高并发状态下Replace Into造成的死锁问题解决
目录
- 1.问题出现:
- 2.分析解决
- 3.解决方案:
1.问题出现:
在测试阶段,大数据并发的情况下,发现sql语句造成表的死锁,过一段时间,死锁消失。于是进行排查
报错如下:
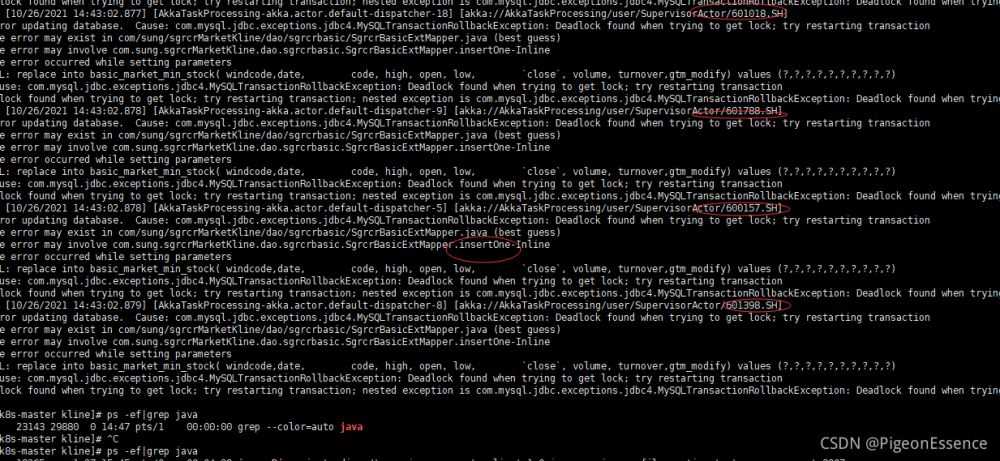
对应的sql语句如下:
@Insert("replace into ${tableName}( windcode,date, \n" + " code, high, open, low, \n" + " `close`, volume, turnover,gtm_modify) " + "values (#{obj.windcode},#{obj.date},#{obj.code},#{obj.high},#{obj.open},#{obj.low},#{obj.close},#{obj.volume},#{obj.turnover},#{obj.updateTime})" ) int insertOne(@Param("obj") KDTO obj, @Param("tableName") String tableName);在排除了数据问题和线程重复调用以后,我们关注了一下sql语句本身。 看了网上很多经验分享,觉得问题可能出现在 Replace Into 语句上。
2.分析解决
首先我们分析一下为什么并发replace into导致MySQL死锁
Replace into 一般作用是,当存在冲突时,会把旧记录替换成新的记录。也就是说这条语句执行,分为了两个大步:判断和执行
1.判断:
首先判断我们需要操作的记录是否存在(根据主键或者唯一索引判断)
2.操作:
- 针对不存在的记录,语句会执行insert,插入操作。
- 针对已经存在的记录,语句可以拆分为delete+insert操作
测试:
建立表
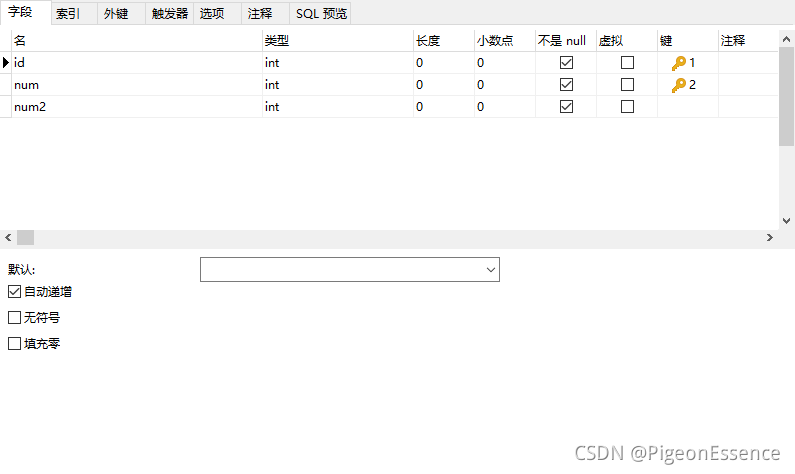
插入数据:
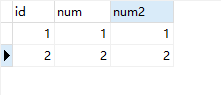
我们使用replace into语句去执行一个已经存在的数据:
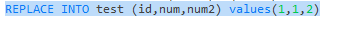
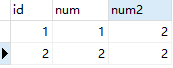
可以清楚的发现,影响的行数是两行
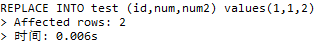
第一行的数据被修改了
我们使用replace into语句去执行一个不存在的数据:
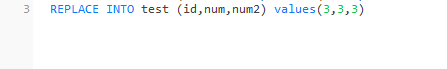
可以清楚的发现,影响的行数是一行

执行了插入操作:
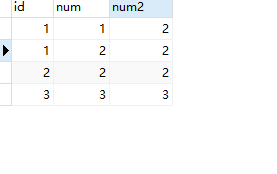
逻辑非常的清晰,但是这种单条sql语句在什么情况下会出现死锁呢?我们就要去考虑这个加锁的时机。
正常的插入逻辑是:
- 首先插入聚集索引记录,在上例中id列为自增列。
- 随后插入二级索引num,由于其是唯一索引,在检查duplicate key时,为其加上类型为LOCK_X的记录锁。
发现错误:
- 由于检测到duplicate key,因此第一步插入的聚集索引记录需要被回滚掉(row_undo_ins)。
- 从InnoDB层失败返回到Server层后,收到duplicate key错误,首先检索唯一键冲突的索引,并对冲突的索引记录(及聚集索引记录)加锁。
转换模式:
如果发生uk冲突的索引是最后一个唯一索引、没有外键引用、且不存在delete trigger时,使用UPDATE ROW的方式来解决冲突;
否则,使用DELETE ROW + INSERT ROW的方式解决冲突。
更新记录:
- 对于聚集索引,由于PK列发生变化,采用delete + insert 聚集索引记录的方式更新。
- 对于二级uk索引,同样采用标记删除 + 插入的方式。
所以死锁的问题多半就会出现在X记录锁上面。
死锁分析:
所以再多线程高并发的环境状态下,存在两个事务同时去获取一个记录的修改的情况:
- 事务1拿到X记录锁,
- 事务2检测到冲突,获取X|NK锁,被事务1阻塞
- 事务1检测到冲突,申请获取S|NK,被事务2阻塞
所以在等待执行期间sql会有死锁报错,高并发环境下的死锁也就出现了,再事务执行完成回滚操作以后,死锁回滚,也就解释了死锁消失的问题。
3.解决方案:
经过多方讨论,最终决定使用 insetr + ON DUPLICATE KEY UPDATE语句替换高并发环境下的Replace Into语句解决死锁问题。
ON DUPLICATE KEY UPDATE语句的作用是:
若该数据的主键值/ UNIQUE KEY 已经在表中存在,则执行更新操作, 即UPDATE 后面的操作。
否则插入一条新的记录。
实现了Replace Into有相同的查重替换功能,而避免了高并发的死锁问题。
但是UPDATE操作性能相比DELETE操作会有一定的性能上的影响,需要后续测试跟进。
到此这篇关于高并发状态下Replace Into造成的死锁问题解决的文章就介绍到这了,更多相关Replace Into死锁内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
相关文章:
 网公网安备
网公网安备