浅谈Linux的零拷贝技术
前言
在Linux系统内部缓存和内存容量都是有限的,更多的数据都是存储在磁盘中。对于Web服务器来说,经常需要从磁盘中读取数据到内存,然后再通过网卡传输给用户:
那么这也算一次I O的过程,都知道IO过程中需要状态的切换还有一系列拷贝过程,都是要时间开销的,那么怎么优化用户态和内核态的状态的切换次数和各种缓冲区之间的拷贝次数,也是linux的服务器实现高并发的重要技术了!
传统数据交互
传统 io 的执行流程: 下面将图左半部分read过程的硬件抽象为磁盘; 图右半部分write过程的硬件设为网卡,模拟webserver进行一次IO的过程; 方便理解;
- read:将数据从 IO 设备读取到内核缓存区中,再将数据从内核缓冲区拷贝到用户缓冲区
- write:将数据从用户缓冲区写入到内核缓冲区中,再将数据从内核缓冲区拷贝到 IO 设备
read/write 属于系统调用 syscall,每一次系统调用 ,发生两次上下文切换
- 调用 syscall 从用户态切换到内核态
- syscall 返回从内核态切换到用户态
如图所示,传统 io 的过程中,发生了4次空间切换 + 4次拷贝
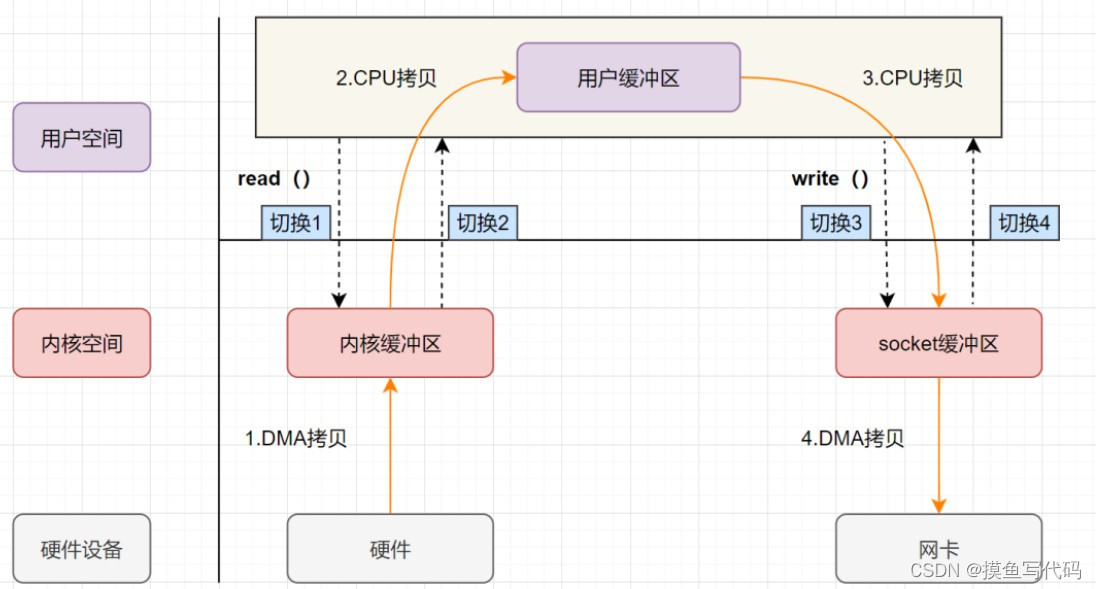
不难看出,传统模式下的IO,涉及多次空间切换和数据冗余拷贝,效率并不高。而零拷贝 Zero-Copy 目的就是降低冗余数据拷贝,解放 CPU
- 减少数据在内核缓冲区和用户缓冲区之间的冗余拷贝(CPU拷贝)
- 减少系统调用导致的空间切换
目前来看,零拷贝技术的实现手段主要包括:mmap+write、sendfile、sendfile+DMA、splice
零拷贝
首先解释一下,零拷贝中的0,指的是CPU级别的数据拷贝(比如内核缓冲区到用户缓冲区的拷贝,用户缓冲区再到socket缓冲区; 或者内核缓冲区直接到socket缓冲区的拷贝!),并不是DMA硬件的拷贝,否则数据不靠DMA怎么转移呢?
