MySQL实战文章(非常全的基础入门类教程)
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一
介绍

什么是数据库
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。每个数据库都有一个或多个不同的 API 用于创建,访问,管理,搜索和复制所保存的数据。我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理大数据量。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
MySQL数据库
MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- MySQL 是开源的,目前隶属于 Oracle 旗下产品。
- MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL 使用标准的 SQL 数据语言形式。
- MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby 和 Tcl 等。
- MySQL 对PHP有很好的支持,PHP 是目前最流行的 Web 开发语言。
- MySQL 支持大型数据库,支持 5000 万条记录的数据仓库,32 位系统表文件最大可支持 4GB,64 位系统支持最大的表文件为8TB。
- MySQL 是可以定制的,采用了 GPL 协议,你可以修改源码来开发自己的 MySQL 系统。
RDBMS 术语
在我们开始学习MySQL 数据库前,让我们先了解下RDBMS的一些术语
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同类型的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
MySQL 为关系型数据库(Relational Database Management System), 这种所谓的关系型可以理解为表格的概念, 一个关系型数据库由一个或数个表格组成, 如图所示的一个表格
数据库表的存储位置
MySQL数据表以文件方式存放在磁盘中:
- 包括表文件、数据文件以及数据库的选项文件
- 位置:MySQL安装目录data下存放数据表。目录名对应数据库名,该目录下文件名对应数据表
注:
InnoDB类型数据表只有一个*. frm文件,以及上一级目录的ibdata1文件MylSAM类型数据表对应三个文件:
- *. frm —— 表结构定义文件
- *. MYD —— 数据文件
- *. MYI —— 索引文件
存储位置:因操作系统而异,可查my.ini
数据类型
MySQL提供的数据类型包括数值类型(整数类型和小数类型)、字符串类型、日期类型、复合类型(复合类型包括enum类型和set类型)以及二进制类型 。
一. 整数类型
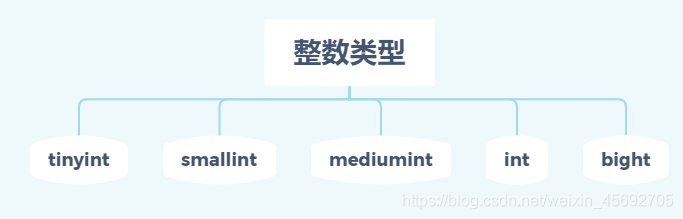
- 整数类型的数,默认情况下既可以表示正整数又可以表示负整数(此时称为有符号数)。如果只希望表示零和正整数,可以使用无符号关键字“unsigned”对整数类型进行修饰。
- 各个类别存储空间及取值范围。

二. 小数类型
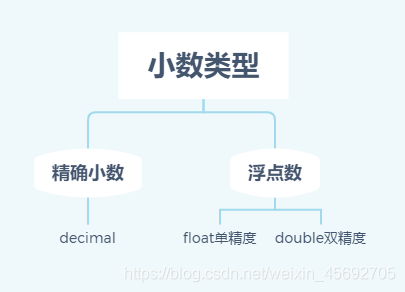
decimal(length, precision)用于表示精度确定(小数点后数字的位数确定)的小数类型,length决定了该小数的最大位数,precision用于设置精度(小数点后数字的位数)。
例如: decimal (5,2)表示小数取值范围:999.99~999.99 decimal (5,0)表示: -99999~99999的整数。
各个类别存储空间及取值范围。

