MySQL中建表时可空(NULL)和非空(NOT NULL)的用法详解
对于MySQL的一些个规范,某些公司建表规范中有一项要求是所有字段非空,意味着没有值的时候存储一个默认值。其实所有字段非空这么说应该是绝对了,应该说是尽可能非空,某些情况下不可能给出一个默认值。那么这条要求,是基于哪些考虑因素,存储空间?相关增删查改操作的性能?亦或是其他考虑?该理论到底有没有道理或者可行性,本文就个人的理解,做一个粗浅的分析。
1,基于存储的考虑
这里对存储的分析要清楚MySQL数据行的存储格式,这里直接从这篇文章白嫖一部分结论,文章里分析的非常清楚(其实也是参考《MySQL技术内容Innodb存储引擎》)。对于默认的Dynamic或者Compact格式的数据行结构,其行结构格式如下:|变长字段长度列表(1~2字节)|NULL标志位(1字节)|记录头信息(5字节)|RowID(6字节)|事务ID(6字节)|回滚指针(7字节)|row content
1,对于变长字段,当相关的字段值为NULL时,相关字段不会占用存储空间。NULL值没有存储,不占空间,但是需要一个标志位(一行一个)。2,对于变长字段,相关字段要求NOT NULL,存储成’’的时候,也不占用空间,如果一个表中所有的字典都NOT NULL,行头不需要NULL的标志位3,所有字段都是定长,不管是否要求为NOT NULL,都不需要标志位,同时不需要存储变长列长度
鉴于null值和非空(not null default ’’)两种情况,如果一个字段存储的内容是空,也就是什么都没有,前者存储为null,后者存储为空字符串’’,两者字段内容本身存储空间大小是一样的。但是如果一个表中存储在可空字段的情况下,其对应的数据行的头部,都需要一个1字节的NULL标志位,这个就决定了存储同样的数据,如果允许为null,相比not null的情况下,每行多了一个字节的存储空间的。这个因素或者就是某些公司或者个人坚持“所有表禁止null字段”这个信仰的原因之一(个人持否定态度,可以尝试将数据库中所有的字段都至为not null 然后default一个值后会不会鸡飞狗跳)。这里不再去做“微观”的分析,直接从“宏观”的角度来看一下差异。
测试demo
直接创建结构一致,但是一个表字段not null,一个表字段为null,然后使用存储此过程,两张表同时按照null值与非null值1:10的比例写入数据,也就是说每10行数据中1行数据字段为null的方式写入600W行数据。
CREATE TABLE a( id INT AUTO_INCREMENT, c2 VARCHAR(50) NOT NULL DEFAULT ’’, c3 VARCHAR(50) NOT NULL DEFAULT ’’, PRIMARY KEY (id));CREATE TABLE b( id INT AUTO_INCREMENT, c2 VARCHAR(50), c3 VARCHAR(50), PRIMARY KEY (id));CREATE DEFINER=`root`@`%` PROCEDURE `create_test_data`( IN `loop_cnt` INT)LANGUAGE SQLNOT DETERMINISTICCONTAINS SQLSQL SECURITY DEFINERCOMMENT ’’BEGIN DECLARE v2 , v3 VARCHAR(36); START TRANSACTION; while loop_cnt>0 do SET v2 = UUID(); SET v3 = UUID(); if (loop_cnt MOD 10) = 0 then INSERT INTO a (c2,c3) VALUES(DEFAULT,DEFAULT); INSERT INTO b (c2,c3) VALUES(DEFAULT,DEFAULT); else INSERT INTO a (c2,c3) VALUES (v2,v3); INSERT INTO b (c2,c3) VALUES (v2,v3); END if ; SET loop_cnt=loop_cnt-1; END while; COMMIT;
a,b两张表生产完全一致的数据。
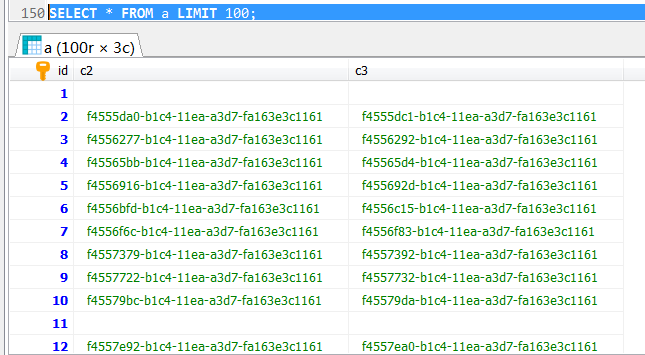
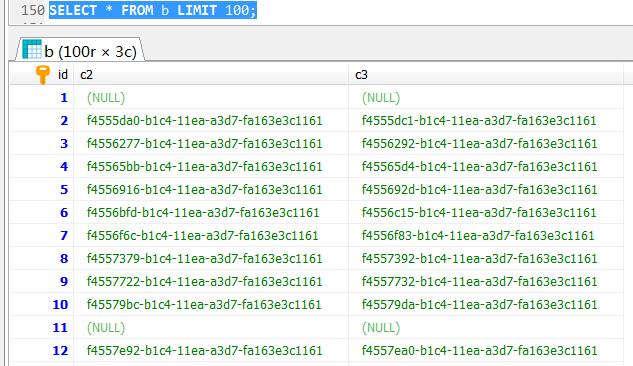
查看占用的存储空间情况,从information_schema.TABLES中查询这两个表的存储信息

1,一个字节的差别,体现在avg_row_length,a表因为所有的字段都是not null,因此相比b表,每行节省了每行节省了一个字节的存储2,总得空间的差别:a表662683648/1024/1024=631.98437500MB,b表666877952/1024/1024=635.98437500MB, 也当前情况下,600W行数据有4MB的差异,差异在1%之内,其实实际情况下,字段多,table size更大的的时候,这个差异会远远小于1%。
就存储空间来说,你跟我说1T的数据库你在乎1GB的存储空间,随便一点数据/索引碎片空间,一点预留空间,垃圾文件空间,无用索引空间……,都远远大于可为空带来的额外这一点差异。
2,增删查改的效率
读写操作对比,通过连续读写一个范围之内的数据,来对比a,b两张表在读上面的情况。2.1.)首先buffer pool是远大于table size的,因此不用担心物理IO引起的差异,目前两张表的数据完全都存在与buffer pool中。2.1.)读测试操作放在MySQL实例机器上,因此网络不稳定引起的差异可以忽略。
增删查改的差异与存储空间的差异类似,甚至更小,因为单行相差1个字节,放大到600W+才能看到一个5MB级别的差异,增删查改的话,各种测试下来,没有发现有明显的差异