mmap+write
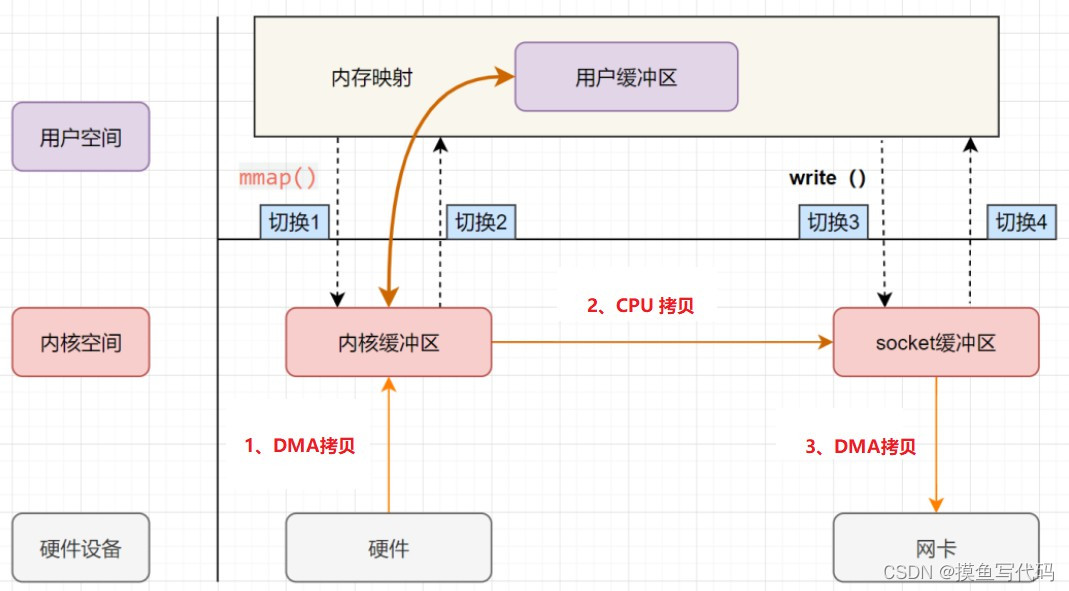
- 内存映射 memory mapping,mmap 是一种内存映射文件的方法,即将一个文件或者其他对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一映射关系。
mmap可以充当read的功能,将内核读缓冲区地址与用户缓冲区地址进行映射,实现内核缓冲区与用户缓冲区的共享。这样就减少了一次用户态和内核态的CPU拷贝。
mmap + write 流程如图所示,发生了4次切换 + 2次DMA拷贝 + 1次CPU拷贝
函数原型
#include <sys/mman.h>// 内存映射void* mmap(void* start, size_t length, int prot, int flags, int fd, off_t offset);/*参数start:指定映射的虚拟内存地址,通常定义为 NULL,由内核选定地址length:映射的长度prot:描述映射内存的访问权限PROT_EXEC页面可以被 cpu 执行指令组成,PROT_NONE 页面不能访问PROT_READ 页面可读,PROT_WRITE 页面可写,flags:指定映射的类型,MAP_SHARED共享对象,MAP_PRIVATE私有的,写时复制对象fd:要进行映射的文件句柄offset:文件偏移量*/// 解除映射int munmap(void *addr, size_t length);
例: 发送方:
// 建立内存映射char *pMap = (char*) mmap (NULL, fileInfo.st_size, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0); send(clientFd, pMap, fileInfo.st_size, 0);// 解除映射munmap(pMap, fileInfo.st_size);
接收方:
// 使用 mmap 前用使用 ftruncate 来扩大文件大小ftruncate(fd, fileSize);char *pMap = (char*) mmap (NULL, fileSize, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);recvCycle(sfd, pMap, fileSize);munmap(pMap, fileSize);
