncs.com -u xxxxxx -p xxxxxxmysql> set names gbk;mysql> show variables like "%char%";+--------------------------+--------+| Variable_name | Value |+--------------------------+--------+| character_set_client | gbk || character_set_connection | gbk || character_set_database | utf8 || character_set_filesystem | binary || character_set_results | gbk || character_set_server | utf8 || character_set_system | utf8 || character_sets_dir ||+--------------------------+--------+
这个命令会同时修改character_set_client, character_set_connection, character_set_results
我们在接数据库的时候设置的charset=utf8在内部就是调用的set names utf8。
所以,代表客户端的编码有三个,这三个编码基本是一致的。其他的都是服务端的的编码。
character_set_client 客户端
character_set_connection 连接器
character_set_results 返回的结果集
既然是一样的,为什么客户端要搞三个配置呢,这就要从数据传输的流程上来看。
连接器:连接客户端与服务端,进行字符集的转换。
连接器的工作流程:
请求
character_set_client --> character_set_connection -->character_set_server
响应
character_set_server --> character_set_connection --> character_set_results
图示
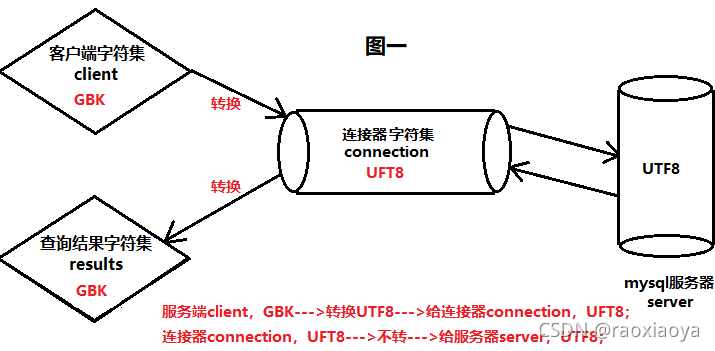
到此这篇关于mysql中的utf8与utf8mb4存储及区别的文章就介绍到这了,更多相关mysql utf8与utf8mb4内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!

 网公网安备
网公网安备