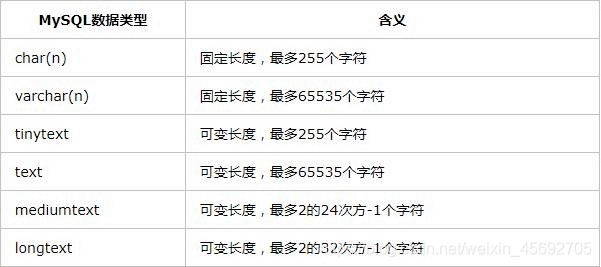
三. 字符串
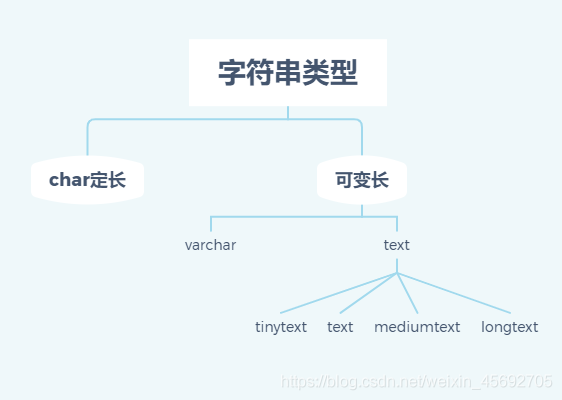
- char()与varchar(): 例如对于简体中文字符集gbk的字符串而言,varchar(255)表示可以存储255个汉字,而每个汉字占用两个字节的存储空间。假如这个字符串没有那么多汉字,例如仅仅包含一个‘中’字,那么varchar(255)仅仅占用1个字符(两个字节)的储存空间;而char(255)则必须占用255个字符长度的存储空间,哪怕里面只存储一个汉字。
- 各个类别存储空间及取值范围。
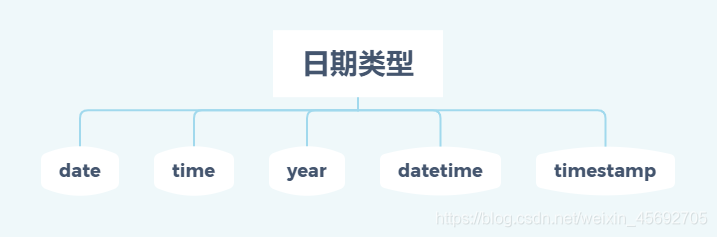
四. 日期类型
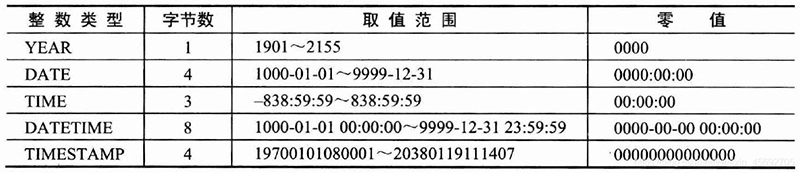
1、date表示日期,默认格式为‘YYYY-MM-DD’; time表示时间,格式为‘HH:ii:ss’; year表示年份; datetime与timestamp是日期和时间的混合类型,格式为’YYYY-MM-DD HH:ii:ss’。
2、datetime与timestamp都是日期和时间的混合类型,区别在于: 表示的取值范围不同,datetime的取值范围远远大于timestamp的取值范围。 将NULL插入timestamp字段后,该字段的值实际上是MySQL服务器当前的日期和时间。 同一个timestamp类型的日期或时间,不同的时区,显示结果不同。
3、各个类别存储空间及取值范围。
五. 复合类型
MySQL 支持两种复合数据类型:enum枚举类型和set集合类型。 enum类型的字段类似于单选按钮的功能,一个enum类型的数据最多可以包含65535个元素。 set 类型的字段类似于复选框的功能,一个set类型的数据最多可以包含64个元素。
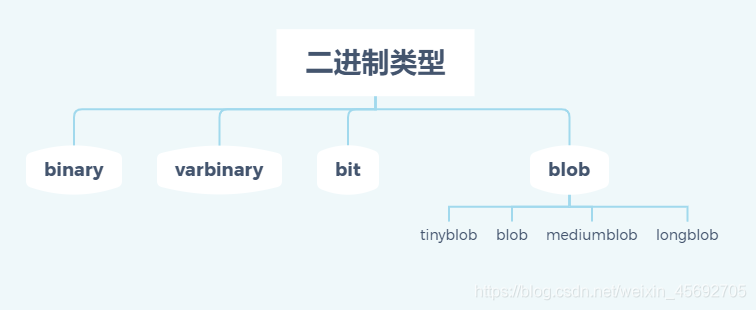
六. 二进制类型
二进制类型的字段主要用于存储由‘0’和‘1’组成的字符串,因此从某种意义上将,二进制类型的数据是一种特殊格式的字符串。二进制类型与字符串类型的区别在于:字符串类型的数据按字符为单位进行存储,因此存在多种字符集、多种字符序;而二进制类型的数据按字节为单位进行存储,仅存在二进制字符集binary。
约束
约束是一种限制,它通过对表的行或列的数据做出限制,来确保表的数据的完整性、唯一性。
下面文章就来给大家介绍一下6种mysql常见的约束,希望对大家有所帮助。
一. 非空约束(not null)
- 非空约束用于确保当前列的值不为空值,非空约束只能出现在表对象的列上。
- Null类型特征:所有的类型的值都可以是null,包括int、float 等数据类型
二. 唯一性约束(unique)
- 唯一约束是指定table的列或列组合不能重复,保证数据的唯一性。
- 唯一约束不允许出现重复的值,但是可以为多个null。
- 同一个表可以有多个唯一约束,多个列组合的约束。
- 在创建唯一约束时,如果不给唯一约束名称,就默认和列名相同。
- 唯一约束不仅可以在一个表内创建,而且可以同时多表创建组合唯一约束。
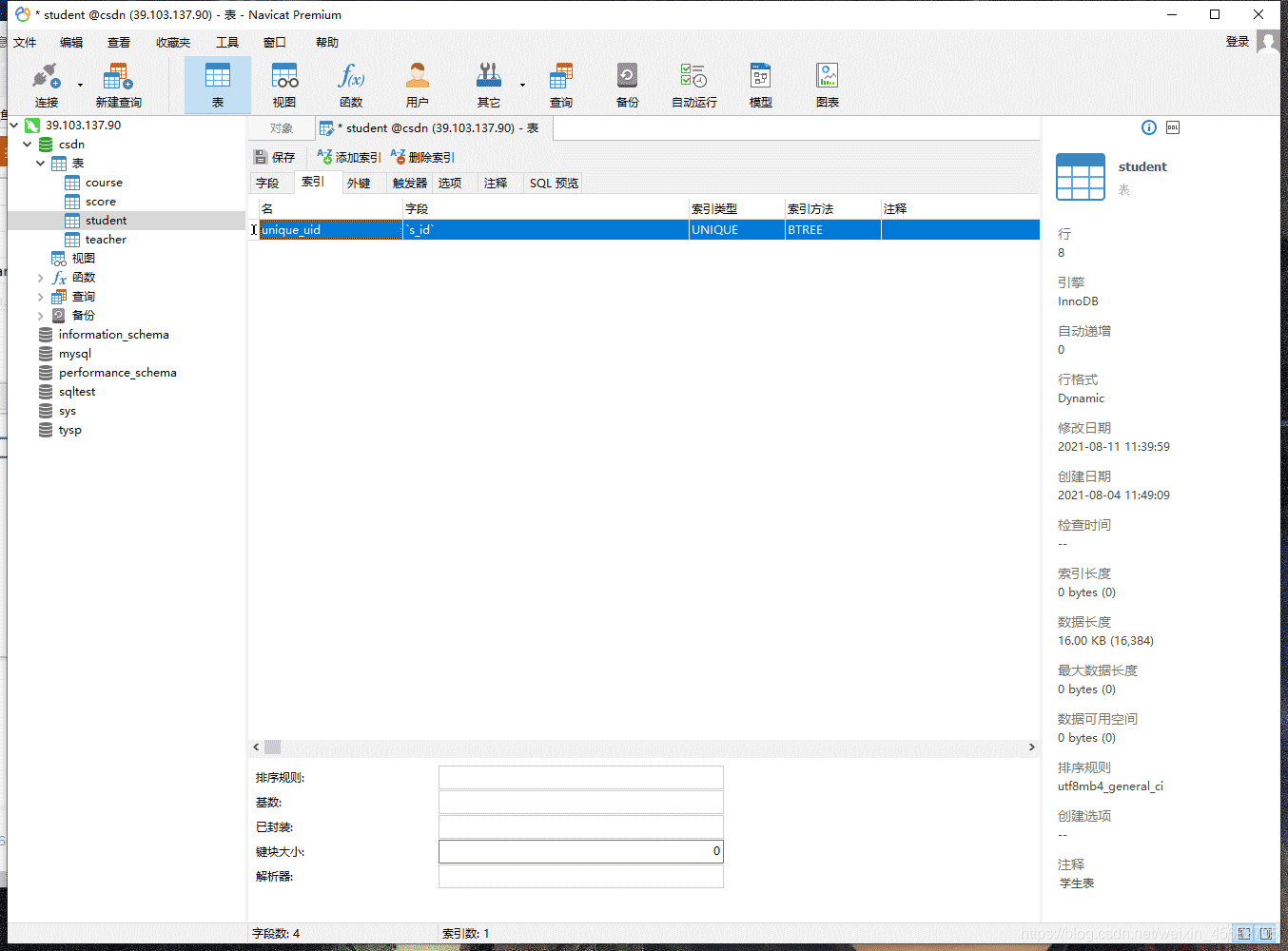
三. 主键约束(primary key) PK
主键约束相当于 唯一约束 + 非空约束 的组合,主键约束列不允许重复,也不允许出现空值。
每个表最多只允许一个主键,建立主键约束可以在列级别创建,也可以在表级别创建。
当创建主键的约束时,系统默认会在所在的列和列组合上建立对应的唯一索引。
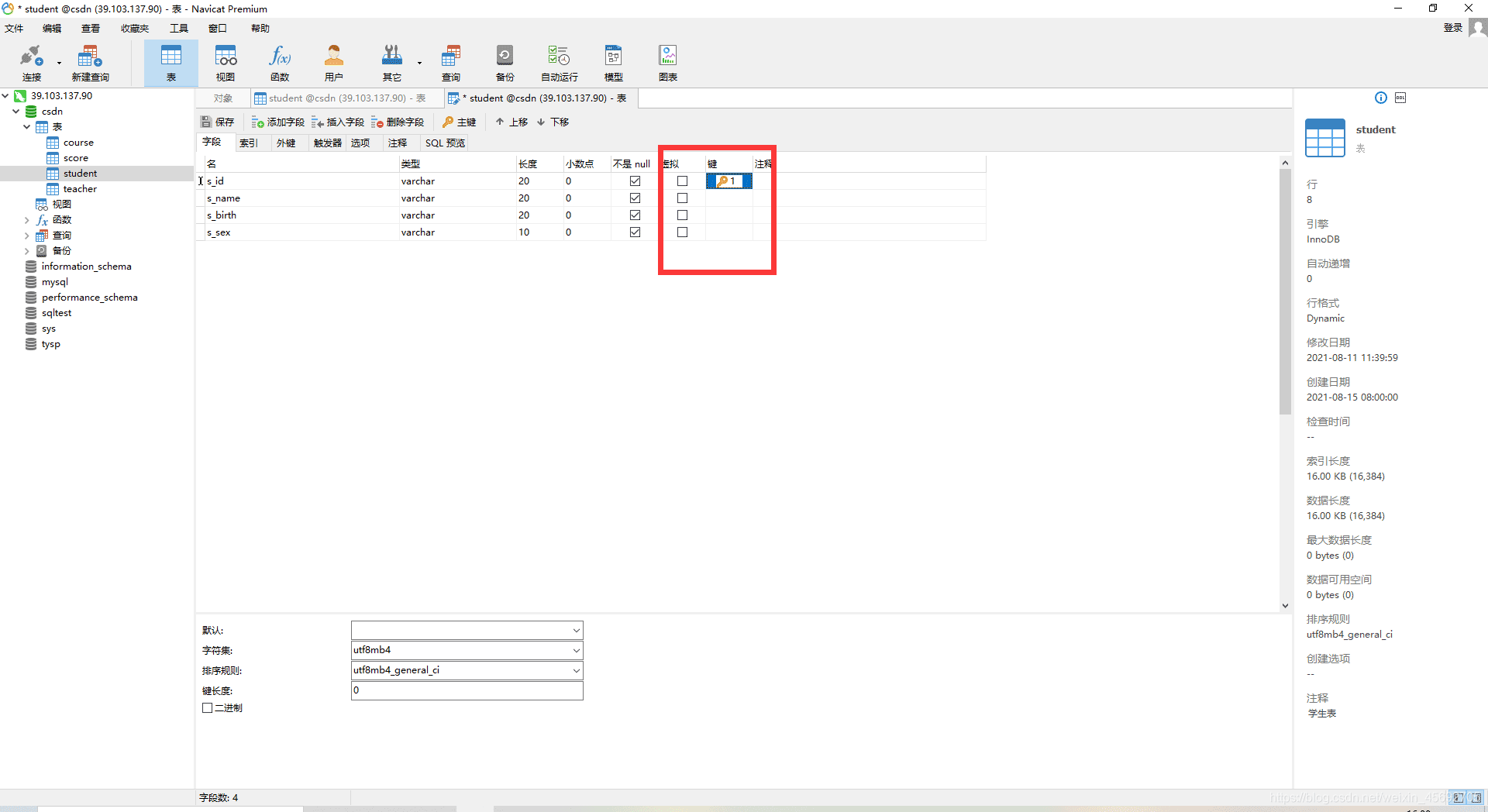
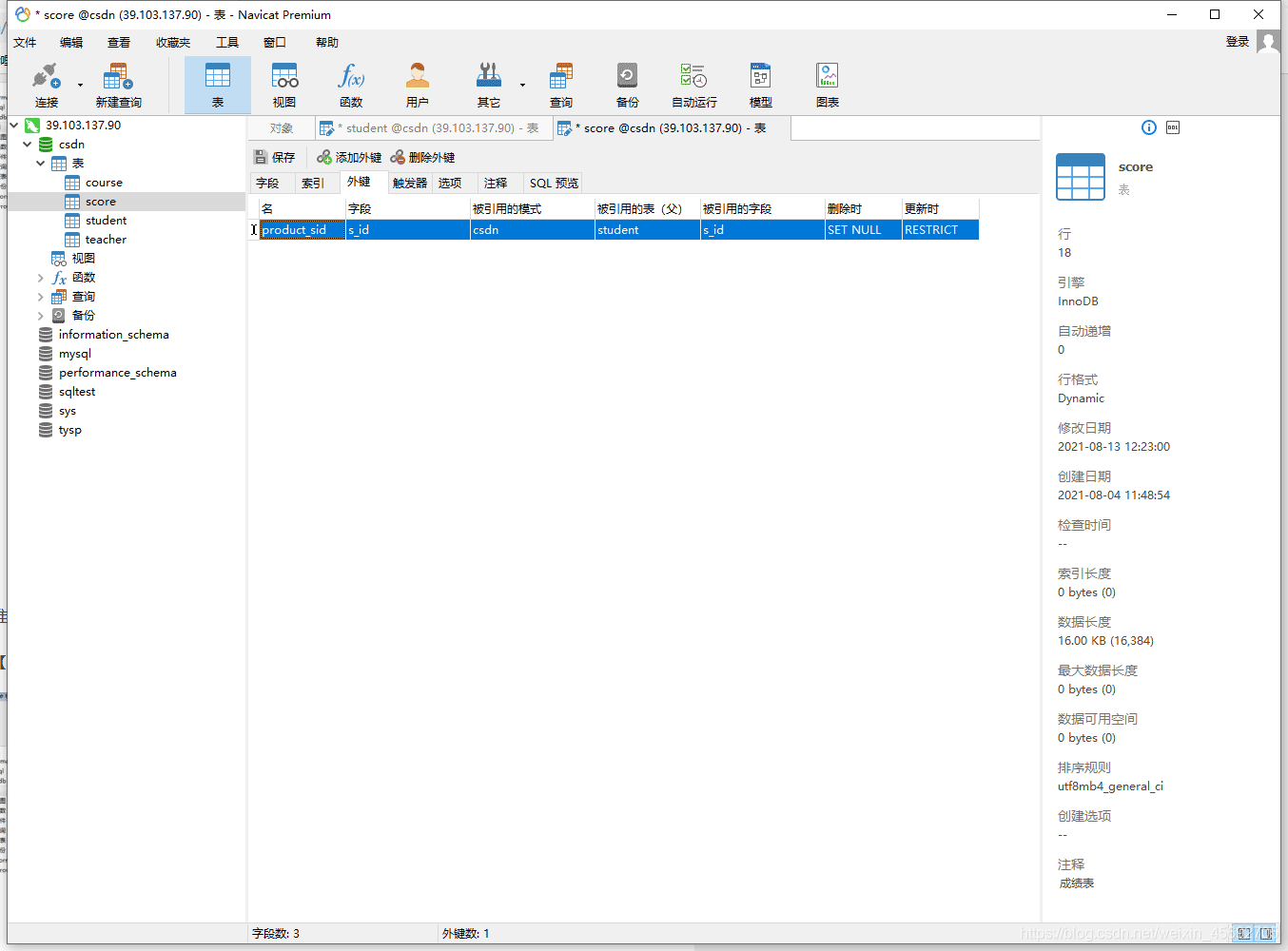
四. 外键约束(foreign key) FK
- 外键约束是用来加强两个表(主表和从表)的一列或多列数据之间的连接的,可以保证一个或两个表之间的参照完整性,外键是构建于一个表的两个字段或是两个表的两个字段之间的参照关系。
- 创建外键约束的顺序是先定义主表的主键,然后定义从表的外键。也就是说只有主表的主键才能被从表用来作为外键使用,被约束的从表中的列可以不是主键,主表限制了从表更新和插入的操作。
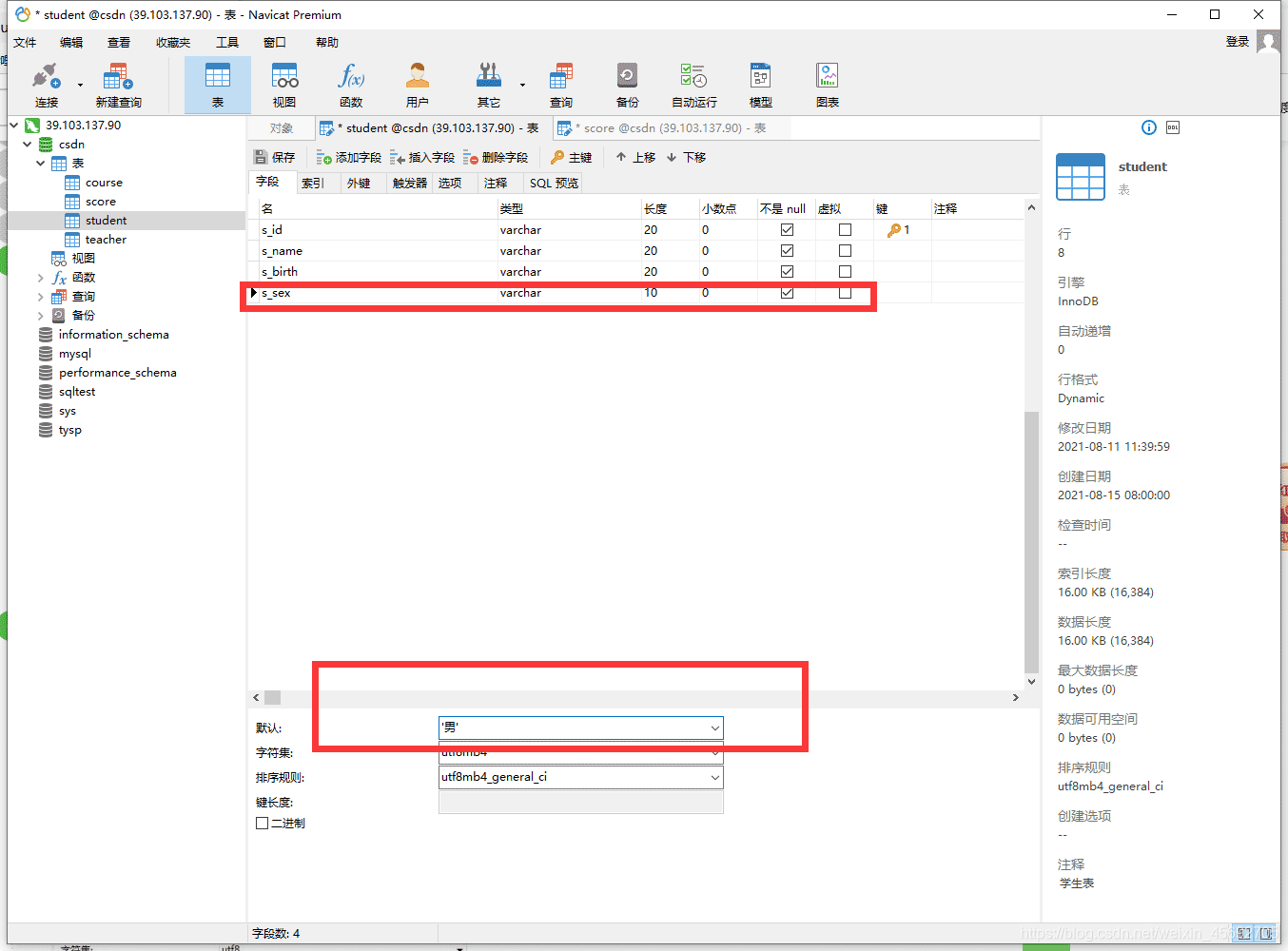
五. 默认值约束 (Default)
若在表中定义了默认值约束,用户在插入新的数据行时,如果该行没有指定数据,那么系统将默认值赋给该列,如果我们不设置默认值,系统默认为NULL。
六. 自增约束(AUTO_INCREMENT)
- 自增约束(AUTO_INCREMENT)可以约束任何一个字段,该字段不一定是PRIMARY KEY字段,也就是说自增的字段并不等于主键字段。
- 但是PRIMARY_KEY约束的主键字段,一定是自增字段,即PRIMARY_KEY 要与AUTO_INCREMENT一起作用于同一个字段。
当插入第一条记录时,自增字段没有给定一个具体值,可以写成DEFAULT/NULL,那么以后插入字段的时候,该自增字段就是从1开始,没插入一条记录,该自增字段的值增加1。当插入第一条记录时,给自增字段一个具体值,那么以后插入的记录在此自增字段上的值,就在第一条记录该自增字段的值的基础上每次增加1。也可以在插入记录的时候,不指定自增字段,而是指定其余字段进行插入记录的操作。
常用命令
登录数据库相关命令
一. 启动服务
语法:
mysql> net stop mysql
二. 关闭服务
语法:
mysql> net start mysql
三. 链接MySQL
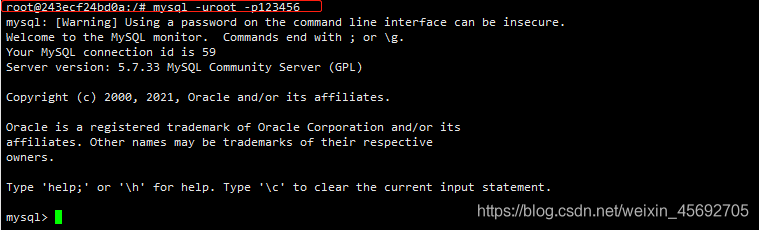
语法:mysql -u用户名 -p密码;
root@243ecf24bd0a:/ mysql -uroot -p123456;
在以上命令行中,mysql 代表客户端命令,-u 后面跟连接的数据库用户,-p 表示需要输入密码。如果数据库设置正常,并输入正确的密码,将看到上面一段欢迎界面和一个 mysql>提示符。
四. 退出数据库
语法:quit
mysql> quit
结果:

