Mybatis常见注解有哪些(总结)
当下,注解非常流行,以前很长篇的代码,现在基本上一个注解就能搞定。
那,在Mybatis中又有哪些注解呢?
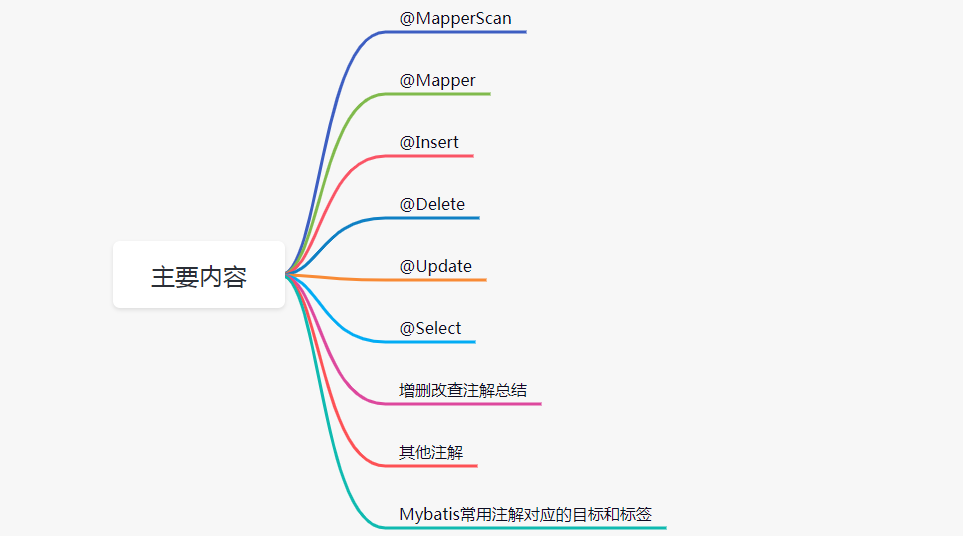
Mybatis中的注解基本上都在org.apache.ibatis.annotations目录下:
该注解存在着争议,但不可否认的是这个注解确实是Mybatis的注解,是为了集成Spring而写的注解。该注解主要是扫描某个包目录下的Mapper,将Mapper接口类交给Spring进行管理。
org.mybatis.spring.annotation.MapperScan使用方式
@SpringBootApplication@MapperScan('com.tian.mybatis.mapper')public class Application {}
其实,从名字上就能看出,是用来扫描的Mapper的。
扫描包路径可以是一个或者多个,也可以在路径中可以使用 * 作为通配符对包名进行匹配 。
@SpringBootApplication@MapperScan('com.tian.*.mapper')public class Application {}@SpringBootApplication@MapperScan({'com.tian.mybatis.mapper','com.tian.mybatis.mapper1'})public class Application {}
灵活度相当高,这样在实际上项目中,我们就可以指定扫描想要被扫描的包路径。
@Mapper该注解目的就是为了不再写mapper映射文件 (UserMapper.xml)。可以大大的简化编写xml的繁琐。该注解是由Mybatis框架中定义的一个描述数据层接口的注解,注解往往起到的都是一个描述性作用,用于告诉Spring框架此接口的实现类由Mybatis负责创建,并将其实现类对象存储到spring容器中。
使用方式@Mapperpublic interface UserMapper { User selectById(Integer id); }@Insert
插入记录的时候主键如何生成?对此基本上有三种方案,分别是:手动指定(应用层)、自增主键(数据层单表)、选择主键(数据层多表)。
对应xml文件中的<insert>标签。
在应用层手动指定主键手动指定的方式不把主键区别看待,插入之前在应用层生成对象的时候就会给主键一个值,插入的时候与普通字段没啥区别。
/*** 插入记录,手动分配主键 */@Insert('INSERT INTO t_user (id, username, passwd) VALUES (#{id}, #{username}, #{passwd})')int addUserAssignKey(User user);
在上面的这个例子中,mybatis并不知道到底哪个字段是主键,id虽然是主键字段,但并没有被区别对待。
「注意」
#{username}这种写法,是把User作为了当前上下文,这样访问User的属性的时候直接写属性名字就可以了。
表自增主键自增主键对应着XML配置中的主键回填,一个简单的例子:
/*** 插入记录,数据库生成主键 */@Options(useGeneratedKeys = true, keyProperty = 'id')@Insert('INSERT INTO t_user (username, passwd) VALUES (#{username}, #{passwd})')int addUserGeneratedKey(User user);
使用Option来对应着XML设置的select标签的属性,userGeneratordKeys表示要使用自增主键,keyProperty用来指定主键字段的字段名。自增主键会使用数据库底层的自增特性。
选择主键选择主键从数据层生成一个值,并用这个值作为主键的值。
/** * 插入记录,选择主键 */@Insert('INSERT INTO t_user (username, passwd) VALUES (#{username}, #{passwd})')@SelectKey(statement = 'SELECT UNIX_TIMESTAMP(NOW())', keyColumn = 'id', keyProperty = 'id', resultType = Long.class, before = true)int addUserSelectKey(User user);@Delete
