MYSQL 性能分析器 EXPLAIN 用法实例分析
本文实例讲述了MYSQL 性能分析器 EXPLAIN 用法。分享给大家供大家参考,具体如下:
使用方法:
EXPLAIN SELECT * FROM user;
环境和数据准备
-- 查看 MySQL 版本SELECT VERSION(); -- MySQL 提供什么存储引擎SHOW ENGINES; -- 查看默认存储引擎SHOW VARIABLES LIKE ’%storage_engine%’;
输出结果:

id:输出的是整数,用来标识整个 SQL 的执行顺序。id 如果相同,从上往下依次执行id不同;id 值越大,执行优先级越高,越先被执行;如果行引用其他行的并集结果,则该值可以为NULL
select_type:[查询类型]SIMPLE:简单的 SELECT 查询,没有 UNION 或者子查询,包括单表查询或者多表 JOIN 查询
PRIMARY: 最外层的 select 查询,常见于子查询或 UNION 查询 ,最外层的查询被标识为 PRIMARY
UNION:UNION 操作的第二个或之后的 SELECT,不依赖于外部查询的结果集(外部查询指的就是 PRIMARY 对应的 SELECT)
DEPENDENT UNION:UNION 操作的第二个或之后的 SELECT,依赖于外部查询的结果集
UNION RESULT:UNION 的结果(如果是 UNION ALL 则无此结果)
SUBQUERY:子查询中的第一个 SELECT 查询,不依赖于外部查询的结果集
DEPENDENT SUBQUERY:子查询中的第一个select查询,依赖于外部查询的结
DERIVED:派生表(临时表),常见于 FROM 子句中有子查询的情况
注意:MySQL5.7 中对 Derived table 做了一个新特性,该特性允许将符合条件的 Derived table 中的子表与父查询的表合并进行直接JOIN,从而简化简化了执行计划,同时也提高了执行效率;默认情况下,MySQL5.7 中这个特性是开启的,所以默认情况下,上面的 SQL 的执行计划应该是这样的
MATERIALIZED:被物化的子查询,MySQL5.6 引入的一种新的 select_type,主要是优化 FROM 或 IN 子句中的子查询,更多详情请查看:Optimizing Subqueries with Materialization
UNCACHEABLE SUBQUERY:对于外层的主表,子查询不可被缓存,每次都需要计算
UNCACHEABLE UNION:类似于 UNCACHEABLE SUBQUERY,只是出现在 UNION 操作中
SIMPLLE、PRIMARY、SUBQUERY、DERIVED 这 4 个在实际工作中碰到的会比较多,看得懂这 4 个就行了,至于其他的,碰到了再去查资料就好了
table:显示了对应行正在访问哪个表(有别名就显示别名),还会有 <union2,3> 、 <subquery2> 、 <derived2> (这里的 2,3、2、2 指的是 id 列的值)类似的值
partitions:查询进行匹配的分区,对于非分区表,该值为NULL。大多数情况下用不到分区,所以这一列我们无需关注
type:关联类型或者访问类型,它指明了 MySQL 决定如何查找表中符合条件的行,这是我们判断查询是否高效的重要依据,完整介绍请看:explain-join-types
system:该表只有一行(=系统表),是 const 类型的特例
const:确定只有一行匹配的时候,mysql 优化器会在查询前读取它并且只读取一次,速度非常快。用于 primary key 或 unique 索引中有常亮值比较的情形
eq_ref:对于每个来自于前面的表的行,从该表最多只返回一条符合条件的记录。当连接使用的索引是 PRIMARY KEY 或 UNIQUE NOT NULL 索引时使用,非常高效
ref:索引访问,也称索引查找,它返回所有匹配某个单个值的行。此类型通常出现在多表的 JOIN 查询, 针对于非 UNIQUE 或非 PRIMARY KEY, 或者是使用了最左前缀规则索引的查询,换句话说,如果 JOIN 不能基于关键字选择单个行的话,则使用ref
fulltext:当使用全文索引时会用到,这种索引一般用不到,会用专门的搜索服务(solr、elasticsearch等)来替代
ref_or_null:类似ref,但是添加了可以专门搜索 NULL 的行
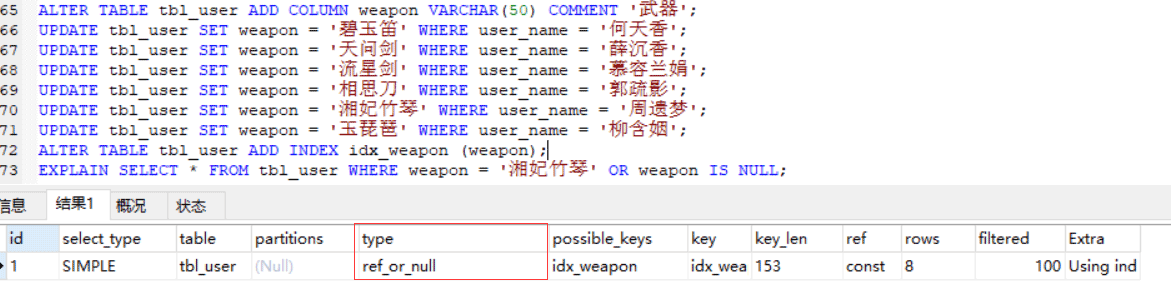
这个是有前提条件的,前提为 weapon 列有索引,且 weapon 列存在 NULL
index_merge:该访问类型使用了索引合并优化方法