DDL(Data Definition Languages)
语句:即数据库定义语句
对于数据库而言实际上每一张表都表示是一个数据库的对象,而数据库对象指的就是DDL定义的所有操作,例如:表,视图,索引,序列,约束等等,都属于对象的操作,所以表的建立就是对象的建立,而对象的操作主要分为以下三类语法
- 创建对象:CREATE 对象名称;
- 删除对象:DROP 对象名称;
- 修改对象:ALTER 对象名称;

一. 创建数据库
语法:create database 数据库名字;
mysql> create database sqltest;
结果:

二. 查看已经存在的数据库
语法:show databases;
mysql> show databases;
结果:

- information_schema:主要存储了系统中的一些数据库对象信息。比如用户表信息、列信息、权限信息、字符集信息、分区信息等。
- cluster:存储了系统的集群信息。
- mysql:存储了系统的用户权限信息。
- test:系统自动创建的测试数据库,任何用户都可以使用。
三. 选择数据库
语法:use 数据库名;
mysql> use mzc-test;
返回Database changed代表我们已经选择 sqltest 数据库,后续所有操作将在 sqltest 数据库上执行。

有些人可能会问到,连接以后怎么退出。其实,不用退出来,use 数据库后,使用show databases就能查询所有数据库,如果想跳到其他数据库,用use 其他数据库名字。
四. 查看数据库中的表
语法:show tables;
mysql> show tables;
结果:

五. 删除数据库
语法:drop database 数据库名称;
mysql> drop database mzc-test;
结果:
注意:删除时,最好用 `` 符号把表明括起来
六. 设置表的类型
MySQL的数据表类型:MyISAM、InnoDB、HEAP、 BOB、CSV等

语法:
CREATE TABLE 表名( #省略代码)ENGINE= InnoDB;
适用场景:
1. 使用MyISAM:节约空间及响应速度快;不需事务,空间小,以查询访问为主
2. 使用InnoDB:安全性,事务处理及多用户操作数据表;多删除、更新操作,安全性高,事务处理及并发控制
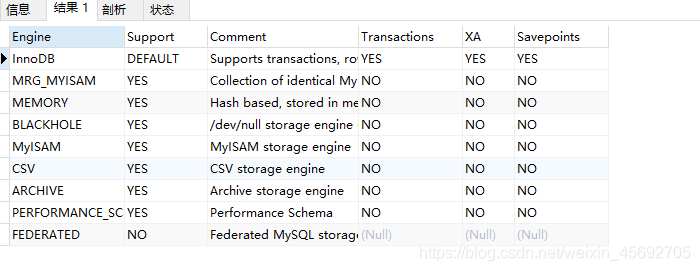
1. 查看mysql所支持的引擎类型
语法:
SHOW ENGINES
结果:
2. 查看默认引擎
语法:
SHOW VARIABLES LIKE "storage_engine";
结果:
数据库表相关操作
一. 创建表
语法:create table 表名 {列名,数据类型,约束条件};
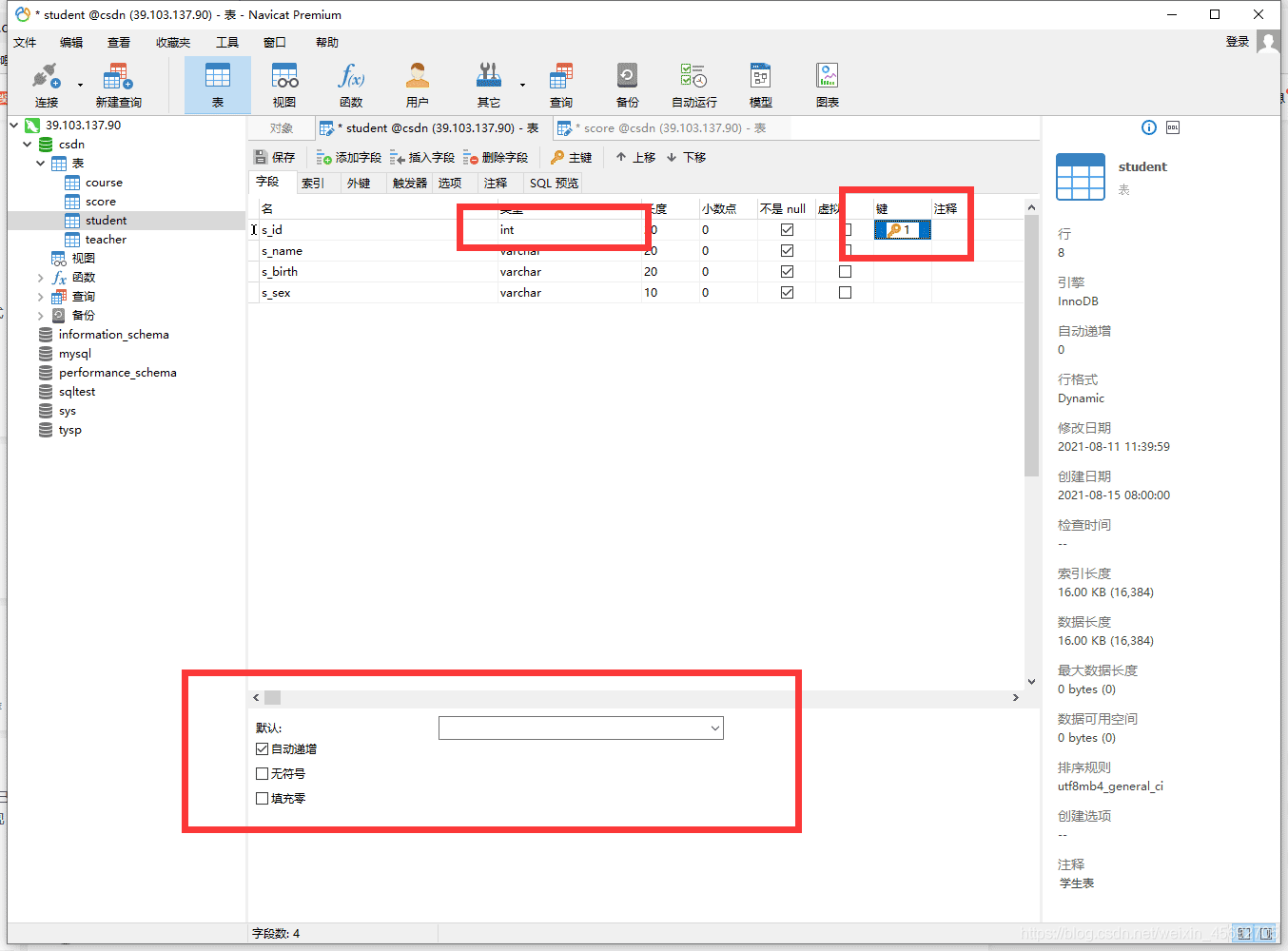
CREATE TABLE `Student`( `s_id` VARCHAR(20), `s_name` VARCHAR(20) NOT NULL DEFAULT "", `s_birth` VARCHAR(20) NOT NULL DEFAULT "", `s_sex` VARCHAR(10) NOT NULL DEFAULT "", PRIMARY KEY(`s_id`));
结果