删除的时候只要把语句条件神马的写在@Delete注解的value里就好了,返回一个int类型是被成功删除的记录数。对应xml文件中的<delete>标签。
/** * 删除记录 */@Delete('DELETE FROM t_user WHERE id=#{id}')int delete(Long id);@Update
修改的时候和删除一样只要把SQL语句写在@Update的value中就好了,返回一个int类型表示被修改的记录行数。
对应xml文件中的<update>标签。
/** * 修改记录 */@Update('UPDATE t_user SET username=#{username}, passwd=#{passwd} WHERE id=#{id}')int update(User user);@Select
查询的时候稍稍有些复杂,因为查询会涉及到如何将查出来的字段设置到对象上,对应xml文件中的<select>标签。
通常有那么三种办法:
在SQL语句中手动指定别名来匹配在写SQL语句的时候,手动为每一个字段指定一个别名来跟对象的属性做匹配,适用于表字段名与对象属性名差异很大没有规律并且表字段不多的情况。
/** * 根据ID查询,手动设置别名 */@Select('SELECT id, username, passwd, birth_day AS birthDay FROM t_user WHERE id=#{id}')User loadByIdHandAlias(Long id);使用mybatis的自动下划线驼峰转换
mybatis有一个选项叫mapUnderscoreToCamelCase,当表中的字段名与对象的属性名相同只是下划线和驼峰写法的差异时适用。
配置了mapUnderscoreToCamelCase之后mybatis在将ResultSet查出的数据设置到对象的时候会尝试先将下划线转换为驼峰然后前面拼接set去设置属性。
开启转换:

然后查询
/** * 根据ID查询,开了自动驼峰转换 */@Select('SELECT * FROM t_user WHERE id=#{id}')User loadByIdAutoAlias(Long id);
查看打印的结果,birth_day属性填充到了对象中:

对于表的字段名和对象的属性名没有太大相同点并且表中的字段挺多的情况下,应该使用ResultMap做适配。
/** * 使用ResultMap */@Results(id = 'userMap', value = { //可以使用这种方式来处理字段名和数据库表字段名不一致的情况 @Result(id=true, column = 'id', property = 'id'), @Result(column = 'username', property = 'username'), @Result(column = 'passwd', property = 'passwd'), @Result(column = 'birth_day', property = 'birthDay')})@Select('SELECT * FROM t_user WHERE id=#{id}')User loadByIdResultMap(Long id);
@Results对应着XML中的ResultMap,同时可以为其指定一个id,其它地方可以使用这个id来引用它,比如要引用上面的这个Results:
/** * 引用其他的Result */@ResultMap('userMap')@Select('SELECT * FROM t_user WHERE id=#{id}')User loadByIdResultMapReference(Long id);
使用@ResultMap来引用一个已经存在的ResultMap,这个ResultMap可以是在Java中使用@Results注解定义的,也可以是在XML中使用resultMap标签定义的。
增删改查注解总结
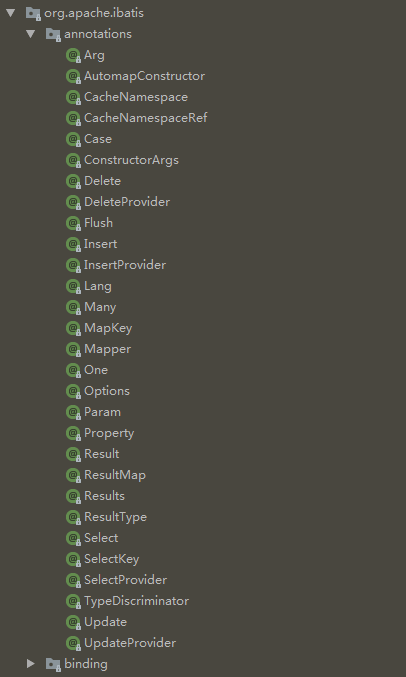
@Results:结果映射的列表, 包含了一个特别结果列如何被映射到属性或字段的详情。属 性:value, id。value 属性是 Result 注解的数组。对应xml中的<resultMap> 标签。