小结
mmap充当read的功能,进行一次完整的IO,减少了传统方式read数据的时候,从内核态CPU拷贝到用户态的这次拷贝; (发生了4次切换 + 2次DMA拷贝 + 1次CPU拷贝;)
mmap 存在的问题:mmap 对大文件传输有一定优势,但是小文件可能出现碎片,并且在多个进程同时操作文件时可能产生引发 coredump 的 signal。
sendfile
mmap+write 方式有一定改进,但是由系统调用引起的状态切换并没有减少,因此在 Linux 内核2.1版本中引入了 sendfile 系统调用。
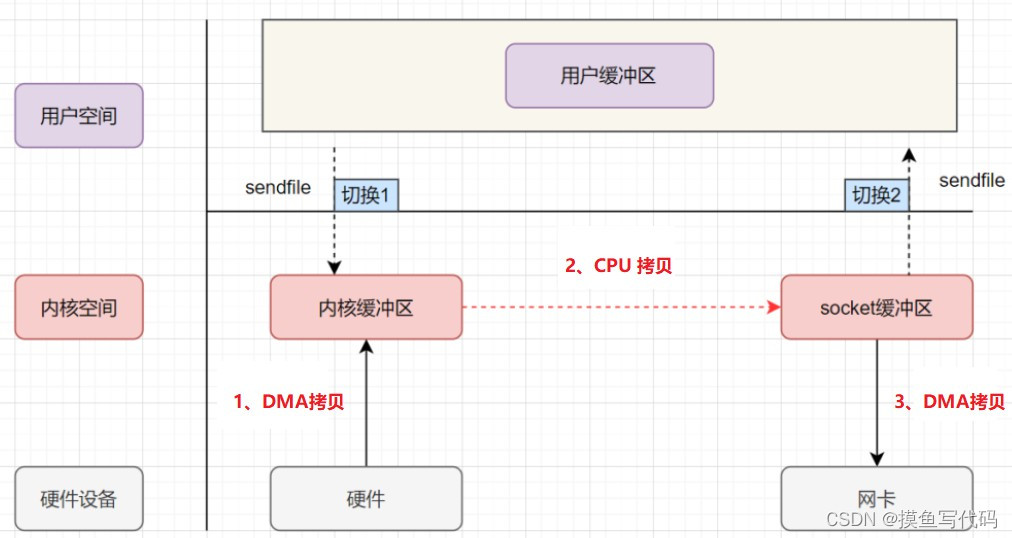
sendfile 在两个文件之间通过内核直接传输数据,避免了内核缓冲区和用户缓冲区之间的数据拷贝操作。sendfile 只能用于发送数据,不能用于接收数据。
sendfile 方式只使用一个函数就可以完成之前的 read+write 和 mmap+write 的功能,这样减少一个系统调用(2次状态切换),由于数据不经过用户缓冲区,因此该数据无法被修改。
sendfile 的流程如图所示, 发生了2次切换 + 2次DMA拷贝+1次CPU拷贝
sendfile + DMA
linux2.4版本后,对 sendfile 系统调用进行优化,配合硬件 DMA,可以直接从内核空间缓冲区中将数据拷贝到网卡,彻底省去了CPU拷贝。
如图所示,sendfile + DMA 的过程中发生了2次切换 + 2次DMA拷贝 + 0次CPU拷贝
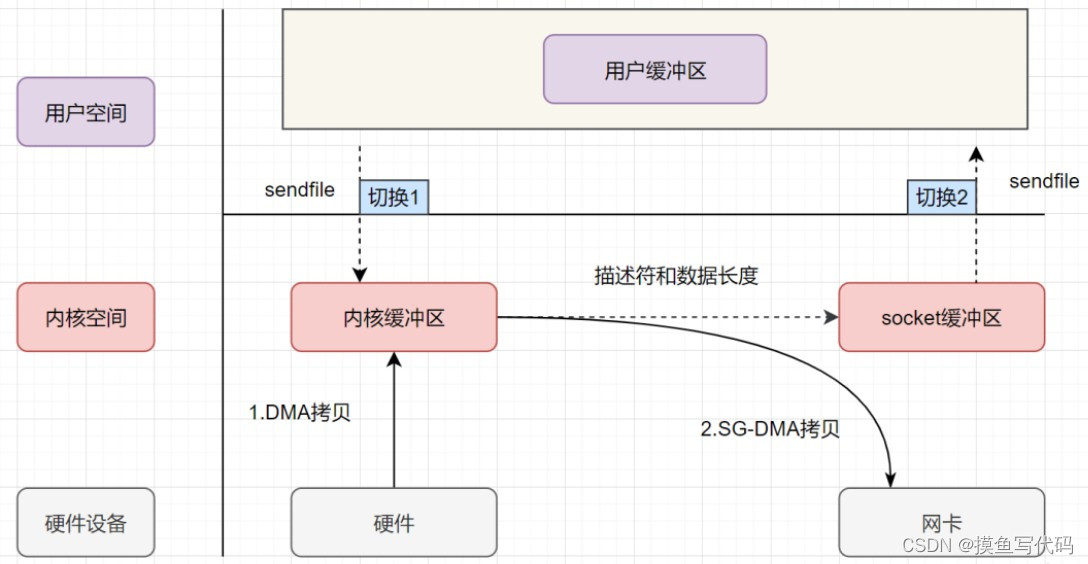
sendfile 函数原型
#include <sys/sendfile.h>ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);/*参数- out_fd:待写入内容的文件描述符- in_fd:待读出内容的文件描述符- offset:文件偏移量- count:传输的字节数*/
例:
发送方
sendfile(clientFd, fd, 0, fileInfo.st_size);
小结
早期sendfile : 2次切换 (sendfile后,数据不用过用户层了,导致不能修改了,不过也少了两次状态切换!)+ 2次DMA拷贝(磁盘到内核,socket缓冲区到网卡)+ 1次CPU拷贝(内核到socket缓冲区)
改良的sendfile + DMA : 发生了2次切换 + 2次DMA拷贝(磁盘到内核,内核直接到网卡) + 0次CPU拷贝