注意:表名还请遵守数据库的命名规则,这条数据后面要进行删除,所以首字母为大写。
二. 查看表定义
语法:desc 表名
mysql> desc Student;
结果:
虽然 desc 命令可以查看表定义,但是其输出的信息还是不够全面,为了查看更全面的表定义信息,有时就需要通过查看创建表的 SQL 语句来得到,可以使用如下命令实现
语法:show create table 表名 G;
mysql> show create table Student G;
结果: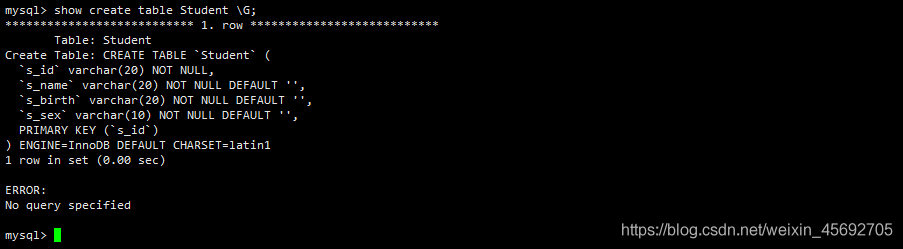
从上面表的创建 SQL 语句中,除了可以看到表定义以外,还可以看到表的engine(存储引擎)和charset(字符集)等信息。G选项的含义是使得记录能够按照字段竖着排列,对于内容比较长的记录更易于显示。
三. 删除表
语法:drop table 表名
mysql> drop table Student;
结果:

四. 修改表 (重要)
对于已经创建好的表,尤其是已经有大量数据的表,如果需要对表做一些结构上的改变,我们可以先将表删除(drop),然后再按照新的表定义重建表。这样做没有问题,但是必然要做一些额外的工作,比如数据的重新加载。而且,如果有服务在访问表,也会对服务产生影响。因此,在大多数情况下,表结构的更改一般都使用 alter table语句,以下是一些常用的命令。
1. 修改表类型
语法:ALTER TABLE 表名 MODIFY [COLUMN] column_definition [FIRST | AFTER col_name]
例如,修改表 student 的 s_name 字段定义,将 varchar(20)改为 varchar(30)
mysql> alter table Student modify s_name varchar(30);
结果: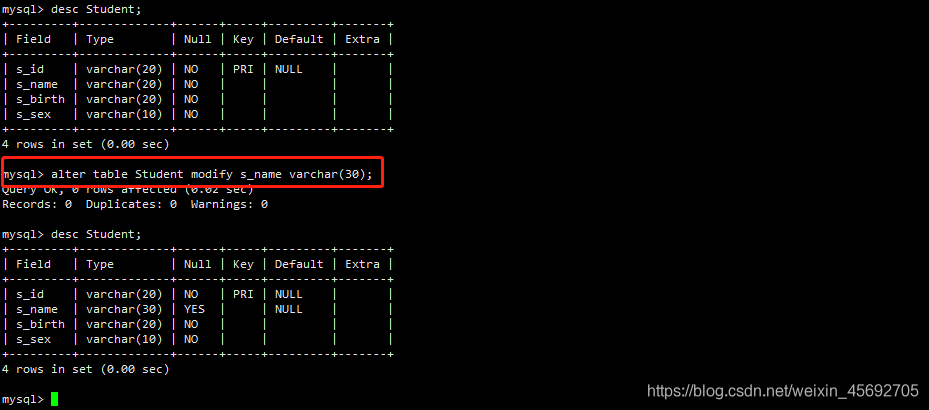
2. 增加表字段
语法:ALTER TABLE 表名 ADD [COLUMN] [FIRST | AFTER col_name];
例如,表 student 上新增加字段 s_test,类型为 int(3)
mysql> alter table student add column s_test int(3);
结果:
3. 删除表字段
语法:ALTER TABLE 表名 DROP [COLUMN] col_name
例如,将字段 s_test 删除掉
mysql> alter table Student drop column s_test;
结果:
4. 字段改名
语法:ALTER TABLE 表名 CHANGE [COLUMN] old_col_name column_definition [FIRST|AFTER col_name]
例如,将 s_sex 改名为 s_sex1,同时修改字段类型为 int(4)
mysql> alter table Student change s_sex s_sex1 int(4);
结果:
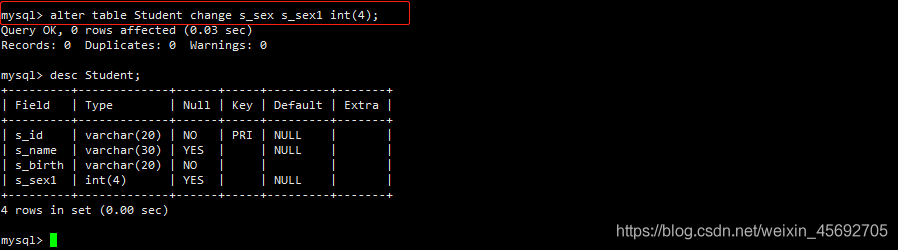
注意:change 和 modify 都可以修改表的定义,不同的是 change 后面需要写两次列名,不方便。但是 change 的优点是可以修改列名称,modify 则不能。
5. 修改字段排列顺序
前面介绍的的字段增加和修改语法(ADD/CNAHGE/MODIFY)中,都有一个可选项first|after column_name,这个选项可以用来修改字段在表中的位置,默认 ADD 增加的新字段是加在表的最后位置,而 CHANGE/MODIFY 默认都不会改变字段的位置。
例如,将新增的字段 s_test 加在 s_id 之后
语法:alter table 表名 add 列名 数据类型 after 列名;
mysql> alter table Student add s_test date after s_id;
结果:
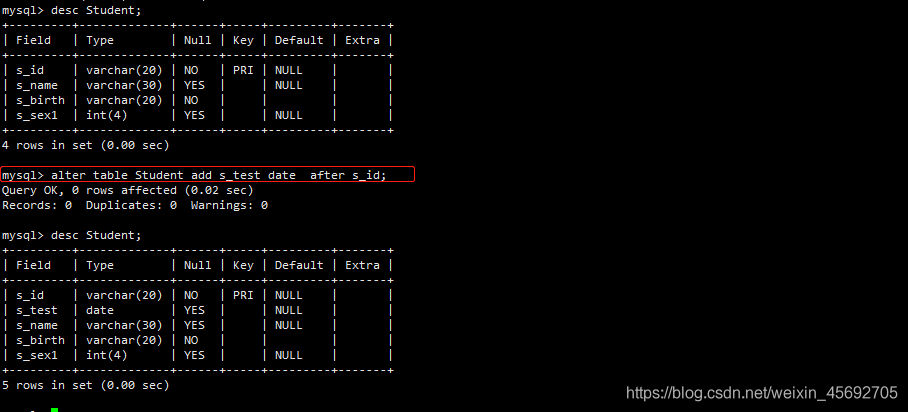
修改已有字段 s_name,将它放在最前面
mysql> alter table Student modify s_name varchar(30) default ‘’ first;
结果:
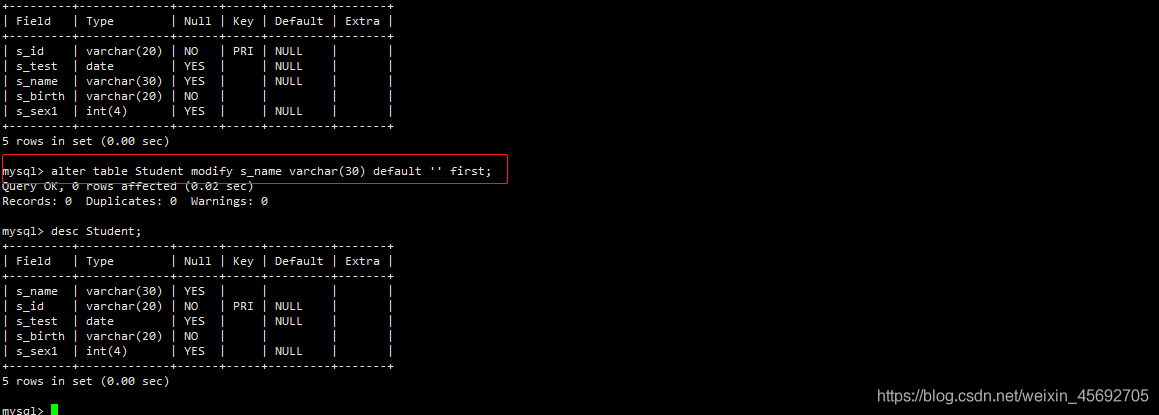
注意:CHANGE/FIRST|AFTER COLUMN 这些关键字都属于 MySQL 在标准 SQL 上的扩展,在其他数据库上不一定适用。
6.表名修改
语法:ALTER TABLE 表名 RENAME [TO] new_tablename
例如,将表 Student 改名为 student
mysql> alter table Student rename student;
结果: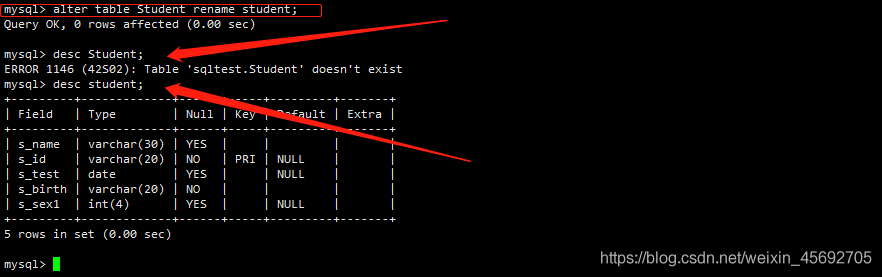
DML(Data Manipulation Language)
语句:即数据操纵语句 用于操作数据库对象中所包含的数据
一. 添加数据:INSERT
Insert 语句用于向数据库中插入数据
1. 插入单条数据(常用)
语法:insert into 表名(列名1,列名2,...) values(值1,值2,...)
特点:
插入值的类型要与列的类型一致或兼容。插入NULL可实现为列插入NULL值。列的顺序可以调换。列数和值的个数必须一致。可省略列名,默认所有列,并且列的顺序和表中列的顺序一致。
案例:
-- 插入学生表测试数据insert into Student(s_id,s_name,s_birth,s_sex) values("01" , "赵信" , "1990-01-01" , "男");
2. 插入单条数据
语法:INSERT INTO 表名 SET 列名 = 值,列名 = 值
这种方式每次只能插入一行数据,每列的值通过赋值列表制定。
案例:
INSERT INTO student SET s_id="02",s_name="德莱厄斯",s_birth="1990-01-01",s_sex="男"