这个同样也是有条件的, id 列和 weapon 列都有单列索引。如果出现 index_merge,并且这类 SQL 后期使用较频繁,可以考虑把单列索引换为组合索引,这样效率更高
unique_subquery:类似于两表连接中被驱动表的 eq_ref 访问方式,unique_subquery 是针对在一些包含 IN 子查询的查询语句中,如果查询优化器决定将 IN 子查询转换为 EXISTS 子查询,而且子查询可以使用到主键或者唯一索引进行等值匹配时,则会使用 unique_subquery
index_subquery:index_subquery 与 unique_subquery类似,只不过访问子查询中的表时使用的是普通的索引
range:使用索引来检索给定范围的行,当使用 =、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN 或者 IN 操作符,用常量比较关键字列时,则会使用 rang,前提是必须基于索引,也就是 id 上必须有索引
index:当我们可以使用索引覆盖,但需要扫描全部的索引记录时,则会使用 index;进行统计时非常常见
ALL:我们熟悉的全表扫描
possible_keys:展示在这个 SQL 中,可能用到的索引有哪些,但不一定在查询时使用。若为空则表示没有可以使用的索引,此时可以通过检查 WHERE 语句看是否可以引用某些列或者新建索引来提高性能
key:展示这个 SQL 实际使用的索引,如果没有选择索引,则此列为null,要想强制 MySQL 使用或忽视 possible_keys 列中的索引,在查询中使用 FORCE INDEX、USE INDEX 或者I GNORE INDEX
key_len:展示 MySQL 决定使用的键长度(字节数)。如果 key 是 NULL,则长度为 NULL。在不损失精确性的情况下,长度越短越好
ref:展示的是与索引列作等值匹配的东东是个啥,比如只是一个常数或者是某个列。它显示的列的名字(或const),此列多数时候为 Null
rows:展示的是 mysql 解析器认为执行此 SQL 时预计需要扫描的行数。此数值为一个预估值,不是具体值,通常比实际值小
filtered:展示的是返回结果的行数所占需要读到的行(rows 的值)的比例,当然是越小越好啦
extra:表示不在其他列但也很重要的额外信息。取值有很多,我们挑一些比较常见的过一下
using index:表示 SQL 使用了使用覆盖索引,而不用回表去查询数据,性能非常不错
using where:表示存储引擎搜到记录后进行了后过滤(POST-FILTER),如果查询未能使用索引,using where 的作用只是提醒我们 mysql 要用 where 条件过滤结果集
using temporary:表示 mysql 需要使用临时表来存储结果集,常见于排序和分组查询
using filesort:表示 mysql 无法利用索引直接完成排序(排序的字段不是索引字段),此时会用到缓冲空间(内存或者磁盘)来进行排序;一般出现该值,则表示 SQL 要进行优化了,它对 CPU 的消耗是比较大的
impossible where:查询语句的WHERE子句永远为 FALSE 时将会提示该额外信息
当然还有其他的,不常见,等碰到了大家再去查吧!!!
更多关于MySQL相关内容感兴趣的读者可查看本站专题:《MySQL查询技巧大全》、《MySQL事务操作技巧汇总》、《MySQL存储过程技巧大全》、《MySQL数据库锁相关技巧汇总》及《MySQL常用函数大汇总》
希望本文所述对大家MySQL数据库计有所帮助。
相关文章:

 网公网安备
网公网安备