#!/usr/bin/env python3import pymysqlimport timemysql_conn_conf = {’host’: ’127.0.0.1’, ’port’: 3306, ’user’: ’root’, ’password’: ’******’, ’db’: ’db01’}def mysql_read(table_name): conn = pymysql.connect(host=mysql_conn_conf[’host’], port=mysql_conn_conf[’port’], database=mysql_conn_conf[’db’],user=mysql_conn_conf[’user’],password = mysql_conn_conf[’password’]) cursor = conn.cursor() try: cursor.execute(’’’ select id,c2,c3 from {0} where id>3888888 and id<3889999;’’’.format(table_name)) row = cursor.fetchall() except pymysql.Error as e: print('mysql execute error:', e) cursor.close() conn.close()def mysql_write(loop,table_name): conn = pymysql.connect(host=mysql_conn_conf[’host’], port=mysql_conn_conf[’port’], database=mysql_conn_conf[’db’],user=mysql_conn_conf[’user’],password = mysql_conn_conf[’password’]) cursor = conn.cursor() try: if loop%10 == 0: cursor.execute(’’’ insert into {0}} (c2,c3) values(DEFAULT,DEFAULT)’’’.format(table_name)) else: cursor.execute(’’’ insert into {1}} (c2,c3) values(uuid(),uuid())’’’.format(table_name)) except pymysql.Error as e: print('mysql execute error:', e) cursor.close() conn.commit() conn.close()if __name__ == ’__main__’: time_start = time.time() loop=10 while loop>0: mysql_write(loop) loop = loop-1 time_end = time.time() time_c= time_end - time_start print(’time cost’, time_c, ’s’)
3,相关字段上的语义解析和逻辑考虑
这一点就观点差异就太多了,也是最容易引起口水或者争议的了。
1,对于字符类型,NULL就是不存在,‘’就是空,不存在和空本身就不是一回事,不太认同一定要NOT NULL,然后给出默认值。2,对于字符类型,任何数据库中,NULL都是不等于NULL的,因为在处理相关字段上进行join或者where筛选的时候,是不需要考虑连接双方都为NULL的情况的,一旦用’’替代了NULL,’’是等于’’的,此时就会出现与存储NULL完全不用的语义3,对于字符类型,一旦将相关字段default成’’,如何区分’’与空字符串,比如备注字段,不允许为NULL,default成‘’,那么怎么区分,NULL表达的空和默认值的空字符串’’4,对于相关的查询操作,如果允许为NULL,筛选非NULL值就是where *** is not null,语义上很清晰直观,一旦用字段非空,默认成’’,会使用where *** <>’’这种看起来超级恶心的写法,究竟要表达什么,语义上就已经开始模糊了5,对于时间类型,绝大多数时候是不允许有默认值的,默认多少合适,当前时间合适么,千禧年2000合适么,2008年北京奥运会开幕时间合适么?6,对于数值类型,比如int,比如decimal,在可空的情况下,如果禁止为NULL,默认给多少合适,0合适吗?-1合适吗?-9999999……合适吗?10086合适吗?1024合适吗?说实话,默认多少都不合适,NULL自身就是最合适的。
个人观点很明确,除非有特殊的需求要求一个字段绝对不能出现NULL值的情况,正常情况下,该NULL就NULL。如果NULL没有存在的意义,干脆数据库就不要存在这个NULL就好了,事实上,哪个数据库没有NULL类型?当然也不排除,某些DBA为了显得自己专业,弄出来一些莫须有的东西,现在就是有一种风气,在数据库上能提出来的限制条件越多,越有优越感。
想起来一个有关于默认值有意思的事,B站看视频的时候某up主曾提到过,因为B站把注册用户默认为男,出生日期某认为某个指定的日期,导致该up主在对用户点为分析后得到一些无法理解的数据。
个人认识有限,数据实话,非常想知道“所有字段非空”会带来什么其他哪些正面的影响,以及如何衡量这个正面的因素,还有,你们真的做到了,可以禁止整个实例下所有的库表中的字段禁止可空(nullable)?
到此这篇关于MySQL中建表时可空(NULL)和非空(NOT NULL)的用法详解的文章就介绍到这了,更多相关MySQL中建表时可空和非空 内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
 网公网安备
网公网安备