3. 插入多条数据
语法:insert into 表名 values(值1,值2,值3),(值4,值5,值6),(值7,值8,值9);
案例:
INSERT INTO student VALUES("03","艾希","1990-01-01","女"),("04","德莱文","1990-08-06","男"),("05","俄洛依","1991-12-01","女");
上面的例子中,值1,值2,值3),(值4,值5,值6),(值7,值8,值9) 即为 Value List,其中每个括号内部的数据表示一行数据,这个例子中插入了三行数据。Insert 语句也可以只给部分列插入数据,这种情况下,需要在 Value List 之前加上 ColumnName List,
例如:
INSERT INTO student(s_name,s_sex) VALUES("艾希","女"),("德莱文","男");每行数据只指定了 s_name 和 s_sex 这两列的值,其他列的值会设为 Null。
4. 表数据复制
语法:INSERT INTO 表名 SELECT * from 表名;
案例:
INSERT INTO student SELECT * from student1;

注意:
两个表的字段需要一直,并尽量保证要新增的表中没有数据
二. 更新数据:UPDATE
Update 语句一共有两种语法,分别用于更新单表数据和多表数据。
注意:没有 WHERE 条件的 UPDATE 会更新所有值!
1. 修改一条数据的某个字段
语法:UPDATE 表名 SET 字段名 =值 where 字段名=值
案例:
UPDATE student SET s_name ="张三" WHERE s_id ="01"

2. 修改多个字段为同一的值
语法:UPDATE 表名 SET 字段名= 值 WHERE 字段名 in ('值1','值2','值3');
案例:
UPDATE student SET s_name = "李四" WHERE s_id in ("01","02","03");
3. 使用case when实现批量更新
语法:update 表名 set 字段名 = case 字段名 when 值1 then '值' when 值2 then '值' when 值3 then '值' end where s_id in (值1,值2,值3)
案例:
update student set s_name = case s_id when 01 then "小王" when 02 then "小周" when 03 then "老周" end where s_id in (01,02,03)

这句sql的意思是,更新 s_name 字段,如果 s_id 的值为 01 则 s_name 的值为 小王,s_id = 02 则 s_name = 小周,如果s_id =03 则 s_name 的值为 老周。这里的where部分不影响代码的执行,但是会提高sql执行的效率。确保sql语句仅执行需要修改的行数,这里只有3条数据进行更新,而where子句确保只有3行数据执行。
案例 2:
UPDATE student SET s_birth = CASE s_nameWHEN "小王" THEN"2019-01-20"WHEN "小周" THEN"2019-01-22"END WHERE s_name IN ("小王","小周");
三. 删除数据:DELETE
数据库一旦删除数据,它就会永远消失。 因此,在执行DELETE语句之前,应该先备份数据库,以防万一要找回删除过的数据。 1. 删除指定数据
语法:DELETE FROM 表名 WHERE 列名=值
注意:删除的时候如果不指定where条件,则保留数据表结构,删除全部数据行,有主外键关系的都删不了
案例:
DELETE FROM student WHERE s_id="09"

与 SELECT 语句不同的是,DELETE 语句中不能使用 GROUP BY、 HAVING 和 ORDER BY 三类子句,而只能使用WHERE 子句。
原因很简单, GROUP BY 和 HAVING 是从表中选取数据时用来改变抽取数据形式的, 而 ORDER BY 是用来指定取得结果显示顺序的。因此,在删除表中数据 时它们都起不到什么作用。`
2. 删除表中全部数据
语法:TRUNCATE 表名;
注意:全部删除,内存无痕迹,如果有自增会重新开始编号。
与 DELETE 不同的是,TRUNCATE 只能删除表中的全部数据,而不能通过 WHERE 子句指定条件来删除部分数据。也正是因为它不能具体地控制删除对象, 所以其处理速度比 DELETE 要快得多。实际上,DELETE 语句在 DML 语句中也 属于处理时间比较长的,因此需要删除全部数据行时,使用 TRUNCATE 可以缩短 执行时间。
案例:
TRUNCATE student1;

DQL(Data Query Language)
语句:即数据查询语句 查询数据库中的记录,关键字 SELECT,这块内容非常重要!
一. wherer 条件语句
语法:select 列名 from 表名 where 列名 =值
where的作用:
用于检索数据表中符合条件的记录搜索条件可由一个或多个逻辑表达式组成,结果一般为真或假
搜索条件的组成:
算数运算符
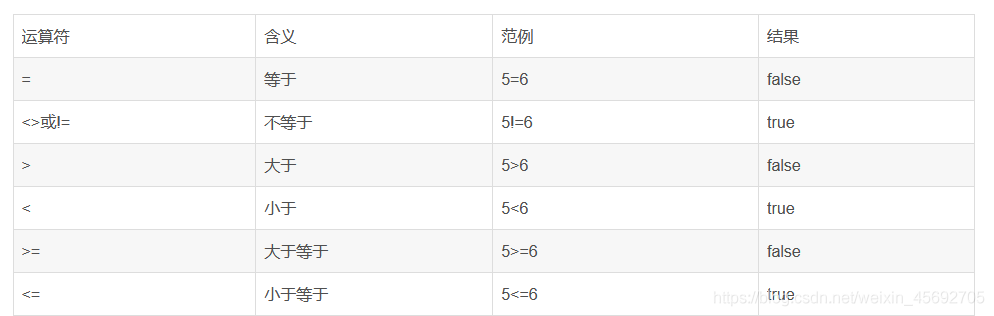
逻辑操作符(操作符有两种写法)

比较运算符
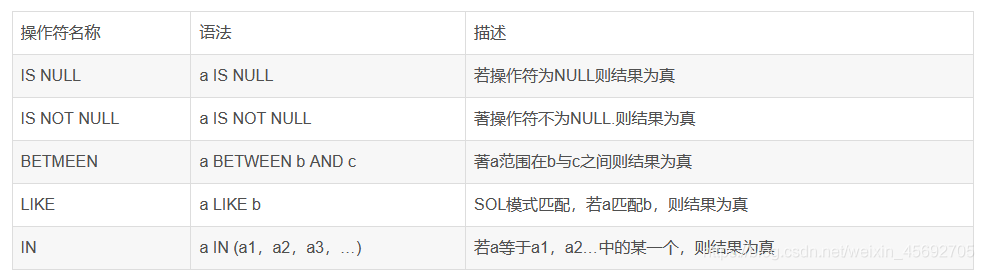
注意:数值数据类型的记录之间才能进行算术运算,相同数据类型的数据之间才能进行比较。
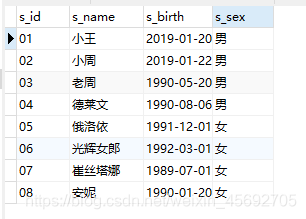
表数据
案例 1(AND):
SELECT * FROM student WHERE s_name ="小王" AND s_sex="男"

案例 2(OR):
SELECT * FROM student WHERE s_name ="崔丝塔娜" OR s_sex="男"
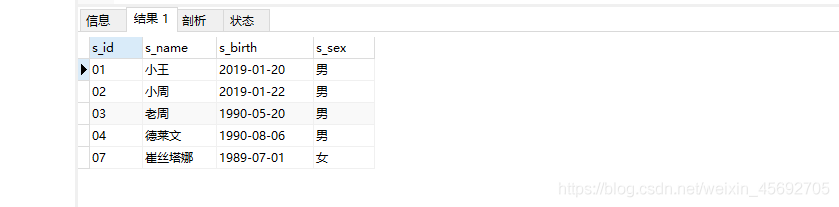
案例 3(NOT):
SELECT * FROM student WHERE NOT s_name ="崔丝塔娜"

案例 4(IS NULL):
SELECT * FROM student WHERE s_name IS NULL;

案例 5(IS NOT NULL):
SELECT * FROM student WHERE s_name IS NOT NULL;

案例 6(BETWEEN):
SELECT * FROM student WHERE s_birth BETWEEN "2019-01-20" AND "2019-01-22"

案例 7(LINK):
SELECT * FROM student WHERE s_name LIKE "小%"

案例 8(IN):
SELECT * FROM student WHERE s_name IN ("小王","小周")
二. as 取别名
表里的名字没有变,只影响了查询出来的结果
案例:
SELECT s_name as `name` FROM student

使用as也可以为表取别名 (作用:单表查询意义不大,但是当多个表的时候取别名就好操作,当不同的表里有相同名字的列的时候区分就会好区分)
三. distinct 去除重复记录
注意:当查询结果中所有字段全都相同时 才算重复的记录
案例
SELECT DISTINCT * FROM student

指定字段
星号表示所有字段
手动指定需要查询的字段
SELECT DISTINCT s_name,s_birth FROM student

还可也是四则运算聚合函数 四. group by 分组 group by的意思是根据by对数据按照哪个字段进行分组,或者是哪几个字段进行分组。
语法:
select 字段名 from 表名 group by 字段名称;
1. 单个字段分组
SELECT COUNT(*)FROM student GROUP BY s_sex;

2. 多个字段分组
SELECT s_name,s_sex,COUNT(*) FROM student GROUP BY s_name,s_sex;

注意:多个字段进行分组时,需要将s_name和s_sex看成一个整体,只要是s_name和s_sex相同的可以分成一组;如果只是s_sex相同,s_sex不同就不是一组。 五. having 过滤 HAVING 子句对 GROUP BY 子句设置条件的方式与 WHERE 和 SELECT 的交互方式类似。WHERE 搜索条件在进行分组操作之前应用;而 HAVING 搜索条件在进行分组操作之后应用。HAVING 语法与 WHERE 语法类似,但 HAVING 可以包含聚合函数。HAVING 子句可以引用选择列表中显示的任意项。
我们如果要查询男生或者女生,人数大于4的性别
SELECT s_sex as 性别,count(s_id) AS 人数 FROM student GROUP BY s_sex HAVING COUNT(s_id)>4

六. order by 排序
根据某个字段排序,默认升序(从小到大)
语法:
select * from 表名 order by 字段名;
1. 一个字段,降序(从大到小)
SELECT * FROM student ORDER BY s_id DESC;

2. 多个字段
SELECT * FROM student ORDER BY s_id DESC, s_birth ASC;

多个字段 第一个相同在按照第二个 asc 表示升序 limit 分页 用于限制要显示的记录数量
语法1:
select * from table_name limit 个数;
语法2:
select * from table_name limit 起始位置,个数;
案例:
查询前三条数据
SELECT * FROM student LIMIT 3;

从第三条开始 查询3条
SELECT * FROM student LIMIT 2,3;

注意:起始位置 从0开始
经典的使用场景:分页显示
每一页显示的条数 a = 3明确当前页数 b = 2计算起始位置 c = (b-1) * a 子查询
将一个查询语句的结果作为另一个查询语句的条件或是数据来源, 当我们一次性查不到想要数据时就需要使用子查询。
SELECT*FROMscoreWHEREs_id =(SELECTs_idFROMstudentWHEREs_name = ‘赵信")