sendfile 存在的问题:无法对数据进行修改(数据没上到用户层,也没必要,webserver一般都不需要修改,返回的本地的资源!),并且需要硬件层面DMA的支持,并且 sendfile 只能将文件数据拷贝到 socketfd,有一定的局限性。
splice
splice 系统调用在 Linux 2.6 版本引入,不需要硬件支持,并且不再限定于 socket 上,实现了两个普通文件之间的零拷贝。
可以在内核缓冲区和 socket 缓冲区间建立管道来传输数据,避免了两者之间的 CPU 拷贝操作。
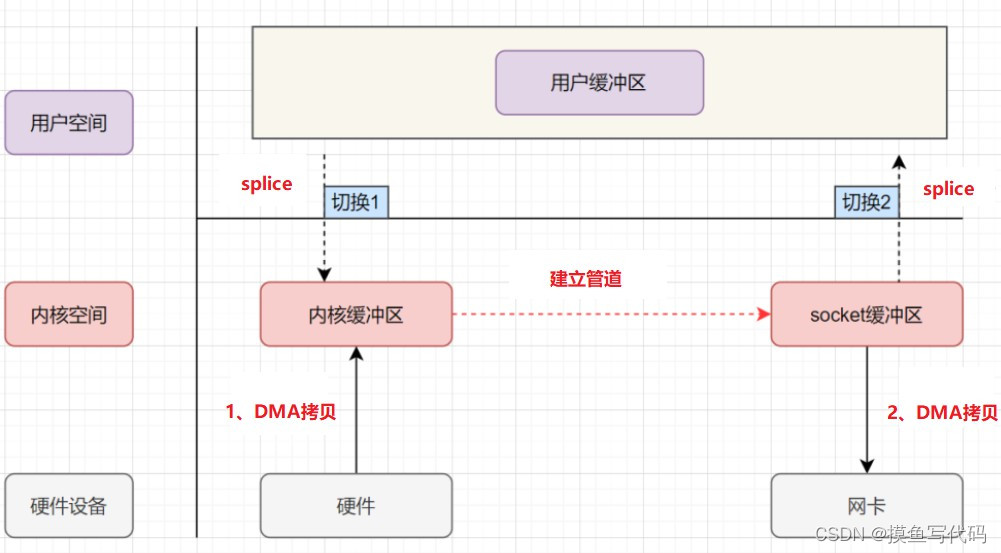
函数原型
#define _GNU_SOURCE #include <fcntl.h>ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);/*返回值;成功返回接收到的字节数,失败-1参数- fd_in:待输入数据的文件描述符。- off_in: 输入流偏移量。若 fd_in 是管道文件描述符,则设置为 NULL,表示从当前偏移读入。 否则,off_in 表示从输入数据流的某处开始读取。- fd_out:待输出数据的文件描述符。- off_out:输出流偏移量,同上。- len:单次写入的数据长度,最多65536- flags:0*/
例:web服务器端代码: transFile.c:
int fds[2];pipe(fds);int recvLen = 0;//当读到的数据量超过文件大小时,即已经读取数据完成while(recvLen < fileInfo.st_size){ //将数据从服务器端本地读到管道 ret = splice(fd, 0, fds[1], 0, 65536, 0); //将数据从管道读到客户端 ret = splice(fds[0], 0, clientFd, 0, ret, 0); //计算已经读到的数据量 recvLen += ret;}小结
splice 引入管道机制,实现了普通文件之间的0拷贝,突破了仅限于socket的sendfile0拷贝;
splice 存在的问题:它的两个文件描述符中有一个必须是管道设备
到此这篇关于浅谈Linux的零拷贝技术的文章就介绍到这了,更多相关Linux零拷贝技术内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
 网公网安备
网公网安备