MySQL之索引结构解读
目录
- MySQL索引是什么
- 二叉树
- 红黑树
- B+Tree
- 总结
MySQL索引是什么
MySQL索引就是帮助MySQL高效获取数据的数据结构。
这个数据结构也就是我们常说的二叉树、红黑树、Hash表等索引数据结构,借助这样的数据结构,相较于之前的全局遍历查询,能够更高效的进行查询。
简单复习一下一些常见的索引数据结构:
二叉树
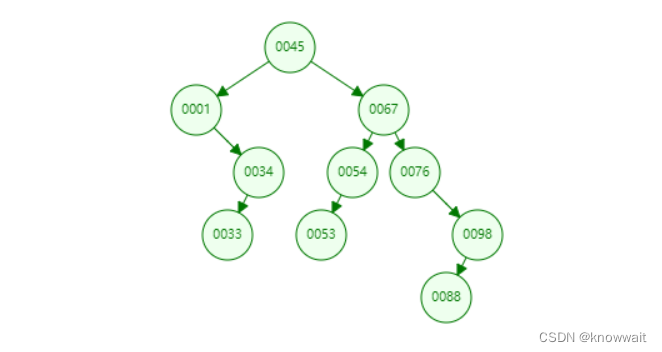
上图是一个二叉树,他根据我们存放数据的顺序依次填充这个树结构,比根节点小的数放到左边,比根节点大的放在右边,这样我们去查找的时候不需要遍历所有数据,只需要依次与根节点以及下面的子节点对比就可以查找到我们要找的元素。
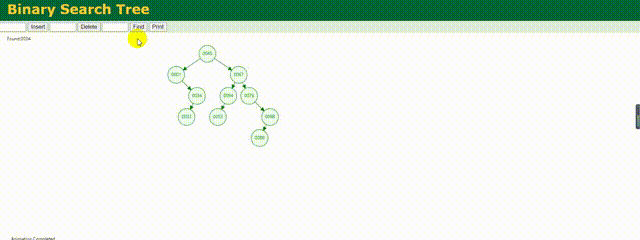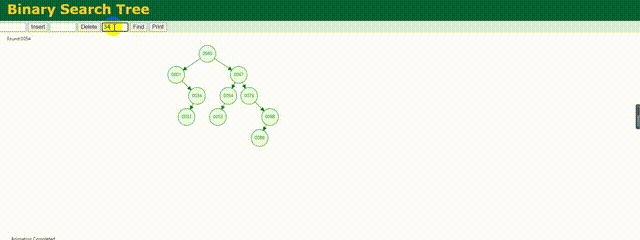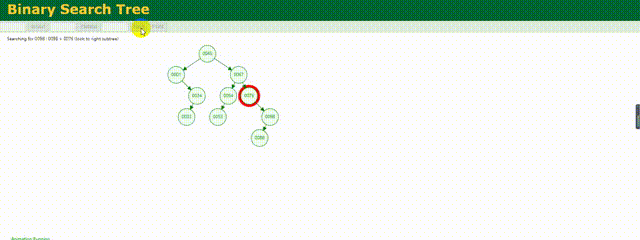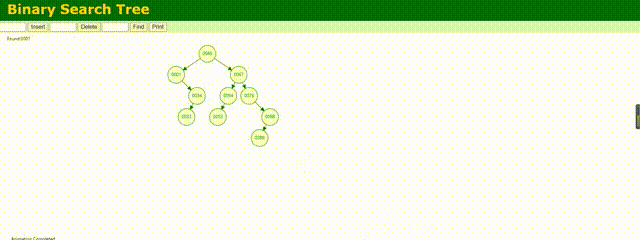
查找流程示例图:
根据这个动态图左上角的比对信息,可以很清楚的看到二叉树的查询逻辑,感兴趣的可以去这个网址实际模拟下:Data Structure Visualization