1. in 关键字子查询 当内层查询 (括号内的) 结果会有多个结果时, 不能使用 = 必须是in ,另外子查询必须只能包含一列数据
子查询的思路:
要分析 查到最终的数据 到底有哪些步骤
根据步骤写出对应的sql语句
把上一个步骤的sql语句丢到下一个sql语句中作为条件
SELECT*FROMscoreWHEREs_id IN (SELECTs_idFROMstudentWHEREs_sex = ‘男")
exists 关键字子查询 当内层查询 有结果时 外层才会执行 多表查询 1. 笛卡尔积查询 笛卡尔积查询的结果会出现大量的错误数据即,数据关联关系错误,并且会产生重复的字段信息 ! 2. 内连接查询 本质上就是笛卡尔积查询,inner可以省略。
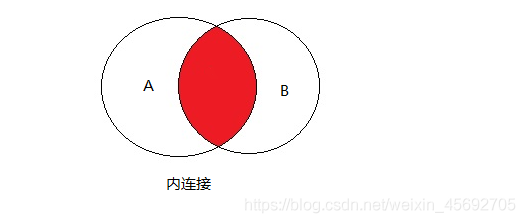
语法:
select * from 表1 inner join 表2;
3. 左外连接查询 左边的表无论是否能够匹配都要完整显示,右边的仅展示匹配上的记录
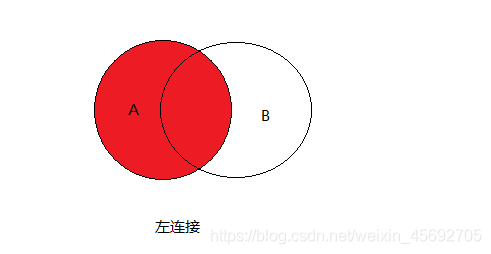
注意: 在外连接查询中不能使用where 关键字 必须使用on专门来做表的对应关系
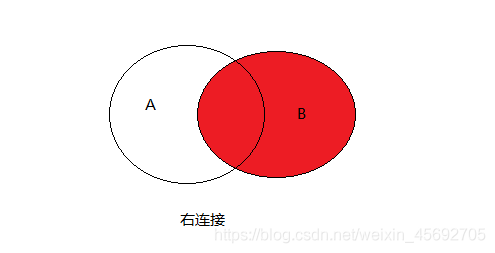
4. 右外连接查询 右边的表无论是否能够匹配都要完整显示,左边的仅展示匹配上的记录
DCL(Data Control Language)
语句:即数据控制语句 DCL(Data Control Language)语句:数据控制语句,用于控制不同数据段直接的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别。
关键字
- GRANT
- REVOKE
查看用户权限
当成功创建用户账户后,还不能执行任何操作,需要为该用户分配适当的访问权限。
可以使用SHOW GRANTS FOR语句来查询用户的权限。
例如:
mysql> SHOW GRANTS FOR test;+-------------------------------------------+| Grants for test@% |+-------------------------------------------+| GRANT ALL PRIVILEGES ON *.* TO "test"@"%" |+-------------------------------------------+1 row in set (0.00 sec)
GRANT语句 对于新建的MySQL用户,必须给它授权,可以用GRANT语句来实现对新建用户的授权。 格式语法
GRANT priv_type [(column_list)] [, priv_type [(column_list)]] ... ON [object_type] priv_level TO user [auth_option] [, user [auth_option]] ... [REQUIRE {NONE | tls_option [[AND] tls_option] ...}] [WITH {GRANT OPTION | resource_option} ...]GRANT PROXY ON user TO user [, user] ... [WITH GRANT OPTION]object_type: { TABLE | FUNCTION | PROCEDURE}priv_level: { * | *.* | db_name.* | db_name.tbl_name | tbl_name | db_name.routine_name}user: (see Section 6.2.4, “Specifying Account Names”)auth_option: { IDENTIFIED BY "auth_string" | IDENTIFIED WITH auth_plugin | IDENTIFIED WITH auth_plugin BY "auth_string" | IDENTIFIED WITH auth_plugin AS "auth_string" | IDENTIFIED BY PASSWORD "auth_string"}tls_option: { SSL | X509 | CIPHER "cipher" | ISSUER "issuer" | SUBJECT "subject"}resource_option: { | MAX_QUERIES_PER_HOUR count | MAX_UPDATES_PER_HOUR count | MAX_CONNECTIONS_PER_HOUR count | MAX_USER_CONNECTIONS count}权限类型(priv_type) 授权的权限类型一般可以分为数据库、表、列、用户。 授予数据库权限类型
授予数据库权限时,priv_type可以指定为以下值:
- SELECT:表示授予用户可以使用 SELECT 语句访问特定数据库中所有表和视图的权限。
- INSERT:表示授予用户可以使用 INSERT 语句向特定数据库中所有表添加数据行的权限。
- DELETE:表示授予用户可以使用 DELETE 语句删除特定数据库中所有表的数据行的权限。
- UPDATE:表示授予用户可以使用 UPDATE 语句更新特定数据库中所有数据表的值的权限。
- REFERENCES:表示授予用户可以创建指向特定的数据库中的表外键的权限。
- CREATE:表示授权用户可以使用 CREATE TABLE 语句在特定数据库中创建新表的权限。
- ALTER:表示授予用户可以使用 ALTER TABLE 语句修改特定数据库中所有数据表的权限。
- SHOW VIEW:表示授予用户可以查看特定数据库中已有视图的视图定义的权限。
- CREATE ROUTINE:表示授予用户可以为特定的数据库创建存储过程和存储函数的权限。
- ALTER ROUTINE:表示授予用户可以更新和删除数据库中已有的存储过程和存储函数的权限。
- INDEX:表示授予用户可以在特定数据库中的所有数据表上定义和删除索引的权限。
- DROP:表示授予用户可以删除特定数据库中所有表和视图的权限。
- CREATE TEMPORARY TABLES:表示授予用户可以在特定数据库中创建临时表的权限。
- CREATE VIEW:表示授予用户可以在特定数据库中创建新的视图的权限。
- EXECUTE ROUTINE:表示授予用户可以调用特定数据库的存储过程和存储函数的权限。
- LOCK TABLES:表示授予用户可以锁定特定数据库的已有数据表的权限。
- SHOW DATABASES:表示授权可以使用SHOW DATABASES语句查看所有已有的数据库的定义的权限。
- ALL或ALL PRIVILEGES:表示以上所有权限。
授予表权限时,priv_type可以指定为以下值:
- SELECT:授予用户可以使用 SELECT 语句进行访问特定表的权限。
- INSERT:授予用户可以使用 INSERT 语句向一个特定表中添加数据行的权限。
- DELETE:授予用户可以使用 DELETE 语句从一个特定表中删除数据行的权限。
- DROP:授予用户可以删除数据表的权限。
- UPDATE:授予用户可以使用 UPDATE 语句更新特定数据表的权限。
- ALTER:授予用户可以使用 ALTER TABLE 语句修改数据表的权限。
- REFERENCES:授予用户可以创建一个外键来参照特定数据表的权限。
- CREATE:授予用户可以使用特定的名字创建一个数据表的权限。
- INDEX:授予用户可以在表上定义索引的权限。
- ALL或ALL PRIVILEGES:所有的权限名
授予列(字段)权限类型
授予列(字段)权限时,priv_type的值只能指定为SELECT、INSERT和UPDATE,同时权限的后面需要加上列名列表(column-list)。
授予创建和删除用户的权限
授予列(字段)权限时,priv_type的值指定为CREATE USER权限,具备创建用户、删除用户、重命名用户和撤消所有特权,而且是全局的。
ON
有ON,是授予权限,无ON,是授予角色。如:
– 授予数据库db1的所有权限给指定账户
GRANT ALL ON db1.* TO ‘user1’@‘localhost’;
– 授予角色给指定的账户
GRANT ‘role1’, ‘role2’ TO ‘user1’@‘localhost’, ‘user2’@‘localhost’;
对象类型(object_type)
在ON关键字后给出要授予权限的object_type,通常object_type可以是数据库名、表名等。
权限级别(priv_level)
指定权限级别的值有以下几类格式:
- *:表示当前数据库中的所有表。
- .:表示所有数据库中的所有表。
- db_name.*:表示某个数据库中的所有表,db_name指定数据库名。
- db_name.tbl_name:表示某个数据库中的某个表或视图,db_name指定数据库名,tbl_name指定表名或视图名。
- tbl_name:表示某个表或视图,tbl_name指定表名或视图名。
- db_name.routine_name:表示某个数据库中的某个存储过程或函数,routine_name指定存储过程名或函数名。
被授权的用户(user)
"user_name"@"host_name"
Tips:'host_name’用于适应从任意主机访问数据库而设置的,可以指定某个地址或地址段访问。可以同时授权多个用户。
user表中host列的默认值
host
说明
%
匹配所有主机
localhost
localhost不会被解析成IP地址,直接通过UNIXsocket连接
127.0.0.1
会通过TCP/IP协议连接,并且只能在本机访问
::1
::1就是兼容支持ipv6的,表示同ipv4的127.0.0.1
host_name格式有以下几种:
- 使用%模糊匹配,符合匹配条件的主机可以访问该数据库实例,例如192.168.2.%或%.test.com;
- 使用localhost、127.0.0.1、::1及服务器名等,只能在本机访问;
- 使用ip地址或地址段形式,仅允许该ip或ip地址段的主机访问该数据库实例,例如192.168.2.1或192.168.2.0/24或192.168.2.0/255.255.255.0;
- 省略即默认为%。
身份验证方式(auth_option)
auth_option为可选字段,可以指定密码以及认证插件(mysql_native_password、sha256_password、caching_sha2_password)。
加密连接(tls_option)
tls_option为可选的,一般是用来加密连接。
用户资源限制(resource_option)
resource_option为可选的,一般是用来指定最大连接数等。
参数
说明
MAX_QUERIES_PER_HOUR count
每小时最大查询数
MAX_UPDATES_PER_HOUR count
每小时最大更新数
MAX_CONNECTIONS_PER_HOUR count
每小时连接次数
MAX_USER_CONNECTIONS count
用户最大连接数
权限生效
若要权限生效,需要执行以下语句:
FLUSH PRIVILEGES;
REVOKE语句
REVOKE语句主要用于撤销权限。
语法格式
REVOKE语法和GRANT语句的语法格式相似,但具有相反的效果
REVOKE
priv_type [(column_list)]
[, priv_type [(column_list)]] …
ON [object_type] priv_level
FROM user [, user] …
REVOKE ALL [PRIVILEGES], GRANT OPTION
FROM user [, user] …
REVOKE PROXY ON user
FROM user [, user] …
- 若要使用REVOKE语句,必须拥有MySQL数据库的全局CREATE USER权限或UPDATE权限;
- 第一种语法格式用于回收指定用户的某些特定的权限,第二种回收指定用户的所有权限;
TCL(Transaction Control Language)
语句:事务控制语句
什么是事物?
一个或一组sql语句组成一个执行单元,这个执行单元要么全部执行,要么全部不执行
事务的ACID属性
原子性:事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生
一致性:事务必须使数据库从一个一致性状态变换到另外一个一致性状态
隔离性:一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰
持久性:一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响
分类
隐式事务:事务没有明显的开启和结束的标记(比如insert,update,delete语句)
显式事务:事务具有明显的开启和结束的标记(autocommit变量设置为0)
事务的使用步骤
开启事务
默认开启事务
SET autocommit = 0 ;
提交事务
COMMIT;
回滚事务
ROLLBACK ;
查看当前的事务隔离级别
select @@tx_isolation;
设置当前连接事务的隔离级别
set session transaction isolation level read uncommitted;
设置数据库系统的全局的隔离级别
set global transaction isolation level read committed ;
常用函数
MySQL提供了众多功能强大、方便易用的函数,使用这些函数,可以极大地提高用户对于数据库的管理效率,从而更加灵活地满足不同用户的需求。本文将MySQL的函数分类并汇总,以便以后用到的时候可以随时查看。
(这里使用 Navicat Premium 15 工具进行演示)
因为内容太多了这里只演示一些常用的
一. 数学函数
对数值型的数据进行指定的数学运算,如abs()函数可以获得给定数值的绝对值,round()函数可以对给定的数值进行四舍五入。
1. ABS(number)
作用:返回 number 的绝对值
SELECT
ABS(s_score)
FROM
score;
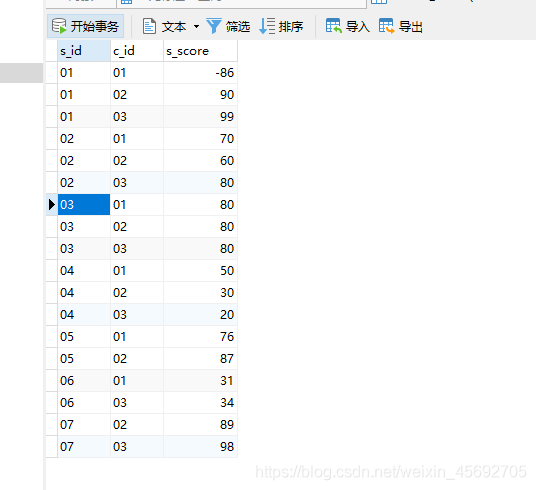
ABS(-86) 返回:86
number 参数可以是任意有效的数值表达式。如果 number 包含 Null,则返回 Null;如果是未初始化变量,则返回 0。
2. PI()
例1:pi() 返回:3.141592653589793
例2:pi(2) 返回:6.283185307179586
作用:计算圆周率及其倍数
3. SQRT(x) 作用:返回非负数的x的二次方根 4. MOD(x,y) 作用:返回x被y除后的余数 5. CEIL(x)、CEILING(x) 作用:返回不小于x的最小整数 6. FLOOR(x) 作用:返回不大于x的最大整数 7. FLOOR(x) 作用:返回不大于x的最大整数 8. ROUND(x)、ROUND(x,y)
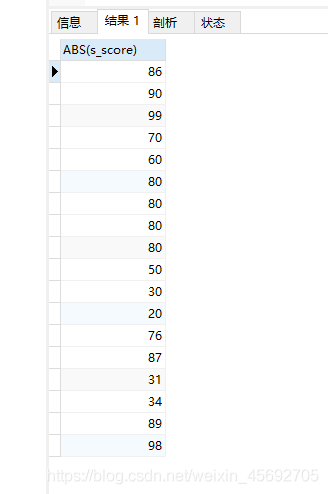
作用:前者返回最接近于x的整数,即对x进行四舍五入;后者返回最接近x的数,其值保留到小数点后面y位,若y为负值,则将保留到x到小数点左边y位
SELECT ROUND(345222.9)
参数说明: numberExp 需要进行截取的数据 nExp 整数,用于指定需要进行截取的位置,>0:从小数点往右位移nExp个位数, <0:从小数点往左
nExp个位数 =0:表示当前小数点的位置
9. POW(x,y)和、POWER(x,y) 作用:返回x的y次乘方的值 10. EXP(x) 作用:返回e的x乘方后的值 11. LOG(x) 作用:返回x的自然对数,x相对于基数e的对数 12. LOG10(x) 作用:返回x的基数为10的对数 13. RADIANS(x) 作用:返回x由角度转化为弧度的值 14. DEGREES(x) 作用:返回x由弧度转化为角度的值 15. SIN(x)、ASIN(x) 作用:前者返回x的正弦,其中x为给定的弧度值;后者返回x的反正弦值,x为正弦 16. COS(x)、ACOS(x) 作用:前者返回x的余弦,其中x为给定的弧度值;后者返回x的反余弦值,x为余弦 17. TAN(x)、ATAN(x) 作用:前者返回x的正切,其中x为给定的弧度值;后者返回x的反正切值,x为正切 18. COT(x) 作用:返回给定弧度值x的余切
二. 字符串函数
1. CHAR_LENGTH(str)
作用:计算字符串字符个数
SELECT CHAR_LENGTH(‘这是一个十二个字的字符串’);