@Result:在列和属性或字段之间的单独结果映 射。属 性:id,column, property, javaType ,jdbcType ,type Handler, one,many。id 属性是一个布尔值,表 示了应该被用于比较(和在 XML 映射 中的相似)的属性。one 属性是单 独 的 联 系, 和 <association> 相 似 , 而 many 属 性 是 对 集 合 而 言 的 , 和 <collection>相似。它们这样命名是为了 避免名称冲突。类似于<resultMap>的子标签 <result>``<id>。
@One:复杂类型的单独属性值映射。属性: select,已映射语句(也就是映射器方 法)的完全限定名,它可以加载合适类 型的实例。注意:联合映射在注解 API 中是不支持的。这是因为 Java 注解的 限制,不允许循环引用。类似于<association>标签。
@Many:与@One类似,一对多的关系,类似于<collection>
@Param :参数标签,我们在Mapper的方法签名上标注的参数,我们可以指定参数名称,然后在注解中或者xml中的SQL里就可以使用我们自定义的参数名称。
@SelectKey :获取最新插入id。
@CacheNamespace :为给定的命名空间 (比如类) 配置缓存。对应xml中的<cache>。
@CacheNamespaceRef :参照另外一个命名空间的缓存来使用。属性:value,应该是一个名空间的字 符串值(也就是类的完全限定名) 。对应xml中的<cacheRef>标签。
@ConstructorArgs :收集一组结果传递给一个劫夺对象的 构造方法。属性:value,是形式参数 的数组。
@Arg :单 独 的 构 造 方 法 参 数 , 是 ConstructorArgs 集合的一部分。属性: id,column,javaType,typeHandler。id 属性是布尔值, 来标识用于比较的属 性,和XML 元素相似。对应xml中的<arg>标签。
@Case :单独实例的值和它对应的映射。属性: value,type,results。Results 属性是结 果数组,因此这个注解和实际的 ResultMap 很相似,由下面的 Results 注解指定。对应xml中标签<case>。
Mybatis常用注解对应的目标和标签
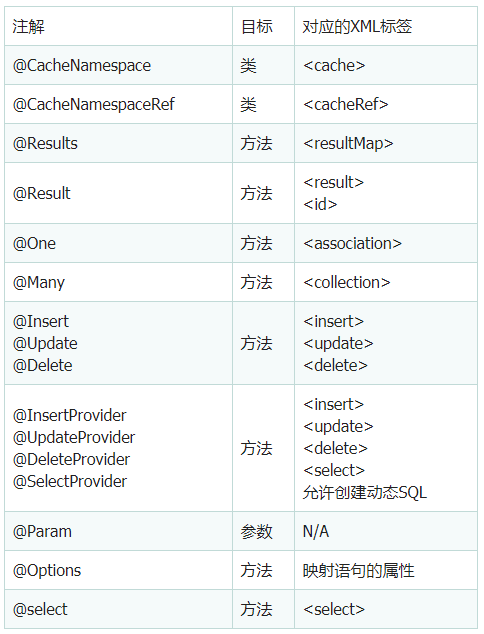
mybatis最初配置信息是基于 XML ,映射语句(SQL)也是定义在 XML 中的。而到了 MyBatis 3提供了新的基于注解的配置。mybatis提供的注解有很多,笔者进行了分类:
「增删改查:」@Insert、@Update、@Delete、@Select、@MapKey、@Options、@SelelctKey、@Param、@InsertProvider、@UpdateProvider、@DeleteProvider、@SelectProvider 「结果集映射:」@Results、@Result、@ResultMap、@ResultType、@ConstructorArgs、@Arg、@One、@Many、@TypeDiscriminator、@Case 「缓存:」@CacheNamespace、@Property、@CacheNamespaceRef、@Flush绝大部分注解,在xml映射文件中都有元素与之对应,但是不是所有。此外在mybatis-spring中提供了@Mapper注解和@MapperScan注解,用于和spring进行整合。
到此这篇关于Mybatis常见注解有哪些(总结)的文章就介绍到这了,更多相关Mybatis常见注解内容请搜索好吧啦网以前的文章或继续浏览下面的相关文章希望大家以后多多支持好吧啦网!
相关文章:
1. Mysql故障排除:Starting MySQL. ERROR! Manager of pid-file quit without updating file2. 快速解决mysql导数据时,格式不对、导入慢、丢数据的问题3. [Oracle] 书写历史的甲骨文――ORACLE公司传奇4. SQL Server修改数据的几种语句详解5. SQL Server还原完整备份和差异备份的操作过程6. SQLite数据库常用语句及MAC上的SQLite可视化工具MeasSQLlite使用方法7. Mybatis传入List实现批量更新的示例代码8. MySQL单表查询实例详解9. Microsoft Office Access删除表记录的方法10. MYSQL(电话号码,身份证)数据脱敏的实现
![[Oracle] 书写历史的甲骨文――ORACLE公司传奇](http://www.haobala.com/attached/image/11.jpg)
 网公网安备
网公网安备