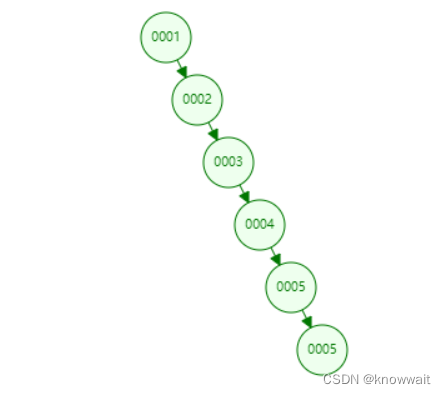
但是上述查询逻辑是在数据无大小规律存储的情况下进行查询的,如果我们的数据按照大小顺序存储会出现以下情况:这其实虽然叫二叉树但实际上已经是链表结构了,假如我们要查询较为底层的数据,还是要遍历全局。
MySQL底层不是使用的二叉树结构。
红黑树
相较于上述的二叉树,红黑树做了相应的优化,他会根据存储的数据动态调整根节点保证树左右两边的平衡,红黑树也是一种平衡树。
下面来动态的看下他是如何存储数据的:
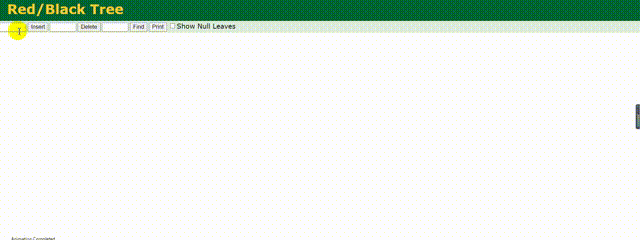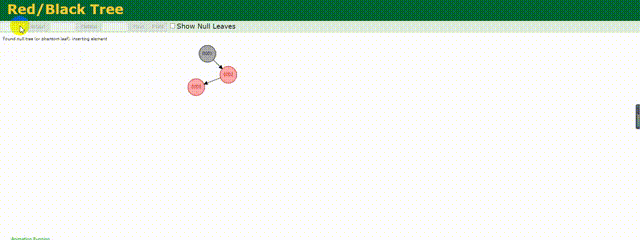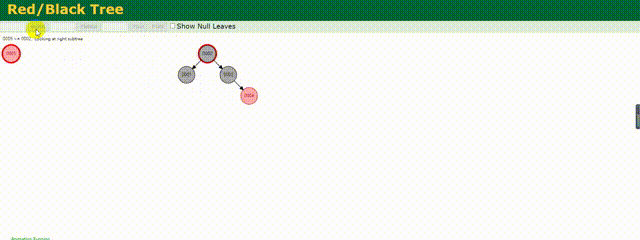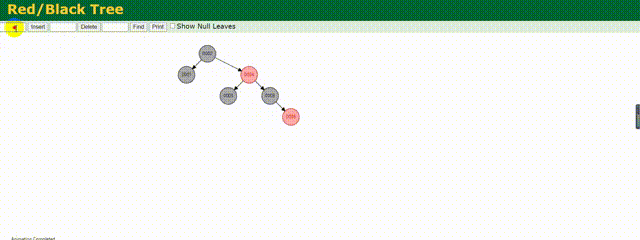
可以明显的看到他动态调整树的结构,其实也就是减少了树的深度,相较于上面变为链式的二叉树,他的效率还是较高的,但是这仅仅适用于数据量不是很大的情况,如果数据量百万甚至千万,这个树的深度一样很深,查询起来效率依旧不高。所以MySQL底层也不是使用的红黑树结构。
那MySQL使用的那种数据结构来存储索引数据的呢?