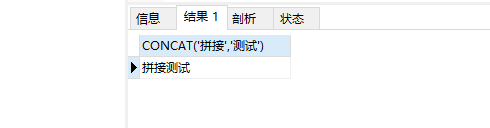
2. CONCAT(s1,s2,…)
作用:返回连接参数产生的字符串,一个或多个待拼接的内容,任意一个为NULL则返回值为NULL
SELECT CONCAT(‘拼接’,‘测试’);
3. CONCAT_WS(x,s1,s2,…)
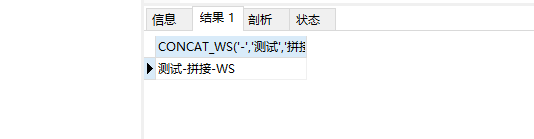
作用:返回多个字符串拼接之后的字符串,每个字符串之间有一个x
SELECT CONCAT_WS(‘-’,‘测试’,‘拼接’,‘WS’)
4. INSERT(s1,x,len,s2)
作用:返回字符串s1,其子字符串起始于位置x,被字符串s2取代len个字符
SELECT INSERT(‘测试字符串替换’,2,1,‘牛’);

5. LOWER(str)和LCASE(str)、UPPER(str)和UCASE(str)
作用:前两者将str中的字母全部转换成小写,后两者将字符串中的字母全部转换成大写
SELECT LOWER(‘JHGYTUGHJGG’),LCASE(‘HKJHKJHKJHKJ’);

SELECT UPPER("aaaaaa"),UCASE("vvvvv");
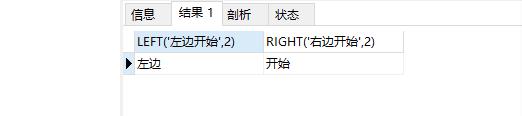
6. LEFT(s,n)、RIGHT(s,n)
作用:前者返回字符串s从最左边开始的n个字符,后者返回字符串s从最右边开始的n个字符
SELECT LEFT(‘左边开始’,2),RIGHT(‘右边开始’,2);

7. LPAD(s1,len,s2)、RPAD(s1,len,s2)
作用:前者返回s1,其左边由字符串s2填补到len字符长度,假如s1的长度大于len,则返回值被缩短至len字符;前者返回s1,其右边由字符串s2填补到len字符长度,假如s1的长度大于len,则返回值被缩短至len字符
SELECT LEFT(‘左边开始’,2),RIGHT(‘右边开始’,2);
8. LTRIM(s)、RTRIM(s)
作用:前者返回字符串s,其左边所有空格被删除;后者返回字符串s,其右边所有空格被删除
SELECT LTRIM(’ 左边开始’),RTRIM(’ 右边开始 ');

9. TRIM(s)
作用:返回字符串s删除了两边空格之后的字符串
SELECT TRIM(’ 是是 ');

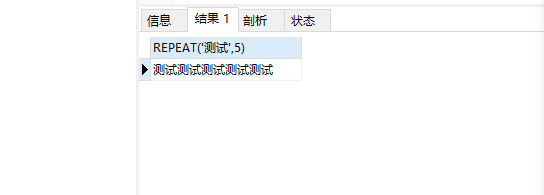
10. TRIM(s1 FROM s) 作用:删除字符串s两端所有子字符串s1,未指定s1的情况下则默认删除空格 11. REPEAT(s,n)
作用:返回一个由重复字符串s组成的字符串,字符串s的数目等于n
SELECT REPEAT(‘测试’,5);
12. SPACE(n)
作用:返回一个由n个空格组成的字符串
SELECT SPACE(20);

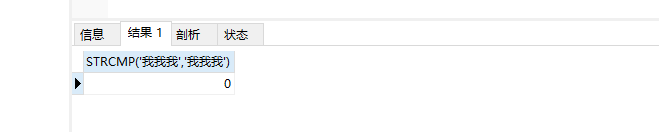
13. REPLACE(s,s1,s2) 作用:返回一个字符串,用字符串s2替代字符串s中所有的字符串s1 14. STRCMP(s1,s2)
作用:若s1和s2中所有的字符串都相同,则返回0;根据当前分类次序,第一个参数小于第二个则返回-1,其他情况返回1
SELECT STRCMP(‘我我我’,‘我我我’);
SELECT STRCMP("我我我","是是是");
15. SUBSTRING(s,n,len)、MID(s,n,len)
作用:两个函数作用相同,从字符串s中返回一个第n个字符开始、长度为len的字符串
SELECT SUBSTRING(‘测试测试’,2,2);

SELECT MID("测试测试",2,2);
16. LOCATE(str1,str)、POSITION(str1 IN str)、INSTR(str,str1)
作用:三个函数作用相同,返回子字符串str1在字符串str中的开始位置(从第几个字符开始)
SELECT LOCATE(‘字’,‘获取字符串的位置’);

17. REVERSE(s)
作用:将字符串s反转
SELECT REVERSE(‘字符串反转’);

18. ELT(N,str1,str2,str3,str4,…)
作用:返回第N个字符串
SELECT ELT(2,‘字符串反转’,‘sssss’);

三. 日期和时间函数
当前时间
1. CURDATE()、CURRENT_DATE() 作用:将当前日期按照"YYYY-MM-DD"或者"YYYYMMDD"格式的值返回,具体格式根据函数用在字符串或是数字语境中而定 2. CURRENT_TIMESTAMP()、LOCALTIME()、NOW()、SYSDATE()
作用:这四个函数作用相同,返回当前日期和时间值,格式为"YYYY_MM-DD HH:MM:SS"或"YYYYMMDDHHMMSS",具体格式根据函数用在字符串或数字语境中而定
SELECT CURRENT_TIMESTAMP()

SELECT LOCALTIME()

SELECT NOW()

SELECT SYSDATE()

3. UNIX_TIMESTAMP()、UNIX_TIMESTAMP(date)
作用:前者返回一个格林尼治标准时间1970-01-01 00:00:00到现在的秒数,后者返回一个格林尼治标准时间1970-01-01 00:00:00到指定时间的秒数
SELECT UNIX_TIMESTAMP()

4. FROM_UNIXTIME(date)
作用:和UNIX_TIMESTAMP互为反函数,把UNIX时间戳转换为普通格式的时间 5. UTC_DATE()和UTC_TIME()
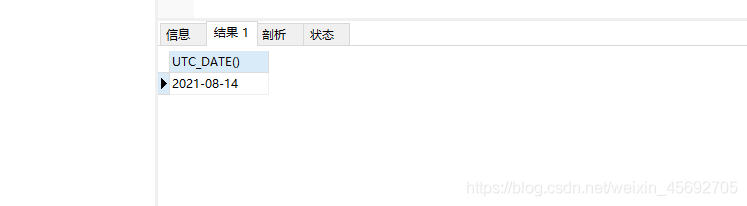
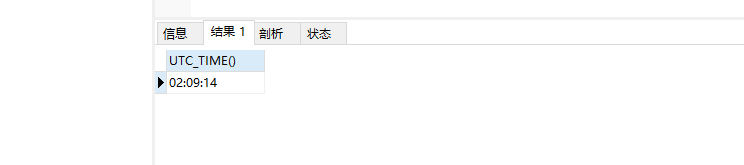
前者返回当前UTC(世界标准时间)日期值,其格式为"YYYY-MM-DD"或"YYYYMMDD",后者返回当前UTC时间值,其格式为"YYYY-MM-DD"或"YYYYMMDD"。具体使用哪种取决于函数用在字符串还是数字语境中
SELECT UTC_DATE()
SELECT UTC_TIME()
6. MONTH(date)和MONTHNAME(date)
作用:前者返回指定日期中的月份,后者返回指定日期中的月份的名称
SELECT MONTH(NOW())