B+Tree
MySQL底层其实是使用的B+Tree的数据结构存储的
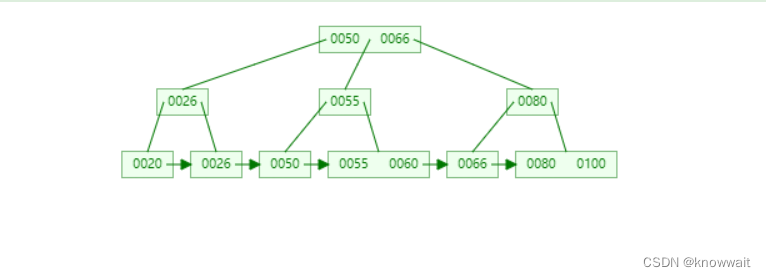
这个结构相对于上述两种结构都有点复杂了,用更详细一点的图来表达可以这么看,他实际上还是树,但是一个树节点上不只有一个索引数据,只有最底层的叶子节点上才有数据(这个数据就是我们mysql表中的一列数据或者是mysql数据对应的磁盘地址),而其他节点只存储索引,也叫作冗余索引。
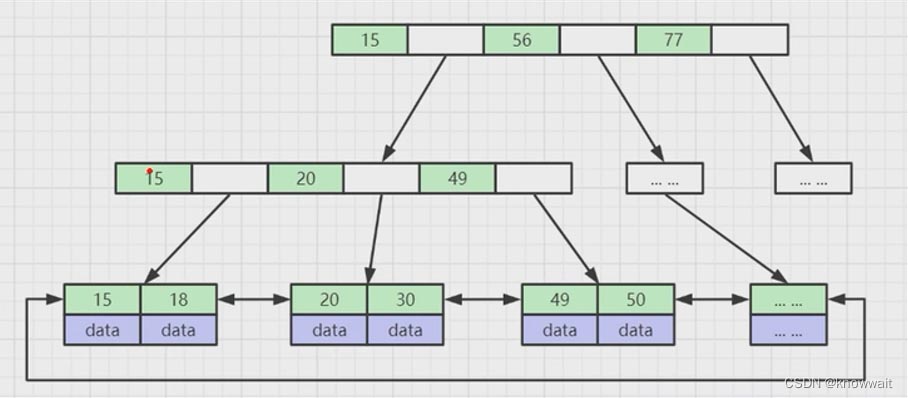
这样的索引结构有什么好处呢?
在我们创建数据库索引的时候,他会自动帮我们建立这样的B+Tree数据结构,上图假如我们要查询30那条数据(select * from table where column = 30),这个column就是我们创建索引的那一列,这样他会把根节点加载到内存中,根据二分法或者其他方式查找到30对应的区间地址,因为在内存中的查找运算要比查询磁盘要快的多

然后相应的再往下找到30所在的区间位置,遍历最后一个叶子节点就可以获取到30那条数据
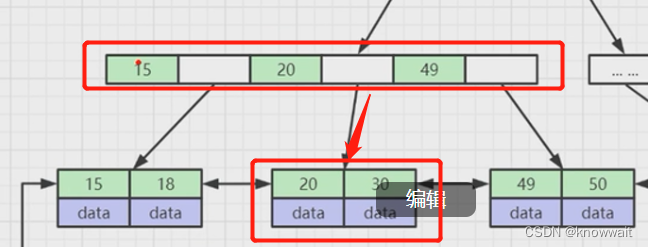
那如果数据量过大,百万千万,树还会不会变得很深?
我们说树的查询效率取决于树的深度,那这个在千万级数据量下会不会还有二叉树和红黑树一样的问题呢?
其实没有了,B+Tree是可以设置树的最大深度的,我们假设深度设置为3,看看能进行多少量级的数据查询。
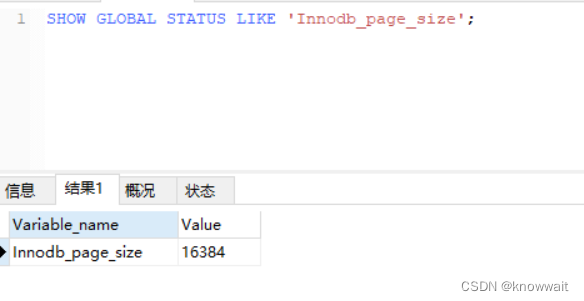
因为在前面的两层节点中只存储了索引数据和子节点的磁盘位置,大大节省了存储空间,每个节点的存储大小是由mysql设置的分页参数决定的:一般是16kb
ps:页是InnoDB访问的最小单位,默认16KB。缓冲池是以页为管理单位,每次读取或刷新一页数据。参数: innodb_page_size,可以将页大小设置为4K,8K.
SHOW GLOBAL STATUS LIKE "Innodb_page_size";
而一个索引数据假设我们用的bigInt占用8个字节,两个索引元素之间的空间是下个节点的磁盘空间地址,占用6个字节,也就是一个索引+节点地址占用14b,那么16kb的空间可以存储数据量是1170个索引,同理第二个层级的每个节点是也是可以存储1170个索引,最后一层也就是第三层的节点因为存储的是实际每一列的数据,假设每列数据占用1kb,那每个节点占存储16个索引数据。
整个树的数据存储量为1170*1170*16=21,902,400,是个两千万量级的数据量。完全满足大数据量的需求。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
相关文章:
 网公网安备
网公网安备