SELECT MONTHNAME(NOW())

7. DAYNAME(d)、DAYOFWEEK(d)、WEEKDAY(d)
作用:DAYNAME(d)返回d对应的工作日的英文名称,如Sunday、Monday等;DAYOFWEEK(d)返回的对应一周中的索引,1表示周日、2表示周一;WEEKDAY(d)表示d对应的工作日索引,0表示周一,1表示周二 8. WEEK(d)
计算日期d是一年中的第几周
SELECT WEEK(NOW())

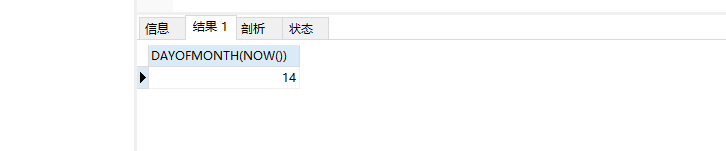
9. DAYOFYEAR(d)、DAYOFMONTH(d)
作用:前者返回d是一年中的第几天,后者返回d是一月中的第几天
SELECT DAYOFYEAR(NOW())

SELECT DAYOFMONTH(NOW())
10. YEAR(date)、QUARTER(date)、MINUTE(time)、SECOND(time)
作用: YEAR(date)返回指定日期对应的年份,范围是1970~2069;QUARTER(date)返回date对应一年中的季度,范围是1~4;MINUTE(time)返回time对应的分钟数,范围是0~59;SECOND(time)返回制定时间的秒值
SELECT YEAR(NOW())

SELECT QUARTER(NOW())

SELECT MINUTE(NOW())
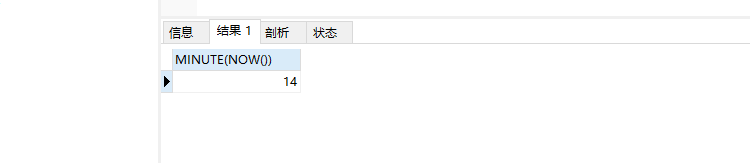
SELECT SECOND(NOW())

11. EXTRACE(type FROM date)
作用:从日期中提取一部分,type可以是YEAR、YEAR_MONTH、DAY_HOUR、DAY_MICROSECOND、DAY_MINUTE、DAY_SECOND 12. TIME_TO_SEC(time)
作用:返回以转换为秒的time参数,转换公式为"3600_小时 + 60_分钟 + 秒"
SELECT TIME_TO_SEC(NOW())

13. SEC_TO_TIME()
作用:和TIME_TO_SEC(time)互为反函数,将秒值转换为时间格式
SELECT SEC_TO_TIME(530)

14. DATE_ADD(date,INTERVAL expr type)、ADD_DATE(date,INTERVAL expr type)
作用:返回将起始时间加上expr type之后的时间,比如DATE_ADD(‘2010-12-31 23:59:59’, INTERVAL 1 SECOND)表示的就是把第一个时间加1秒
15. DATE_SUB(date,INTERVAL expr type)、SUBDATE(date,INTERVAL expr type)
作用:返回将起始时间减去expr type之后的时间
16. ADDTIME(date,expr)、SUBTIME(date,expr)
作用:前者进行date的时间加操作,后者进行date的时间减操作
四. 条件判断函数
1. IF(expr,v1,v2)
作用:如果expr是TRUE则返回v1,否则返回v2
2. IFNULL(v1,v2)
作用:如果v1不为NULL,则返回v1,否则返回v2
3. CASE expr WHEN v1 THEN r1 [WHEN v2 THEN v2] [ELSE rn] END
作用:如果expr等于某个vn,则返回对应位置THEN后面的结果,如果与所有值都不想等,则返回ELSE后面的rn
五. 系统信息函数
1. VERSION()
作用:查看MySQL版本号
SELECT VERSION()

2. CONNECTION_ID()
作用:查看当前用户的连接数
SELECT CONNECTION_ID()

3. USER()、CURRENT_USER()、SYSTEM_USER()、SESSION_USER()
作用:查看当前被MySQL服务器验证的用户名和主机的组合,一般这几个函数的返回值是相同的
SELECT USER()

SELECT CURRENT_USER()

SELECT SYSTEM_USER()

SELECT SESSION_USER()

4. CHARSET(str)
作用:查看字符串str使用的字符集
SELECT CHARSET(555)

5. COLLATION()
作用:查看字符串排列方式
SELECT COLLATION(‘sssfddsfds")

六. 加密函数
1. PASSWORD(str)
作用:从原明文密码str计算并返回加密后的字符串密码,注意这个函数的加密是单向的(不可逆),因此不应将它应用在个人的应用程序中而应该只在MySQL服务器的鉴定系统中使用
SELECT PASSWORD(‘mima’)

2. MD5(str)
作用:为字符串算出一个MD5 128比特校验和,改值以32位十六进制数字的二进制字符串形式返回
SELECT MD5(‘mima’)

3. ENCODE(str, pswd_str)
作用:使用pswd_str作为密码,加密str
SELECT ENCODE(‘fdfdz’,‘mima’)

4. DECODE(crypt_str,pswd_str)
作用:使用pswd_str作为密码,解密加密字符串crypt_str,crypt_str是由ENCODE函数返回的字符串
SELECT DECODE(‘fdfdz’,‘mima’)

七. 其他函数
1. FORMAT(x,n)
作用:将数字x格式化,并以四舍五入的方式保留小数点后n位,结果以字符串形式返回
SELECT FORMAT(446.454,2)

2. CONV(N,from_base,to_base)
作用:不同进制数之间的转换,返回值为数值N的字符串表示,由from_base进制转换为to_base进制
3. INET_ATON(expr)
作用:给出一个作为字符串的网络地址的点地址表示,返回一个代表该地址数值的整数,地址可以使4或8比特
4. INET_NTOA(expr)
作用:给定一个数字网络地址(4或8比特),返回作为字符串的该地址的点地址表示
5. BENCHMARK(count,expr)
作用:重复执行count次表达式expr,它可以用于计算MySQL处理表达式的速度,结果值通常是0(0只是表示很快,并不是没有速度)。另一个作用是用它在MySQL客户端内部报告语句执行的时间
6. CONVERT(str USING charset)
作用:使用字符集charset表示字符串str
更多用法还请参考:http://www.geezn.com/documents/gez/help/117555-1355219868404378.html
SQL实战练习
题目来自互联网,建议每道题都在本地敲一遍巩固记忆 ! 创建数据库
创建表(并初始化数据)
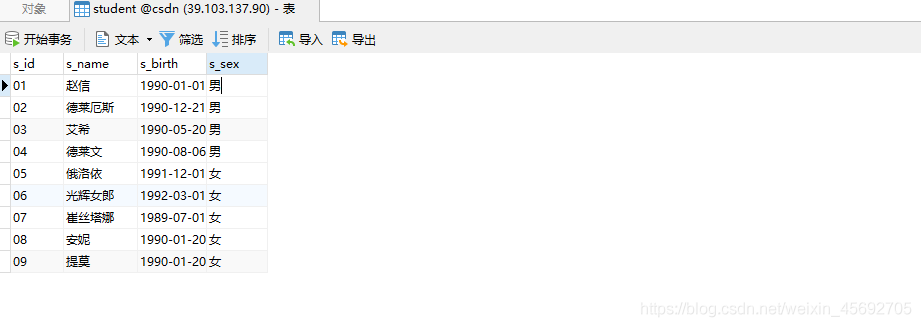
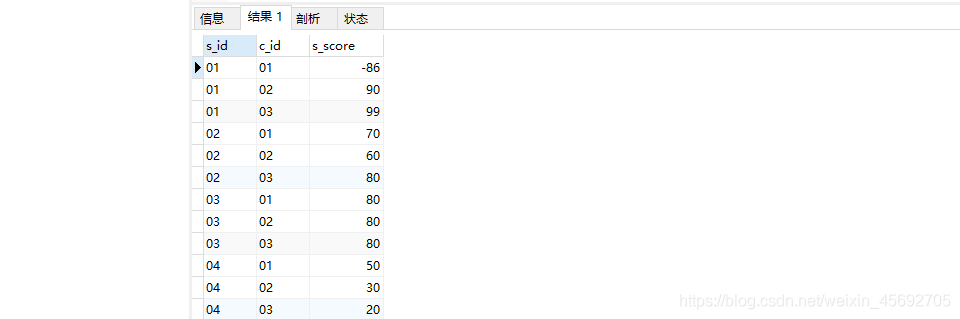
-- 学生表CREATE TABLE `student`(`s_id` VARCHAR(20),`s_name` VARCHAR(20) NOT NULL DEFAULT "",`s_birth` VARCHAR(20) NOT NULL DEFAULT "",`s_sex` VARCHAR(10) NOT NULL DEFAULT "",PRIMARY KEY(`s_id`));-- 课程表CREATE TABLE `course`(`c_id` VARCHAR(20),`c_name` VARCHAR(20) NOT NULL DEFAULT "",`t_id` VARCHAR(20) NOT NULL,PRIMARY KEY(`c_id`));-- 教师表CREATE TABLE `teacher`(`t_id` VARCHAR(20),`t_name` VARCHAR(20) NOT NULL DEFAULT "",PRIMARY KEY(`t_id`));-- 成绩表CREATE TABLE `score`(`s_id` VARCHAR(20),`c_id` VARCHAR(20),`s_score` INT(3),PRIMARY KEY(`s_id`,`c_id`));-- 插入学生表测试数据insert into student values("01" , "赵信" , "1990-01-01" , "男");insert into student values("02" , "德莱厄斯" , "1990-12-21" , "男");insert into student values("03" , "艾希" , "1990-05-20" , "男");insert into student values("04" , "德莱文" , "1990-08-06" , "男");insert into student values("05" , "俄洛依" , "1991-12-01" , "女");insert into student values("06" , "光辉女郎" , "1992-03-01" , "女");insert into student values("07" , "崔丝塔娜" , "1989-07-01" , "女");insert into student values("08" , "安妮" , "1990-01-20" , "女");-- 课程表测试数据insert into course values("01" , "语文" , "02");insert into course values("02" , "数学" , "01");insert into course values("03" , "英语" , "03");-- 教师表测试数据insert into teacher values("01" , "死亡歌颂者");insert into teacher values("02" , "流浪法师");insert into teacher values("03" , "邪恶小法师");-- 成绩表测试数据insert into score values("01" , "01" , 80);insert into score values("01" , "02" , 90);insert into score values("01" , "03" , 99);insert into score values("02" , "01" , 70);insert into score values("02" , "02" , 60);insert into score values("02" , "03" , 80);insert into score values("03" , "01" , 80);insert into score values("03" , "02" , 80);insert into score values("03" , "03" , 80);insert into score values("04" , "01" , 50);insert into score values("04" , "02" , 30);insert into score values("04" , "03" , 20);insert into score values("05" , "01" , 76);insert into score values("05" , "02" , 87);insert into score values("06" , "01" , 31);insert into score values("06" , "03" , 34);insert into score values("07" , "02" , 89);insert into score values("07" , "03" , 98);表结构 这里建的表主要用于sql语句的练习,所以并没有遵守一些规范。下面让我们来看看相关的表结构吧
学生表(student)

s_id = 学生编号,s_name = 学生姓名,s_birth = 出生年月,s_sex = 学生性别
课程表(course)

c_id =
相关文章:

 网公网安备
网公网安备